 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$μ$pscaling small models: Principled warm starts and hyperparameter transfer
Feb 11, 2026Modern large-scale neural networks are often trained and released in multiple sizes to accommodate diverse inference budgets. To improve efficiency, recent work has explored model upscaling: initializing larger models from trained smaller ones in order to transfer knowledge and accelerate convergence. However, this method can be sensitive to hyperparameters that need to be tuned at the target upscaled model size, which is prohibitively costly to do directly. It remains unclear whether the most common workaround -- tuning on smaller models and extrapolating via hyperparameter scaling laws -- is still sound when using upscaling. We address this with principled approaches to upscaling with respect to model widths and efficiently tuning hyperparameters in this setting. First, motivated by $μ$P and any-dimensional architectures, we introduce a general upscaling method applicable to a broad range of architectures and optimizers, backed by theory guaranteeing that models are equivalent to their widened versions and allowing for rigorous analysis of infinite-width limits. Second, we extend the theory of $μ$Transfer to a hyperparameter transfer technique for models upscaled using our method and empirically demonstrate that this method is effective on realistic datasets and architectures.
Learning Rate Scaling across LoRA Ranks and Transfer to Full Finetuning
Feb 05, 2026Low-Rank Adaptation (LoRA) is a standard tool for parameter-efficient finetuning of large models. While it induces a small memory footprint, its training dynamics can be surprisingly complex as they depend on several hyperparameters such as initialization, adapter rank, and learning rate. In particular, it is unclear how the optimal learning rate scales with adapter rank, which forces practitioners to re-tune the learning rate whenever the rank is changed. In this paper, we introduce Maximal-Update Adaptation ($μ$A), a theoretical framework that characterizes how the "optimal" learning rate should scale with model width and adapter rank to produce stable, non-vanishing feature updates under standard configurations. $μ$A is inspired from the Maximal-Update Parametrization ($μ$P) in pretraining. Our analysis leverages techniques from hyperparameter transfer and reveals that the optimal learning rate exhibits different scaling patterns depending on initialization and LoRA scaling factor. Specifically, we identify two regimes: one where the optimal learning rate remains roughly invariant across ranks, and another where it scales inversely with rank. We further identify a configuration that allows learning rate transfer from LoRA to full finetuning, drastically reducing the cost of learning rate tuning for full finetuning. Experiments across language, vision, vision--language, image generation, and reinforcement learning tasks validate our scaling rules and show that learning rates tuned on LoRA transfer reliably to full finetuning.
Group Averaging for Physics Applications: Accuracy Improvements at Zero Training Cost
Nov 11, 2025



Many machine learning tasks in the natural sciences are precisely equivariant to particular symmetries. Nonetheless, equivariant methods are often not employed, perhaps because training is perceived to be challenging, or the symmetry is expected to be learned, or equivariant implementations are seen as hard to build. Group averaging is an available technique for these situations. It happens at test time; it can make any trained model precisely equivariant at a (often small) cost proportional to the size of the group; it places no requirements on model structure or training. It is known that, under mild conditions, the group-averaged model will have a provably better prediction accuracy than the original model. Here we show that an inexpensive group averaging can improve accuracy in practice. We take well-established benchmark machine learning models of differential equations in which certain symmetries ought to be obeyed. At evaluation time, we average the models over a small group of symmetries. Our experiments show that this procedure always decreases the average evaluation loss, with improvements of up to 37\% in terms of the VRMSE. The averaging produces visually better predictions for continuous dynamics. This short paper shows that, under certain common circumstances, there are no disadvantages to imposing exact symmetries; the ML4PS community should consider group averaging as a cheap and simple way to improve model accuracy.
On Transferring Transferability: Towards a Theory for Size Generalization
May 29, 2025Many modern learning tasks require models that can take inputs of varying sizes. Consequently, dimension-independent architectures have been proposed for domains where the inputs are graphs, sets, and point clouds. Recent work on graph neural networks has explored whether a model trained on low-dimensional data can transfer its performance to higher-dimensional inputs. We extend this body of work by introducing a general framework for transferability across dimensions. We show that transferability corresponds precisely to continuity in a limit space formed by identifying small problem instances with equivalent large ones. This identification is driven by the data and the learning task. We instantiate our framework on existing architectures, and implement the necessary changes to ensure their transferability. Finally, we provide design principles for designing new transferable models. Numerical experiments support our findings.
Towards Coordinate- and Dimension-Agnostic Machine Learning for Partial Differential Equations
May 22, 2025The machine learning methods for data-driven identification of partial differential equations (PDEs) are typically defined for a given number of spatial dimensions and a choice of coordinates the data have been collected in. This dependence prevents the learned evolution equation from generalizing to other spaces. In this work, we reformulate the problem in terms of coordinate- and dimension-independent representations, paving the way toward what we call ``spatially liberated" PDE learning. To this end, we employ a machine learning approach to predict the evolution of scalar field systems expressed in the formalism of exterior calculus, which is coordinate-free and immediately generalizes to arbitrary dimensions by construction. We demonstrate the performance of this approach in the FitzHugh-Nagumo and Barkley reaction-diffusion models, as well as the Patlak-Keller-Segel model informed by in-situ chemotactic bacteria observations. We provide extensive numerical experiments that demonstrate that our approach allows for seamless transitions across various spatial contexts. We show that the field dynamics learned in one space can be used to make accurate predictions in other spaces with different dimensions, coordinate systems, boundary conditions, and curvatures.
Graph neural networks and non-commuting operators
Nov 06, 2024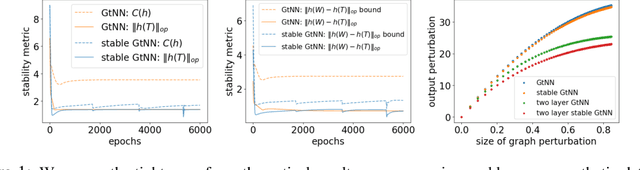
Graph neural networks (GNNs) provide state-of-the-art results in a wide variety of tasks which typically involve predicting features at the vertices of a graph. They are built from layers of graph convolutions which serve as a powerful inductive bias for describing the flow of information among the vertices. Often, more than one data modality is available. This work considers a setting in which several graphs have the same vertex set and a common vertex-level learning task. This generalizes standard GNN models to GNNs with several graph operators that do not commute. We may call this model graph-tuple neural networks (GtNN). In this work, we develop the mathematical theory to address the stability and transferability of GtNNs using properties of non-commuting non-expansive operators. We develop a limit theory of graphon-tuple neural networks and use it to prove a universal transferability theorem that guarantees that all graph-tuple neural networks are transferable on convergent graph-tuple sequences. In particular, there is no non-transferable energy under the convergence we consider here. Our theoretical results extend well-known transferability theorems for GNNs to the case of several simultaneous graphs (GtNNs) and provide a strict improvement on what is currently known even in the GNN case. We illustrate our theoretical results with simple experiments on synthetic and real-world data. To this end, we derive a training procedure that provably enforces the stability of the resulting model.
Thinner Latent Spaces: Detecting dimension and imposing invariance through autoencoder gradient constraints
Aug 28, 2024
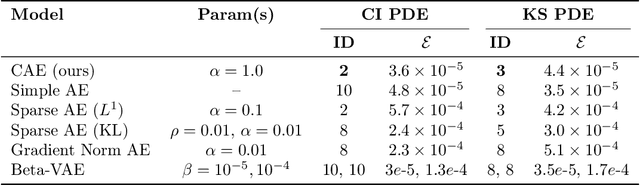
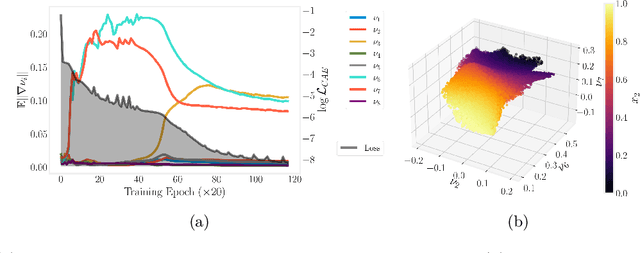

Conformal Autoencoders are a neural network architecture that imposes orthogonality conditions between the gradients of latent variables towards achieving disentangled representations of data. In this letter we show that orthogonality relations within the latent layer of the network can be leveraged to infer the intrinsic dimensionality of nonlinear manifold data sets (locally characterized by the dimension of their tangent space), while simultaneously computing encoding and decoding (embedding) maps. We outline the relevant theory relying on differential geometry, and describe the corresponding gradient-descent optimization algorithm. The method is applied to standard data sets and we highlight its applicability, advantages, and shortcomings. In addition, we demonstrate that the same computational technology can be used to build coordinate invariance to local group actions when defined only on a (reduced) submanifold of the embedding space.
Learning equivariant tensor functions with applications to sparse vector recovery
Jun 03, 2024



This work characterizes equivariant polynomial functions from tuples of tensor inputs to tensor outputs. Loosely motivated by physics, we focus on equivariant functions with respect to the diagonal action of the orthogonal group on tensors. We show how to extend this characterization to other linear algebraic groups, including the Lorentz and symplectic groups. Our goal behind these characterizations is to define equivariant machine learning models. In particular, we focus on the sparse vector estimation problem. This problem has been broadly studied in the theoretical computer science literature, and explicit spectral methods, derived by techniques from sum-of-squares, can be shown to recover sparse vectors under certain assumptions. Our numerical results show that the proposed equivariant machine learning models can learn spectral methods that outperform the best theoretically known spectral methods in some regimes. The experiments also suggest that learned spectral methods can solve the problem in settings that have not yet been theoretically analyzed. This is an example of a promising direction in which theory can inform machine learning models and machine learning models could inform theory.
Is machine learning good or bad for the natural sciences?
May 28, 2024
Machine learning (ML) methods are having a huge impact across all of the sciences. However, ML has a strong ontology - in which only the data exist - and a strong epistemology - in which a model is considered good if it performs well on held-out training data. These philosophies are in strong conflict with both standard practices and key philosophies in the natural sciences. Here, we identify some locations for ML in the natural sciences at which the ontology and epistemology are valuable. For example, when an expressive machine learning model is used in a causal inference to represent the effects of confounders, such as foregrounds, backgrounds, or instrument calibration parameters, the model capacity and loose philosophy of ML can make the results more trustworthy. We also show that there are contexts in which the introduction of ML introduces strong, unwanted statistical biases. For one, when ML models are used to emulate physical (or first-principles) simulations, they introduce strong confirmation biases. For another, when expressive regressions are used to label datasets, those labels cannot be used in downstream joint or ensemble analyses without taking on uncontrolled biases. The question in the title is being asked of all of the natural sciences; that is, we are calling on the scientific communities to take a step back and consider the role and value of ML in their fields; the (partial) answers we give here come from the particular perspective of physics.
Learning functions on symmetric matrices and point clouds via lightweight invariant features
May 15, 2024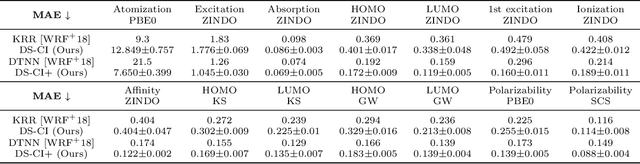
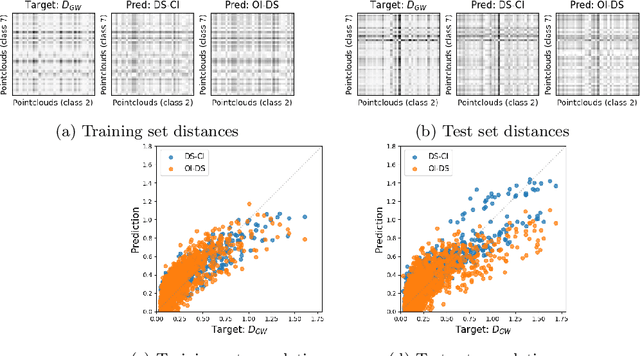
In this work, we present a mathematical formulation for machine learning of (1) functions on symmetric matrices that are invariant with respect to the action of permutations by conjugation, and (2) functions on point clouds that are invariant with respect to rotations, reflections, and permutations of the points. To achieve this, we construct $O(n^2)$ invariant features derived from generators for the field of rational functions on $n\times n$ symmetric matrices that are invariant under joint permutations of rows and columns. We show that these invariant features can separate all distinct orbits of symmetric matrices except for a measure zero set; such features can be used to universally approximate invariant functions on almost all weighted graphs. For point clouds in a fixed dimension, we prove that the number of invariant features can be reduced, generically without losing expressivity, to $O(n)$, where $n$ is the number of points. We combine these invariant features with DeepSets to learn functions on symmetric matrices and point clouds with varying sizes. We empirically demonstrate the feasibility of our approach on molecule property regression and point cloud distance prediction.