 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$μ$pscaling small models: Principled warm starts and hyperparameter transfer
Feb 11, 2026Modern large-scale neural networks are often trained and released in multiple sizes to accommodate diverse inference budgets. To improve efficiency, recent work has explored model upscaling: initializing larger models from trained smaller ones in order to transfer knowledge and accelerate convergence. However, this method can be sensitive to hyperparameters that need to be tuned at the target upscaled model size, which is prohibitively costly to do directly. It remains unclear whether the most common workaround -- tuning on smaller models and extrapolating via hyperparameter scaling laws -- is still sound when using upscaling. We address this with principled approaches to upscaling with respect to model widths and efficiently tuning hyperparameters in this setting. First, motivated by $μ$P and any-dimensional architectures, we introduce a general upscaling method applicable to a broad range of architectures and optimizers, backed by theory guaranteeing that models are equivalent to their widened versions and allowing for rigorous analysis of infinite-width limits. Second, we extend the theory of $μ$Transfer to a hyperparameter transfer technique for models upscaled using our method and empirically demonstrate that this method is effective on realistic datasets and architectures.
On Transferring Transferability: Towards a Theory for Size Generalization
May 29, 2025Many modern learning tasks require models that can take inputs of varying sizes. Consequently, dimension-independent architectures have been proposed for domains where the inputs are graphs, sets, and point clouds. Recent work on graph neural networks has explored whether a model trained on low-dimensional data can transfer its performance to higher-dimensional inputs. We extend this body of work by introducing a general framework for transferability across dimensions. We show that transferability corresponds precisely to continuity in a limit space formed by identifying small problem instances with equivalent large ones. This identification is driven by the data and the learning task. We instantiate our framework on existing architectures, and implement the necessary changes to ensure their transferability. Finally, we provide design principles for designing new transferable models. Numerical experiments support our findings.
Invariant Kernels: Rank Stabilization and Generalization Across Dimensions
Feb 03, 2025Symmetry arises often when learning from high dimensional data. For example, data sets consisting of point clouds, graphs, and unordered sets appear routinely in contemporary applications, and exhibit rich underlying symmetries. Understanding the benefits of symmetry on the statistical and numerical efficiency of learning algorithms is an active area of research. In this work, we show that symmetry has a pronounced impact on the rank of kernel matrices. Specifically, we compute the rank of a polynomial kernel of fixed degree that is invariant under various groups acting independently on its two arguments. In concrete circumstances, including the three aforementioned examples, symmetry dramatically decreases the rank making it independent of the data dimension. In such settings, we show that a simple regression procedure is minimax optimal for estimating an invariant polynomial from finitely many samples drawn across different dimensions. We complete the paper with numerical experiments that illustrate our findings.
The radius of statistical efficiency
May 15, 2024
Classical results in asymptotic statistics show that the Fisher information matrix controls the difficulty of estimating a statistical model from observed data. In this work, we introduce a companion measure of robustness of an estimation problem: the radius of statistical efficiency (RSE) is the size of the smallest perturbation to the problem data that renders the Fisher information matrix singular. We compute RSE up to numerical constants for a variety of test bed problems, including principal component analysis, generalized linear models, phase retrieval, bilinear sensing, and matrix completion. In all cases, the RSE quantifies the compatibility between the covariance of the population data and the latent model parameter. Interestingly, we observe a precise reciprocal relationship between RSE and the intrinsic complexity/sensitivity of the problem instance, paralleling the classical Eckart-Young theorem in numerical analysis.
Any-dimensional equivariant neural networks
Jun 10, 2023Traditional supervised learning aims to learn an unknown mapping by fitting a function to a set of input-output pairs with a fixed dimension. The fitted function is then defined on inputs of the same dimension. However, in many settings, the unknown mapping takes inputs in any dimension; examples include graph parameters defined on graphs of any size and physics quantities defined on an arbitrary number of particles. We leverage a newly-discovered phenomenon in algebraic topology, called representation stability, to define equivariant neural networks that can be trained with data in a fixed dimension and then extended to accept inputs in any dimension. Our approach is user-friendly, requiring only the network architecture and the groups for equivariance, and can be combined with any training procedure. We provide a simple open-source implementation of our methods and offer preliminary numerical experiments.
Robust, randomized preconditioning for kernel ridge regression
Apr 29, 2023



This paper introduces two randomized preconditioning techniques for robustly solving kernel ridge regression (KRR) problems with a medium to large number of data points ($10^4 \leq N \leq 10^7$). The first method, RPCholesky preconditioning, is capable of accurately solving the full-data KRR problem in $O(N^2)$ arithmetic operations, assuming sufficiently rapid polynomial decay of the kernel matrix eigenvalues. The second method, KRILL preconditioning, offers an accurate solution to a restricted version of the KRR problem involving $k \ll N$ selected data centers at a cost of $O((N + k^2) k \log k)$ operations. The proposed methods solve a broad range of KRR problems and overcome the failure modes of previous KRR preconditioners, making them ideal for practical applications.
Stochastic approximation with decision-dependent distributions: asymptotic normality and optimality
Jul 09, 2022
We analyze a stochastic approximation algorithm for decision-dependent problems, wherein the data distribution used by the algorithm evolves along the iterate sequence. The primary examples of such problems appear in performative prediction and its multiplayer extensions. We show that under mild assumptions, the deviation between the average iterate of the algorithm and the solution is asymptotically normal, with a covariance that nicely decouples the effects of the gradient noise and the distributional shift. Moreover, building on the work of H\'ajek and Le Cam, we show that the asymptotic performance of the algorithm is locally minimax optimal.
Escaping strict saddle points of the Moreau envelope in nonsmooth optimization
Jun 17, 2021


Recent work has shown that stochastically perturbed gradient methods can efficiently escape strict saddle points of smooth functions. We extend this body of work to nonsmooth optimization, by analyzing an inexact analogue of a stochastically perturbed gradient method applied to the Moreau envelope. The main conclusion is that a variety of algorithms for nonsmooth optimization can escape strict saddle points of the Moreau envelope at a controlled rate. The main technical insight is that typical algorithms applied to the proximal subproblem yield directions that approximate the gradient of the Moreau envelope in relative terms.
Low-rank matrix recovery with composite optimization: good conditioning and rapid convergence
Apr 22, 2019
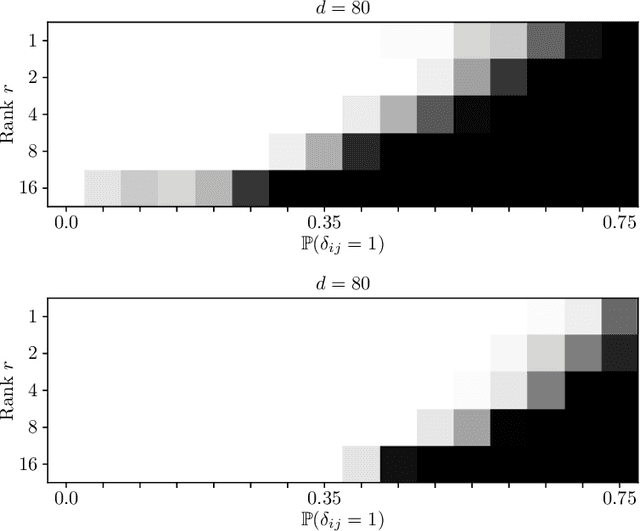
The task of recovering a low-rank matrix from its noisy linear measurements plays a central role in computational science. Smooth formulations of the problem often exhibit an undesirable phenomenon: the condition number, classically defined, scales poorly with the dimension of the ambient space. In contrast, we here show that in a variety of concrete circumstances, nonsmooth penalty formulations do not suffer from the same type of ill-conditioning. Consequently, standard algorithms for nonsmooth optimization, such as subgradient and prox-linear methods, converge at a rapid dimension-independent rate when initialized within constant relative error of the solution. Moreover, nonsmooth formulations are naturally robust against outliers. Our framework subsumes such important computational tasks as phase retrieval, blind deconvolution, quadratic sensing, matrix completion, and robust PCA. Numerical experiments on these problems illustrate the benefits of the proposed approach.
Composite optimization for robust blind deconvolution
Jan 18, 2019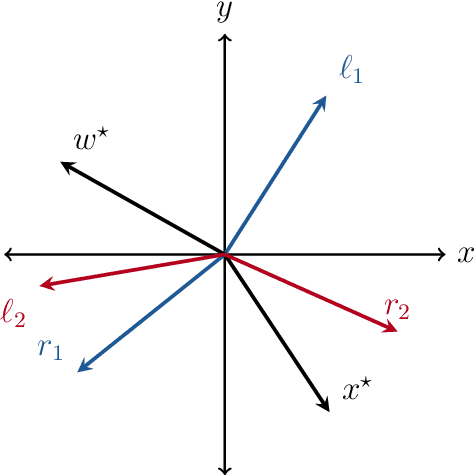
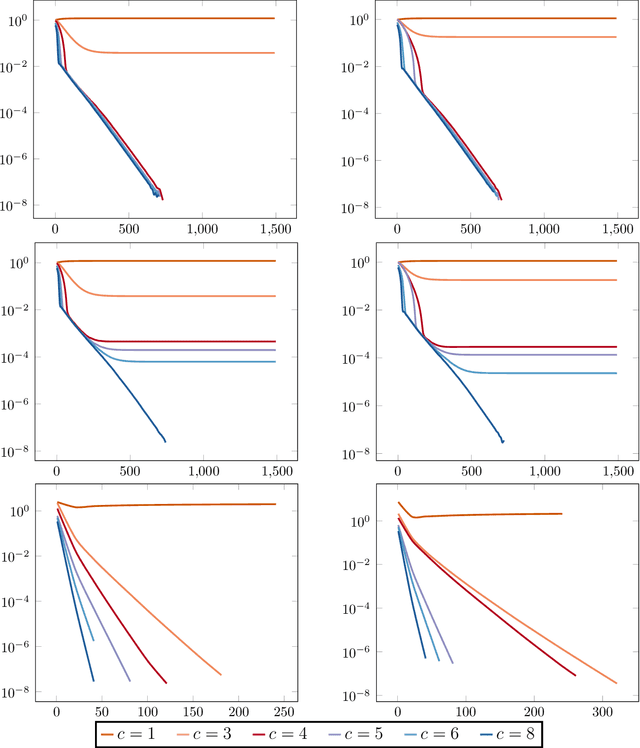
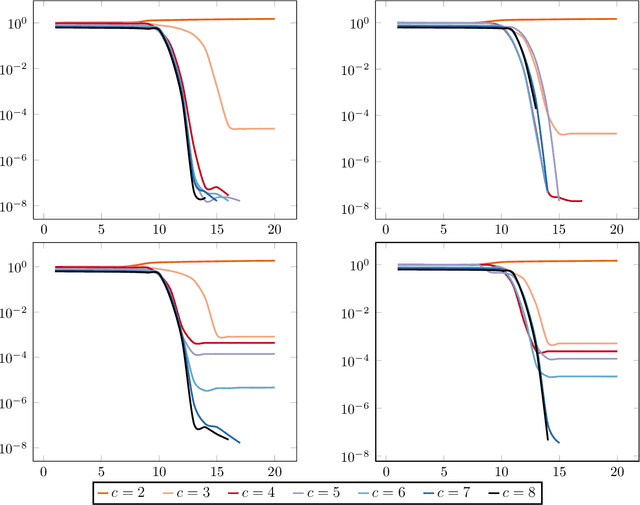
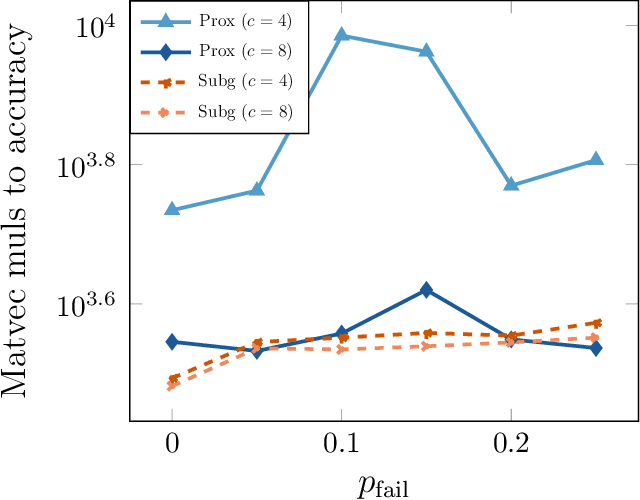
The blind deconvolution problem seeks to recover a pair of vectors from a set of rank one bilinear measurements. We consider a natural nonsmooth formulation of the problem and show that under standard statistical assumptions, its moduli of weak convexity, sharpness, and Lipschitz continuity are all dimension independent. This phenomenon persists even when up to half of the measurements are corrupted by noise. Consequently, standard algorithms, such as the subgradient and prox-linear methods, converge at a rapid dimension-independent rate when initialized within constant relative error of the solution. We then complete the paper with a new initialization strategy, complementing the local search algorithms. The initialization procedure is both provably efficient and robust to outlying measurements. Numerical experiments, on both simulated and real data, illustrate the developed theory and methods.