 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What's Real: Disentangling Signal and Measurement Artifacts in Multi-Sensor Data, with Applications to Astrophysics
Apr 10, 2026Data collected from the physical world is always a combination of multiple sources: an underlying signal from the physical process of interest and a signal from measurement-dependent artifacts from the sensor or instrument. This secondary signal acts as a confounding factor, limiting our ability to extract information about the physics underlying the phenomena we observe. Furthermore, it complicates the combination of observations in heterogeneous or multi-instrument settings. We propose a deep learning framework that leverages overlapping observations, a dual-encoder architecture, and a counterfactual generation objective to disentangle these factors of variation. The resulting representations explicitly separate intrinsic signals from sensor-specific distortions and noise, and can be used for counterfactual view generation, parameter inference unconfounded by measurement distortions, and instrument-independent similarity search. We demonstrate the effectiveness of our approach on astrophysical galaxy images from the DESI Legacy Imaging Survey (Legacy) and the Hyper Suprime-Cam (HSC) Survey as a representative multi-instrument setting. This framework provides a general recipe for scientific and multi-modal self-supervised pretraining: construct training pairs from overlapping observations of the same physical system, treat sensor- or modality-specific effects as augmentations, and learn invariant representations through counterfactual generation.
Group Averaging for Physics Applications: Accuracy Improvements at Zero Training Cost
Nov 11, 2025



Many machine learning tasks in the natural sciences are precisely equivariant to particular symmetries. Nonetheless, equivariant methods are often not employed, perhaps because training is perceived to be challenging, or the symmetry is expected to be learned, or equivariant implementations are seen as hard to build. Group averaging is an available technique for these situations. It happens at test time; it can make any trained model precisely equivariant at a (often small) cost proportional to the size of the group; it places no requirements on model structure or training. It is known that, under mild conditions, the group-averaged model will have a provably better prediction accuracy than the original model. Here we show that an inexpensive group averaging can improve accuracy in practice. We take well-established benchmark machine learning models of differential equations in which certain symmetries ought to be obeyed. At evaluation time, we average the models over a small group of symmetries. Our experiments show that this procedure always decreases the average evaluation loss, with improvements of up to 37\% in terms of the VRMSE. The averaging produces visually better predictions for continuous dynamics. This short paper shows that, under certain common circumstances, there are no disadvantages to imposing exact symmetries; the ML4PS community should consider group averaging as a cheap and simple way to improve model accuracy.
A formula for the area of a triangle: Useless, but explicitly in Deep Sets form
Mar 28, 2025
Any permutation-invariant function of data points $\vec{r}_i$ can be written in the form $\rho(\sum_i\phi(\vec{r}_i))$ for suitable functions $\rho$ and $\phi$. This form - known in the machine-learning literature as Deep Sets - also generates a map-reduce algorithm. The area of a triangle is a permutation-invariant function of the locations $\vec{r}_i$ of the three corners $1\leq i\leq 3$. We find the polynomial formula for the area of a triangle that is explicitly in Deep Sets form. This project was motivated by questions about the fundamental computational complexity of $n$-point statistics in cosmology; that said, no insights of any kind were gained from these results.
NotPlaNET: Removing False Positives from Planet Hunters TESS with Machine Learning
May 28, 2024Differentiating between real transit events and false positive signals in photometric time series data is a bottleneck in the identification of transiting exoplanets, particularly long-period planets. This differentiation typically requires visual inspection of a large number of transit-like signals to rule out instrumental and astrophysical false positives that mimic planetary transit signals. We build a one-dimensional convolutional neural network (CNN) to separate eclipsing binaries and other false positives from potential planet candidates, reducing the number of light curves that require human vetting. Our CNN is trained using the TESS light curves that were identified by Planet Hunters citizen scientists as likely containing a transit. We also include the background flux and centroid information. The light curves are visually inspected and labeled by project scientists and are minimally pre-processed, with only normalization and data augmentation taking place before training. The median percentage of contaminants flagged across the test sectors is 18% with a maximum of 37% and a minimum of 10%. Our model keeps 100% of the planets for 16 of the 18 test sectors, while incorrectly flagging one planet candidate (0.3%) for one sector and two (0.6%) for the remaining sector. Our method shows potential to reduce the number of light curves requiring manual vetting by up to a third with minimal misclassification of planet candidates.
Is machine learning good or bad for the natural sciences?
May 28, 2024
Machine learning (ML) methods are having a huge impact across all of the sciences. However, ML has a strong ontology - in which only the data exist - and a strong epistemology - in which a model is considered good if it performs well on held-out training data. These philosophies are in strong conflict with both standard practices and key philosophies in the natural sciences. Here, we identify some locations for ML in the natural sciences at which the ontology and epistemology are valuable. For example, when an expressive machine learning model is used in a causal inference to represent the effects of confounders, such as foregrounds, backgrounds, or instrument calibration parameters, the model capacity and loose philosophy of ML can make the results more trustworthy. We also show that there are contexts in which the introduction of ML introduces strong, unwanted statistical biases. For one, when ML models are used to emulate physical (or first-principles) simulations, they introduce strong confirmation biases. For another, when expressive regressions are used to label datasets, those labels cannot be used in downstream joint or ensemble analyses without taking on uncontrolled biases. The question in the title is being asked of all of the natural sciences; that is, we are calling on the scientific communities to take a step back and consider the role and value of ML in their fields; the (partial) answers we give here come from the particular perspective of physics.
GeometricImageNet: Extending convolutional neural networks to vector and tensor images
May 21, 2023



Convolutional neural networks and their ilk have been very successful for many learning tasks involving images. These methods assume that the input is a scalar image representing the intensity in each pixel, possibly in multiple channels for color images. In natural-science domains however, image-like data sets might have vectors (velocity, say), tensors (polarization, say), pseudovectors (magnetic field, say), or other geometric objects in each pixel. Treating the components of these objects as independent channels in a CNN neglects their structure entirely. Our formulation -- the GeometricImageNet -- combines a geometric generalization of convolution with outer products, tensor index contractions, and tensor index permutations to construct geometric-image functions of geometric images that use and benefit from the tensor structure. The framework permits, with a very simple adjustment, restriction to function spaces that are exactly equivariant to translations, discrete rotations, and reflections. We use representation theory to quantify the dimension of the space of equivariant polynomial functions on 2-dimensional vector images. We give partial results on the expressivity of GeometricImageNet on small images. In numerical experiments, we find that GeometricImageNet has good generalization for a small simulated physics system, even when trained with a small training set. We expect this tool will be valuable for scientific and engineering machine learning, for example in cosmology or ocean dynamics.
The passive symmetries of machine learning
Jan 31, 2023

Any representation of data involves arbitrary investigator choices. Because those choices are external to the data-generating process, each choice leads to an exact symmetry, corresponding to the group of transformations that takes one possible representation to another. These are the passive symmetries; they include coordinate freedom, gauge symmetry and units covariance, all of which have led to important results in physics. Our goal is to understand the implications of passive symmetries for machine learning: Which passive symmetries play a role (e.g., permutation symmetry in graph neural networks)? What are dos and don'ts in machine learning practice? We assay conditions under which passive symmetries can be implemented as group equivariances. We also discuss links to causal modeling, and argue that the implementation of passive symmetries is particularly valuable when the goal of the learning problem is to generalize out of sample. While this paper is purely conceptual, we believe that it can have a significant impact on helping machine learning make the transition that took place for modern physics in the first half of the Twentieth century.
Dimensionless machine learning: Imposing exact units equivariance
Apr 02, 2022

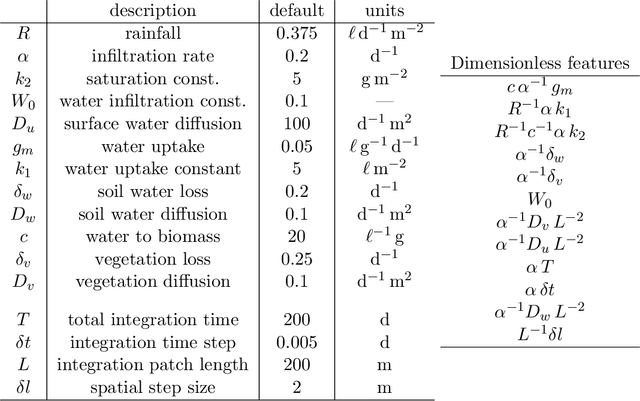
Units equivariance is the exact symmetry that follows from the requirement that relationships among measured quantities of physics relevance must obey self-consistent dimensional scalings. Here, we employ dimensional analysis and ideas from equivariant machine learning to provide a two stage learning procedure for units-equivariant machine learning. For a given learning task, we first construct a dimensionless version of its inputs using classic results from dimensional analysis, and then perform inference in the dimensionless space. Our approach can be used to impose units equivariance across a broad range of machine learning methods which are equivariant to rotations and other groups. We discuss the in-sample and out-of-sample prediction accuracy gains one can obtain in contexts like symbolic regression and emulation, where symmetry is important. We illustrate our approach with simple numerical examples involving dynamical systems in physics and ecology.
A simple equivariant machine learning method for dynamics based on scalars
Oct 30, 2021
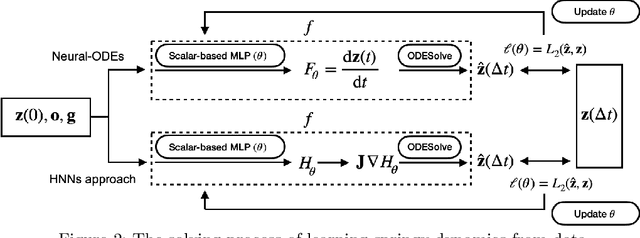
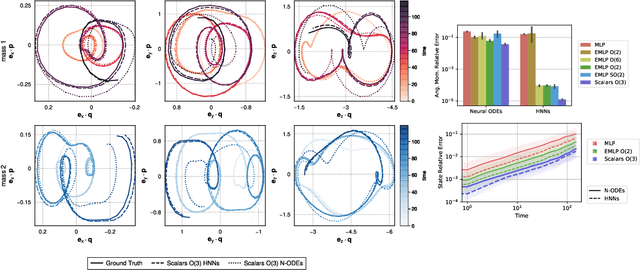
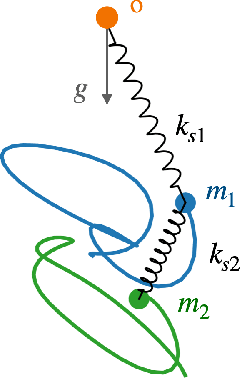
Physical systems obey strict symmetry principles. We expect that machine learning methods that intrinsically respect these symmetries should have higher prediction accuracy and better generalization in prediction of physical dynamics. In this work we implement a principled model based on invariant scalars, and release open-source code. We apply this Scalars method to a simple chaotic dynamical system, the springy double pendulum. We show that the Scalars method outperforms state-of-the-art approaches for learning the properties of physical systems with symmetries, both in terms of accuracy and speed. Because the method incorporates the fundamental symmetries, we expect it to generalize to different settings, such as changes in the force laws in the system.
Scalars are universal: Gauge-equivariant machine learning, structured like classical physics
Jun 11, 2021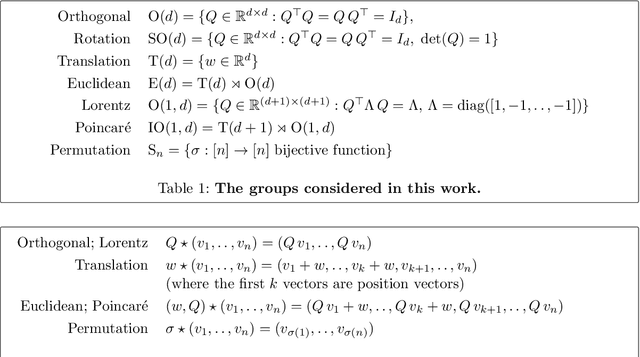
There has been enormous progress in the last few years in designing conceivable (though not always practical) neural networks that respect the gauge symmetries -- or coordinate freedom -- of physical law. Some of these frameworks make use of irreducible representations, some make use of higher order tensor objects, and some apply symmetry-enforcing constraints. Different physical laws obey different combinations of fundamental symmetries, but a large fraction (possibly all) of classical physics is equivariant to translation, rotation, reflection (parity), boost (relativity), and permutations. Here we show that it is simple to parameterize universally approximating polynomial functions that are equivariant under these symmetries, or under the Euclidean, Lorentz, and Poincar\'e groups, at any dimensionality $d$. The key observation is that nonlinear O($d$)-equivariant (and related-group-equivariant) functions can be expressed in terms of a lightweight collection of scalars -- scalar products and scalar contractions of the scalar, vector, and tensor inputs. These results demonstrate theoretically that gauge-invariant deep learning models for classical physics with good scaling for large problems are feasible right now.