 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndian Legal Text Summarization: A Text Normalisation-based Approach
Jun 13, 2022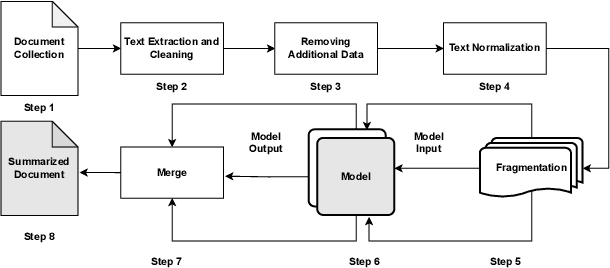
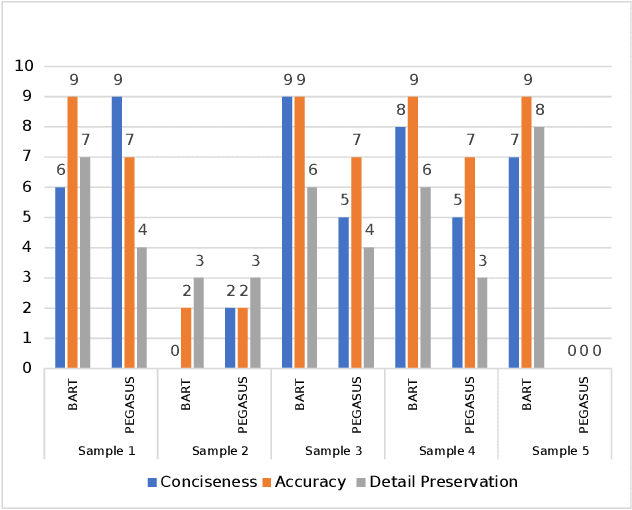
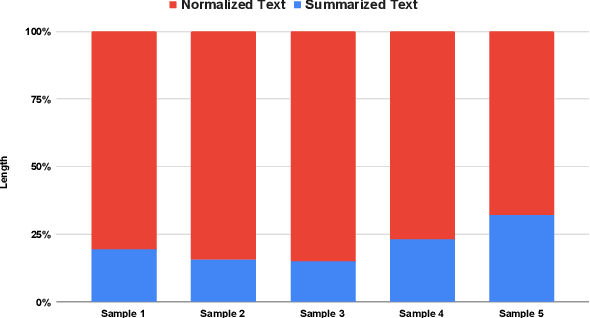

In the Indian court system, pending cases have long been a problem. There are more than 4 crore cases outstanding. Manually summarising hundreds of documents is a time-consuming and tedious task for legal stakeholders. Many state-of-the-art models for text summarization have emerged as machine learning has progressed. Domain-independent models don't do well with legal texts, and fine-tuning those models for the Indian Legal System is problematic due to a lack of publicly available datasets. To improve the performance of domain-independent models, the authors have proposed a methodology for normalising legal texts in the Indian context. The authors experimented with two state-of-the-art domain-independent models for legal text summarization, namely BART and PEGASUS. BART and PEGASUS are put through their paces in terms of extractive and abstractive summarization to understand the effectiveness of the text normalisation approach. Summarised texts are evaluated by domain experts on multiple parameters and using ROUGE metrics. It shows the proposed text normalisation approach is effective in legal texts with domain-independent models.
Plagiarism Detection in the Bengali Language: A Text Similarity-Based Approach
Mar 25, 2022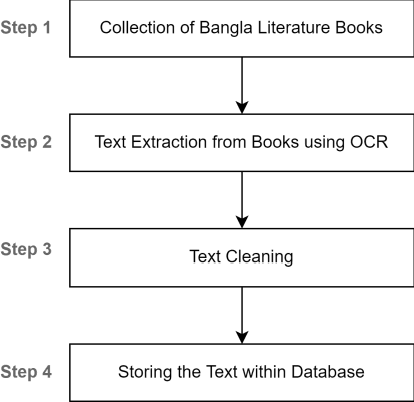


Plagiarism means taking another person's work and not giving any credit to them for it. Plagiarism is one of the most serious problems in academia and among researchers. Even though there are multiple tools available to detect plagiarism in a document but most of them are domain-specific and designed to work in English texts, but plagiarism is not limited to a single language only. Bengali is the most widely spoken language of Bangladesh and the second most spoken language in India with 300 million native speakers and 37 million second-language speakers. Plagiarism detection requires a large corpus for comparison. Bengali Literature has a history of 1300 years. Hence most Bengali Literature books are not yet digitalized properly. As there was no such corpus present for our purpose so we have collected Bengali Literature books from the National Digital Library of India and with a comprehensive methodology extracted texts from it and constructed our corpus. Our experimental results find out average accuracy between 72.10 % - 79.89 % in text extraction using OCR. Levenshtein Distance algorithm is used for determining Plagiarism. We have built a web application for end-user and successfully tested it for Plagiarism detection in Bengali texts. In future, we aim to construct a corpus with more books for more accurate detection.