 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality reduction, regularization, and generalization in overparameterized regressions
Paper and Code
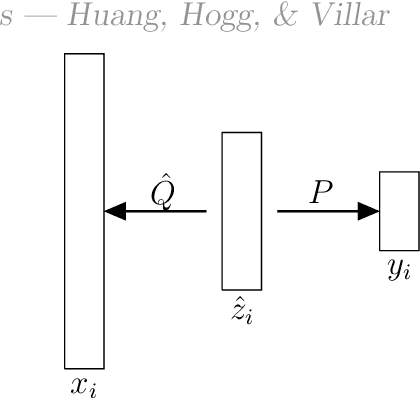
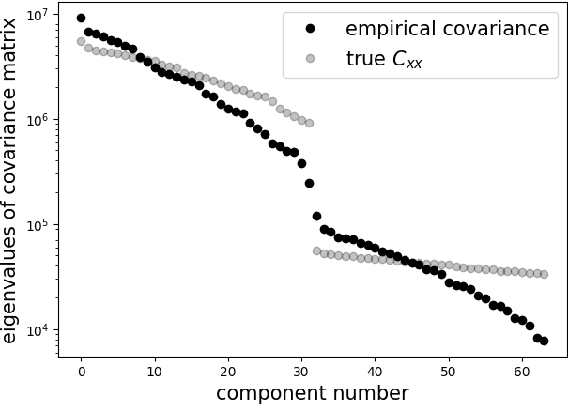
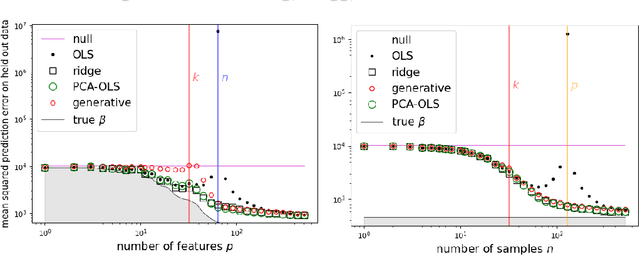
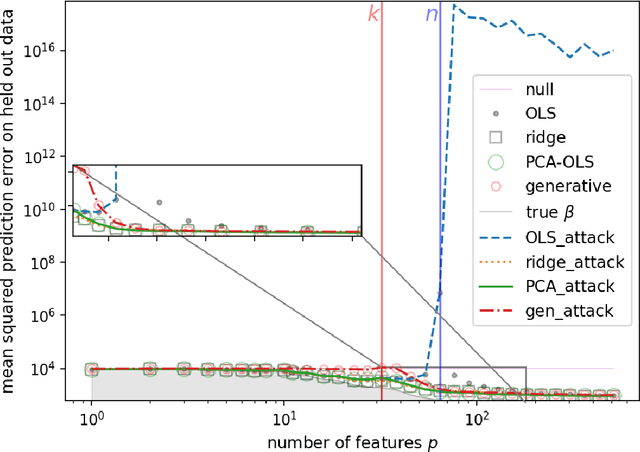
Overparameterization in deep learning is powerful: Very large models fit the training data perfectly and yet generalize well. This realization brought back the study of linear models for regression, including ordinary least squares (OLS), which, like deep learning, shows a "double descent" behavior. This involves two features: (1) The risk (out-of-sample prediction error) can grow arbitrarily when the number of samples $n$ approaches the number of parameters $p$, and (2) the risk decreases with $p$ at $p>n$, sometimes achieving a lower value than the lowest risk at $p<n$. The divergence of the risk for OLS at $p\approx n$ is related to the condition number of the empirical covariance in the feature set. For this reason, it can be avoided with regularization. In this work we show that it can also be avoided with a PCA-based dimensionality reduction. We provide a finite upper bound for the risk of the PCA-based estimator. This result is in contrast to recent work that shows that a different form of dimensionality reduction -- one based on the population covariance instead of the empirical covariance -- does not avoid the divergence. We connect these results to an analysis of adversarial attacks, which become more effective as they raise the condition number of the empirical covariance of the features. We show that OLS is arbitrarily susceptible to data-poisoning attacks in the overparameterized regime -- unlike the underparameterized regime -- and that regularization and dimensionality reduction improve the robustness.