 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAverage Gradient Outer Product in kernel regression provably recovers the central subspace for multi-index models
May 14, 2026We study a prototypical situation when a learned predictor can discover useful low-dimensional structure in data, while using fewer samples than are needed for accurate prediction. Specifically, we consider the problem of recovering a multi-index polynomial $f^*(x)=h(Ux)$, with $U\in\mathbb{R}^{r\times d}$ and $r\ll d$, from finitely many data/label pairs. Importantly, the target function depends on input $x$ only through the projection onto an unknown $r$-dimensional central subspace. The algorithm we analyze is appealingly simple: fit kernel ridge regression (KRR) to the data and compute the Average Gradient Outer Product (AGOP) from the fitted predictor. Our main results show that under reasonable assumptions the top $r$-dimensional eigenspace of AGOP provably recovers the central subspace, even in regimes when the prediction error remains large. Specifically, if the target function $f^*$ has degree $p^*$, it is known that $n\asymp d^{p^*}$ samples are necessary for KRR to achieve accurate prediction. In contrast, we show that if a low degree $p$ component of $f^*$ already carries all relevant directions for prediction, subspace recovery occurs in the much lower sample regime $n\asymp d^{p+δ}$ for any $δ\in(0,1)$. Our results thus demonstrate a separation between prediction and representation, and provide an explanation for why iterative kernel methods such as Recursive Feature Machines (RFM) can be sample-efficient in practice.
A short proof of near-linear convergence of adaptive gradient descent under fourth-order growth and convexity
Apr 15, 2026Davis, Drusvyatskiy, and Jiang showed that gradient descent with an adaptive stepsize converges locally at a nearly-linear rate for smooth functions that grow at least quartically away from their minimizers. The argument is intricate, relying on monitoring the performance of the algorithm relative to a certain manifold of slow growth -- called the ravine. In this work, we provide a direct Lyapunov-based argument that bypasses these difficulties when the objective is in addition convex and a has a unique minimizer. As a byproduct of the argument, we obtain a more adaptive variant than the original algorithm with encouraging numerical performance.
Iteratively reweighted kernel machines efficiently learn sparse functions
May 13, 2025The impressive practical performance of neural networks is often attributed to their ability to learn low-dimensional data representations and hierarchical structure directly from data. In this work, we argue that these two phenomena are not unique to neural networks, and can be elicited from classical kernel methods. Namely, we show that the derivative of the kernel predictor can detect the influential coordinates with low sample complexity. Moreover, by iteratively using the derivatives to reweight the data and retrain kernel machines, one is able to efficiently learn hierarchical polynomials with finite leap complexity. Numerical experiments illustrate the developed theory.
Online Covariance Estimation in Nonsmooth Stochastic Approximation
Feb 07, 2025
We consider applying stochastic approximation (SA) methods to solve nonsmooth variational inclusion problems. Existing studies have shown that the averaged iterates of SA methods exhibit asymptotic normality, with an optimal limiting covariance matrix in the local minimax sense of H\'ajek and Le Cam. However, no methods have been proposed to estimate this covariance matrix in a nonsmooth and potentially non-monotone (nonconvex) setting. In this paper, we study an online batch-means covariance matrix estimator introduced in Zhu et al.(2023). The estimator groups the SA iterates appropriately and computes the sample covariance among batches as an estimate of the limiting covariance. Its construction does not require prior knowledge of the total sample size, and updates can be performed recursively as new data arrives. We establish that, as long as the batch size sequence is properly specified (depending on the stepsize sequence), the estimator achieves a convergence rate of order $O(\sqrt{d}n^{-1/8+\varepsilon})$ for any $\varepsilon>0$, where $d$ and $n$ denote the problem dimensionality and the number of iterations (or samples) used. Although the problem is nonsmooth and potentially non-monotone (nonconvex), our convergence rate matches the best-known rate for covariance estimation methods using only first-order information in smooth and strongly-convex settings. The consistency of this covariance estimator enables asymptotically valid statistical inference, including constructing confidence intervals and performing hypothesis testing.
Invariant Kernels: Rank Stabilization and Generalization Across Dimensions
Feb 03, 2025Symmetry arises often when learning from high dimensional data. For example, data sets consisting of point clouds, graphs, and unordered sets appear routinely in contemporary applications, and exhibit rich underlying symmetries. Understanding the benefits of symmetry on the statistical and numerical efficiency of learning algorithms is an active area of research. In this work, we show that symmetry has a pronounced impact on the rank of kernel matrices. Specifically, we compute the rank of a polynomial kernel of fixed degree that is invariant under various groups acting independently on its two arguments. In concrete circumstances, including the three aforementioned examples, symmetry dramatically decreases the rank making it independent of the data dimension. In such settings, we show that a simple regression procedure is minimax optimal for estimating an invariant polynomial from finitely many samples drawn across different dimensions. We complete the paper with numerical experiments that illustrate our findings.
Gradient descent with adaptive stepsize converges (nearly) linearly under fourth-order growth
Sep 29, 2024A prevalent belief among optimization specialists is that linear convergence of gradient descent is contingent on the function growing quadratically away from its minimizers. In this work, we argue that this belief is inaccurate. We show that gradient descent with an adaptive stepsize converges at a local (nearly) linear rate on any smooth function that merely exhibits fourth-order growth away from its minimizer. The adaptive stepsize we propose arises from an intriguing decomposition theorem: any such function admits a smooth manifold around the optimal solution -- which we call the ravine -- so that the function grows at least quadratically away from the ravine and has constant order growth along it. The ravine allows one to interlace many short gradient steps with a single long Polyak gradient step, which together ensure rapid convergence to the minimizer. We illustrate the theory and algorithm on the problems of matrix sensing and factorization and learning a single neuron in the overparameterized regime.
The radius of statistical efficiency
May 15, 2024
Classical results in asymptotic statistics show that the Fisher information matrix controls the difficulty of estimating a statistical model from observed data. In this work, we introduce a companion measure of robustness of an estimation problem: the radius of statistical efficiency (RSE) is the size of the smallest perturbation to the problem data that renders the Fisher information matrix singular. We compute RSE up to numerical constants for a variety of test bed problems, including principal component analysis, generalized linear models, phase retrieval, bilinear sensing, and matrix completion. In all cases, the RSE quantifies the compatibility between the covariance of the population data and the latent model parameter. Interestingly, we observe a precise reciprocal relationship between RSE and the intrinsic complexity/sensitivity of the problem instance, paralleling the classical Eckart-Young theorem in numerical analysis.
Linear Recursive Feature Machines provably recover low-rank matrices
Jan 09, 2024



A fundamental problem in machine learning is to understand how neural networks make accurate predictions, while seemingly bypassing the curse of dimensionality. A possible explanation is that common training algorithms for neural networks implicitly perform dimensionality reduction - a process called feature learning. Recent work posited that the effects of feature learning can be elicited from a classical statistical estimator called the average gradient outer product (AGOP). The authors proposed Recursive Feature Machines (RFMs) as an algorithm that explicitly performs feature learning by alternating between (1) reweighting the feature vectors by the AGOP and (2) learning the prediction function in the transformed space. In this work, we develop the first theoretical guarantees for how RFM performs dimensionality reduction by focusing on the class of overparametrized problems arising in sparse linear regression and low-rank matrix recovery. Specifically, we show that RFM restricted to linear models (lin-RFM) generalizes the well-studied Iteratively Reweighted Least Squares (IRLS) algorithm. Our results shed light on the connection between feature learning in neural networks and classical sparse recovery algorithms. In addition, we provide an implementation of lin-RFM that scales to matrices with millions of missing entries. Our implementation is faster than the standard IRLS algorithm as it is SVD-free. It also outperforms deep linear networks for sparse linear regression and low-rank matrix completion.
Aiming towards the minimizers: fast convergence of SGD for overparametrized problems
Jun 05, 2023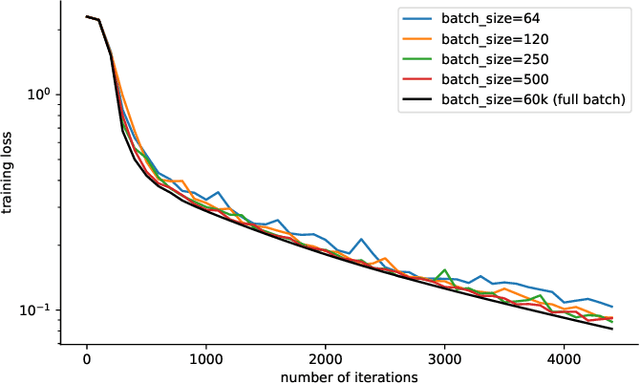
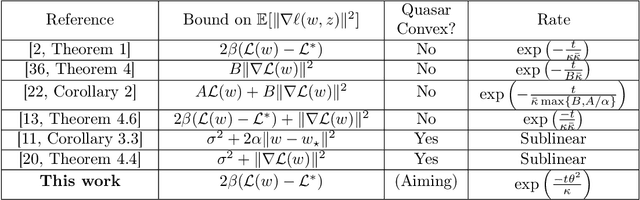
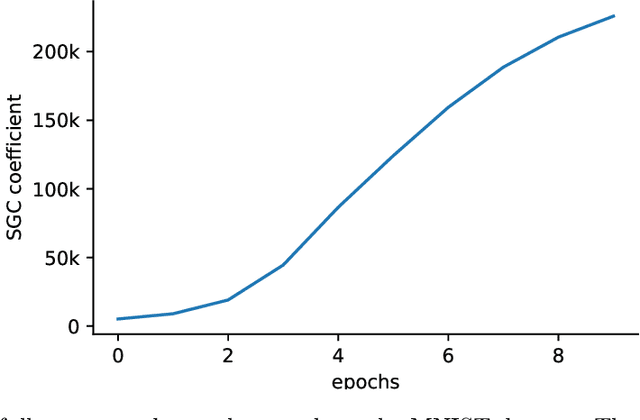
Modern machine learning paradigms, such as deep learning, occur in or close to the interpolation regime, wherein the number of model parameters is much larger than the number of data samples. In this work, we propose a regularity condition within the interpolation regime which endows the stochastic gradient method with the same worst-case iteration complexity as the deterministic gradient method, while using only a single sampled gradient (or a minibatch) in each iteration. In contrast, all existing guarantees require the stochastic gradient method to take small steps, thereby resulting in a much slower linear rate of convergence. Finally, we demonstrate that our condition holds when training sufficiently wide feedforward neural networks with a linear output layer.
Asymptotic normality and optimality in nonsmooth stochastic approximation
Jan 16, 2023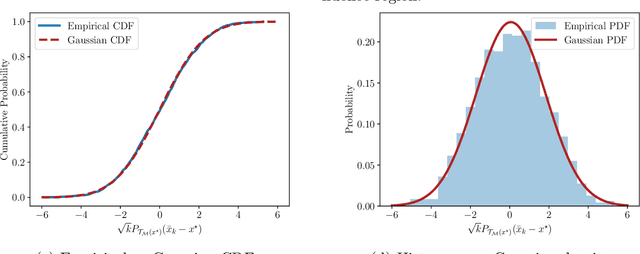
In their seminal work, Polyak and Juditsky showed that stochastic approximation algorithms for solving smooth equations enjoy a central limit theorem. Moreover, it has since been argued that the asymptotic covariance of the method is best possible among any estimation procedure in a local minimax sense of H\'{a}jek and Le Cam. A long-standing open question in this line of work is whether similar guarantees hold for important non-smooth problems, such as stochastic nonlinear programming or stochastic variational inequalities. In this work, we show that this is indeed the case.