 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024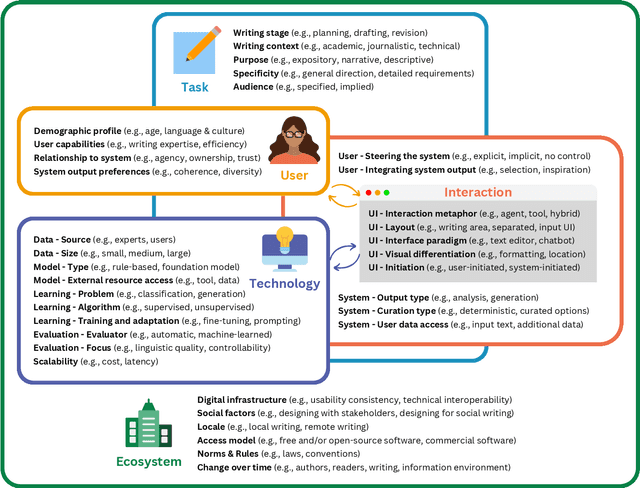
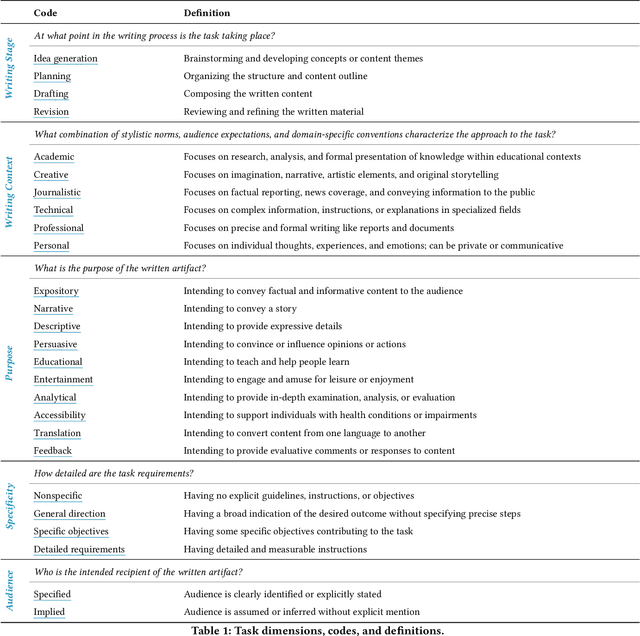
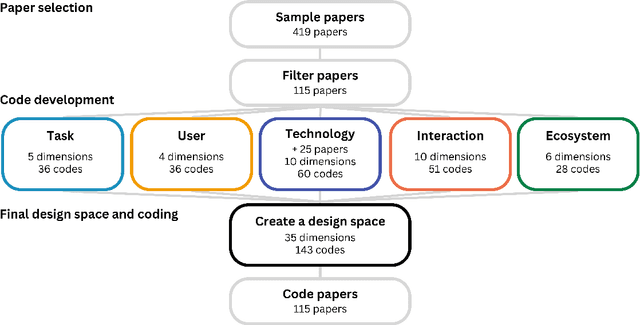
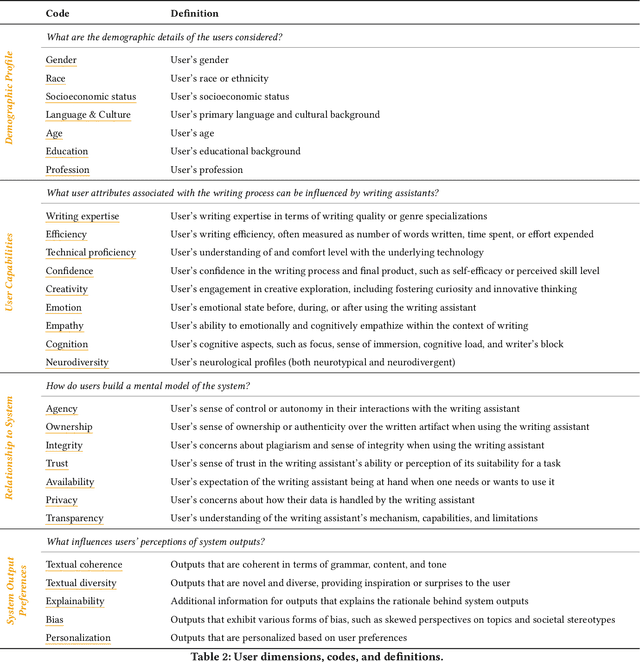
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
Approach Intelligent Writing Assistants Usability with Seven Stages of Action
Apr 06, 2023Despite the potential of Large Language Models (LLMs) as writing assistants, they are plagued by issues like coherence and fluency of the model output, trustworthiness, ownership of the generated content, and predictability of model performance, thereby limiting their usability. In this position paper, we propose to adopt Norman's seven stages of action as a framework to approach the interaction design of intelligent writing assistants. We illustrate the framework's applicability to writing tasks by providing an example of software tutorial authoring. The paper also discusses the framework as a tool to synthesize research on the interaction design of LLM-based tools and presents examples of tools that support the stages of action. Finally, we briefly outline the potential of a framework for human-LLM interaction research.
Aspirations and Practice of Model Documentation: Moving the Needle with Nudging and Traceability
Apr 13, 2022
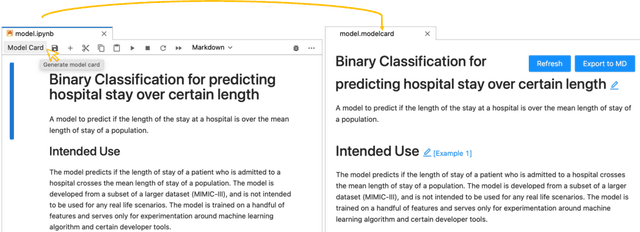


Machine learning models have been widely developed, released, and adopted in numerous applications. Meanwhile, the documentation practice for machine learning models often falls short of established practices for traditional software components, which impedes model accountability, inadvertently abets inappropriate or misuse of models, and may trigger negative social impact. Recently, model cards, a template for documenting machine learning models, have attracted notable attention, but their impact on the practice of model documentation is unclear. In this work, we examine publicly available model cards and other similar documentation. Our analysis reveals a substantial gap between the suggestions made in the original model card work and the content in actual documentation. Motivated by this observation and literature on fields such as software documentation, interaction design, and traceability, we further propose a set of design guidelines that aim to support the documentation practice for machine learning models including (1) the collocation of documentation environment with the coding environment, (2) nudging the consideration of model card sections during model development, and (3) documentation derived from and traced to the source. We designed a prototype tool named DocML following those guidelines to support model development in computational notebooks. A lab study reveals the benefit of our tool to shift the behavior of data scientists towards documentation quality and accountability.
Predictive Closed-Loop Service Automation in O-RAN based Network Slicing
Feb 04, 2022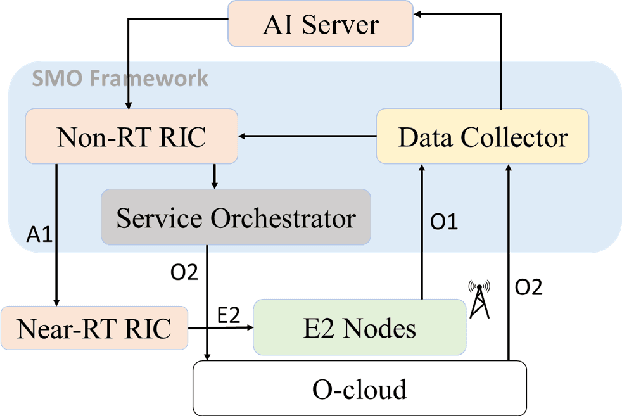
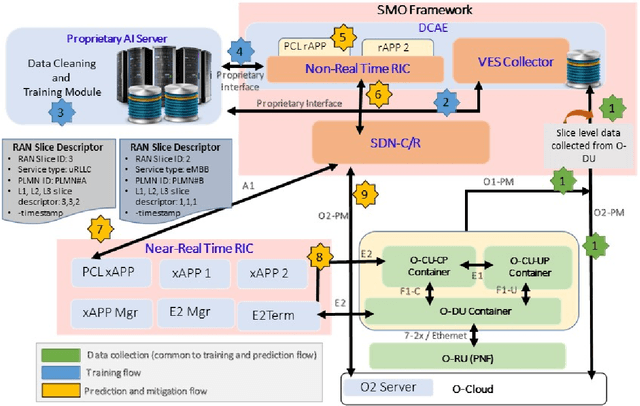
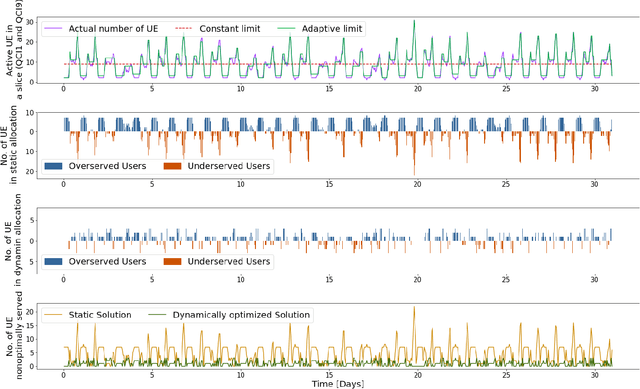
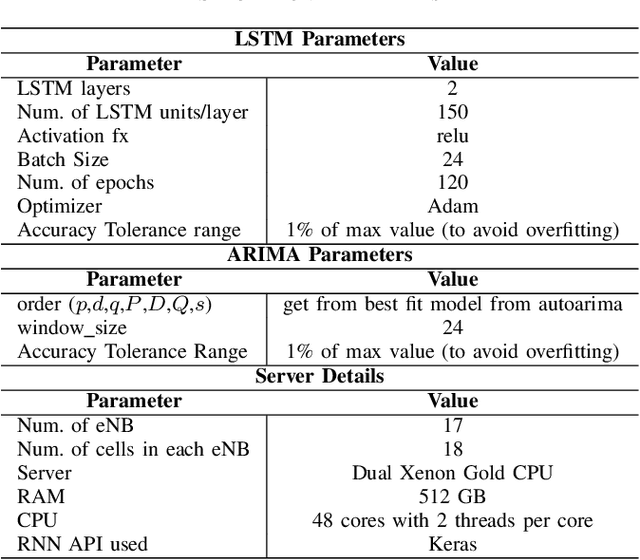
Network slicing provides introduces customized and agile network deployment for managing different service types for various verticals under the same infrastructure. To cater to the dynamic service requirements of these verticals and meet the required quality-of-service (QoS) mentioned in the service-level agreement (SLA), network slices need to be isolated through dedicated elements and resources. Additionally, allocated resources to these slices need to be continuously monitored and intelligently managed. This enables immediate detection and correction of any SLA violation to support automated service assurance in a closed-loop fashion. By reducing human intervention, intelligent and closed-loop resource management reduces the cost of offering flexible services. Resource management in a network shared among verticals (potentially administered by different providers), would be further facilitated through open and standardized interfaces. Open radio access network (O-RAN) is perhaps the most promising RAN architecture that inherits all the aforementioned features, namely intelligence, open and standard interfaces, and closed control loop. Inspired by this, in this article we provide a closed-loop and intelligent resource provisioning scheme for O-RAN slicing to prevent SLA violations. In order to maintain realism, a real-world dataset of a large operator is used to train a learning solution for optimizing resource utilization in the proposed closed-loop service automation process. Moreover, the deployment architecture and the corresponding flow that are cognizant of the O-RAN requirements are also discussed.