 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe radius of statistical efficiency
May 15, 2024
Classical results in asymptotic statistics show that the Fisher information matrix controls the difficulty of estimating a statistical model from observed data. In this work, we introduce a companion measure of robustness of an estimation problem: the radius of statistical efficiency (RSE) is the size of the smallest perturbation to the problem data that renders the Fisher information matrix singular. We compute RSE up to numerical constants for a variety of test bed problems, including principal component analysis, generalized linear models, phase retrieval, bilinear sensing, and matrix completion. In all cases, the RSE quantifies the compatibility between the covariance of the population data and the latent model parameter. Interestingly, we observe a precise reciprocal relationship between RSE and the intrinsic complexity/sensitivity of the problem instance, paralleling the classical Eckart-Young theorem in numerical analysis.
Stochastic approximation with decision-dependent distributions: asymptotic normality and optimality
Jul 09, 2022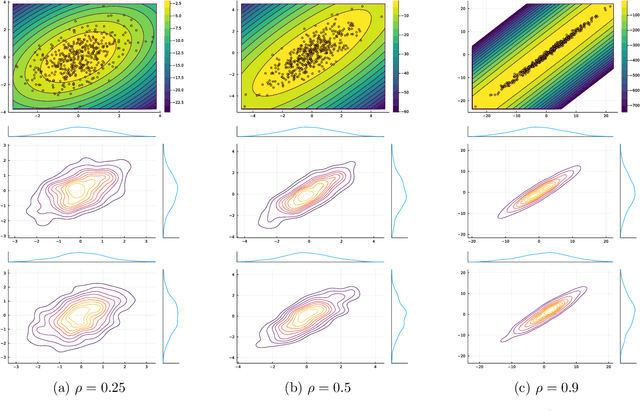
We analyze a stochastic approximation algorithm for decision-dependent problems, wherein the data distribution used by the algorithm evolves along the iterate sequence. The primary examples of such problems appear in performative prediction and its multiplayer extensions. We show that under mild assumptions, the deviation between the average iterate of the algorithm and the solution is asymptotically normal, with a covariance that nicely decouples the effects of the gradient noise and the distributional shift. Moreover, building on the work of H\'ajek and Le Cam, we show that the asymptotic performance of the algorithm is locally minimax optimal.
Stochastic optimization under time drift: iterate averaging, step decay, and high probability guarantees
Aug 16, 2021
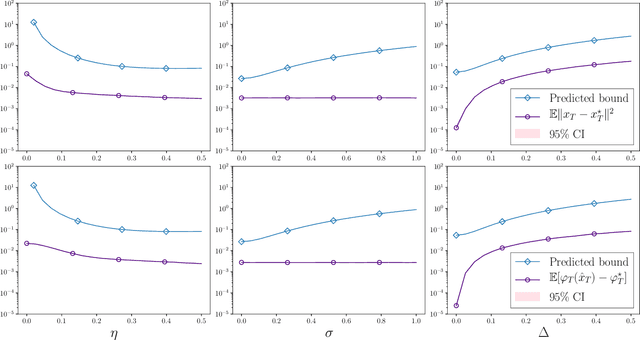
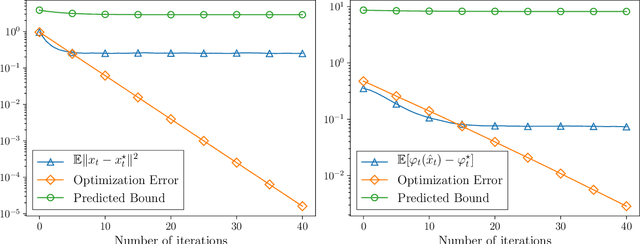
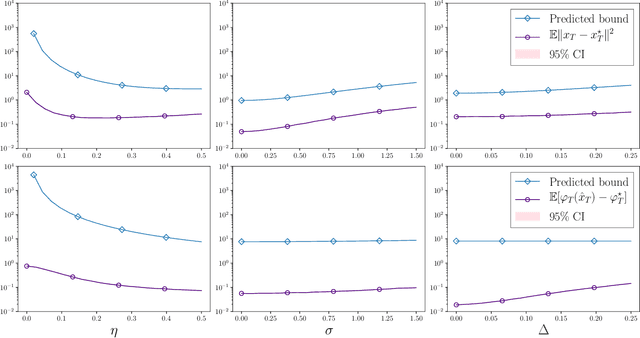
We consider the problem of minimizing a convex function that is evolving in time according to unknown and possibly stochastic dynamics. Such problems abound in the machine learning and signal processing literature, under the names of concept drift and stochastic tracking. We provide novel non-asymptotic convergence guarantees for stochastic algorithms with iterate averaging, focusing on bounds valid both in expectation and with high probability. Notably, we show that the tracking efficiency of the proximal stochastic gradient method depends only logarithmically on the initialization quality, when equipped with a step-decay schedule. The results moreover naturally extend to settings where the dynamics depend jointly on time and on the decision variable itself, as in the performative prediction framework.