 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal linear convergence of gradient methods for overparameterized Gaussian mixtures
May 29, 2026We study the problem of learning Gaussian mixture models under overparameterization. Prior work has shown that while overparameterization is essential for avoiding spurious local optima and enables global recovery of the ground-truth model using the gradient-EM (expectation-maximization) algorithm, it can dramatically slow down the local rate of convergence. Under certain assumptions on the mixture weights, we show that a standard divergence measure minimized by statistical learning procedures possesses a manifold of slow growth on which the well-known Polyak stepsize reduces the loss geometrically, and design a gradient-based method that converges to minimizers at a locally linear rate. Additionally, we show that our method converges to nearly optimal solutions -- up to a natural misspecification threshold -- for mixtures with arbitrary weights. At a high level, the method alternates between several "short" gradient descent steps that approach the manifold and "long" Polyak steps that contract the distance to minimizers. Our results suggest that slow convergence is not an intrinsic challenge of overparameterization, but can be overcome by exploiting the favorable structure of the loss landscape.
A Model-Guided Neural Network Method for the Inverse Scattering Problem
Dec 10, 2025Inverse medium scattering is an ill-posed, nonlinear wave-based imaging problem arising in medical imaging, remote sensing, and non-destructive testing. Machine learning (ML) methods offer increased inference speed and flexibility in capturing prior knowledge of imaging targets relative to classical optimization-based approaches; however, they perform poorly in regimes where the scattering behavior is highly nonlinear. A key limitation is that ML methods struggle to incorporate the physics governing the scattering process, which are typically inferred implicitly from the training data or loosely enforced via architectural design. In this paper, we present a method that endows a machine learning framework with explicit knowledge of problem physics, in the form of a differentiable solver representing the forward model. The proposed method progressively refines reconstructions of the scattering potential using measurements at increasing wave frequencies, following a classical strategy to stabilize recovery. Empirically, we find that our method provides high-quality reconstructions at a fraction of the computational or sampling costs of competing approaches.
Solving Inverse Problems with Deep Linear Neural Networks: Global Convergence Guarantees for Gradient Descent with Weight Decay
Feb 21, 2025Machine learning methods are commonly used to solve inverse problems, wherein an unknown signal must be estimated from few measurements generated via a known acquisition procedure. In particular, neural networks perform well empirically but have limited theoretical guarantees. In this work, we study an underdetermined linear inverse problem that admits several possible solution mappings. A standard remedy (e.g., in compressed sensing) establishing uniqueness of the solution mapping is to assume knowledge of latent low-dimensional structure in the source signal. We ask the following question: do deep neural networks adapt to this low-dimensional structure when trained by gradient descent with weight decay regularization? We prove that mildly overparameterized deep linear networks trained in this manner converge to an approximate solution that accurately solves the inverse problem while implicitly encoding latent subspace structure. To our knowledge, this is the first result to rigorously show that deep linear networks trained with weight decay automatically adapt to latent subspace structure in the data under practical stepsize and weight initialization schemes. Our work highlights that regularization and overparameterization improve generalization, while overparameterization also accelerates convergence during training.
Faster Adaptive Optimization via Expected Gradient Outer Product Reparameterization
Feb 03, 2025



Adaptive optimization algorithms -- such as Adagrad, Adam, and their variants -- have found widespread use in machine learning, signal processing and many other settings. Several methods in this family are not rotationally equivariant, meaning that simple reparameterizations (i.e. change of basis) can drastically affect their convergence. However, their sensitivity to the choice of parameterization has not been systematically studied; it is not clear how to identify a "favorable" change of basis in which these methods perform best. In this paper we propose a reparameterization method and demonstrate both theoretically and empirically its potential to improve their convergence behavior. Our method is an orthonormal transformation based on the expected gradient outer product (EGOP) matrix, which can be approximated using either full-batch or stochastic gradient oracles. We show that for a broad class of functions, the sensitivity of adaptive algorithms to choice-of-basis is influenced by the decay of the EGOP matrix spectrum. We illustrate the potential impact of EGOP reparameterization by presenting empirical evidence and theoretical arguments that common machine learning tasks with "natural" data exhibit EGOP spectral decay.
Robust and differentially private stochastic linear bandits
Apr 23, 2023In this paper, we study the stochastic linear bandit problem under the additional requirements of differential privacy, robustness and batched observations. In particular, we assume an adversary randomly chooses a constant fraction of the observed rewards in each batch, replacing them with arbitrary numbers. We present differentially private and robust variants of the arm elimination algorithm using logarithmic batch queries under two privacy models and provide regret bounds in both settings. In the first model, every reward in each round is reported by a potentially different client, which reduces to standard local differential privacy (LDP). In the second model, every action is "owned" by a different client, who may aggregate the rewards over multiple queries and privatize the aggregate response instead. To the best of our knowledge, our algorithms are the first simultaneously providing differential privacy and adversarial robustness in the stochastic linear bandits problem.
Communication-efficient distributed eigenspace estimation with arbitrary node failures
May 31, 2022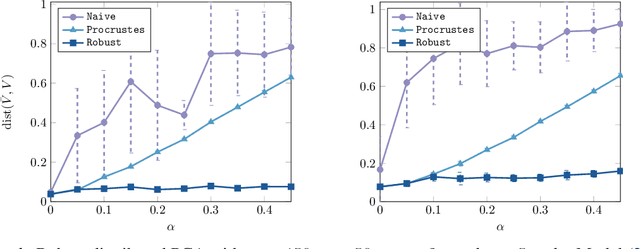
We develop an eigenspace estimation algorithm for distributed environments with arbitrary node failures, where a subset of computing nodes can return structurally valid but otherwise arbitrarily chosen responses. Notably, this setting encompasses several important scenarios that arise in distributed computing and data-collection environments such as silent/soft errors, outliers or corrupted data at certain nodes, and adversarial responses. Our estimator builds upon and matches the performance of a recently proposed non-robust estimator up to an additive $\tilde{O}(\sigma \sqrt{\alpha})$ error, where $\sigma^2$ is the variance of the existing estimator and $\alpha$ is the fraction of corrupted nodes.
Communication-efficient distributed eigenspace estimation
Sep 05, 2020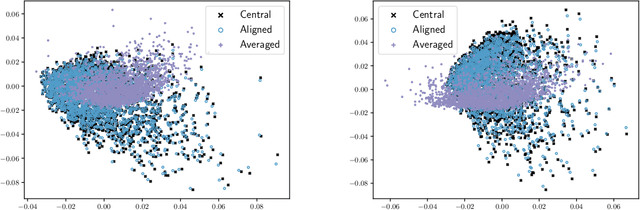

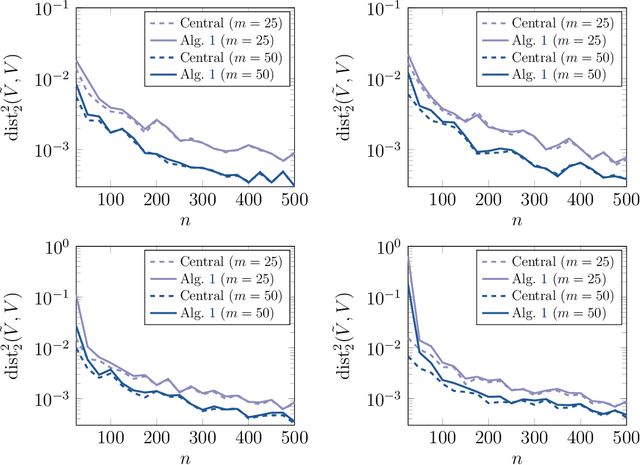

Distributed computing is a standard way to scale up machine learning and data science algorithms to process large amounts of data. In such settings, avoiding communication amongst machines is paramount for achieving high performance. Rather than distribute the computation of existing algorithms, a common practice for avoiding communication is to compute local solutions or parameter estimates on each machine and then combine the results; in many convex optimization problems, even simple averaging of local solutions can work well. However, these schemes do not work when the local solutions are not unique. Spectral methods are a collection of such problems, where solutions are orthonormal bases of the leading invariant subspace of an associated data matrix, which are only unique up to rotation and reflections. Here, we develop a communication-efficient distributed algorithm for computing the leading invariant subspace of a data matrix. Our algorithm uses a novel alignment scheme that minimizes the Procrustean distance between local solutions and a reference solution, and only requires a single round of communication. For the important case of principal component analysis (PCA), we show that our algorithm achieves a similar error rate to that of a centralized estimator. We present numerical experiments demonstrating the efficacy of our proposed algorithm for distributed PCA, as well as other problems where solutions exhibit rotational symmetry, such as node embeddings for graph data and spectral initialization for quadratic sensing.
Entrywise convergence of iterative methods for eigenproblems
Feb 19, 2020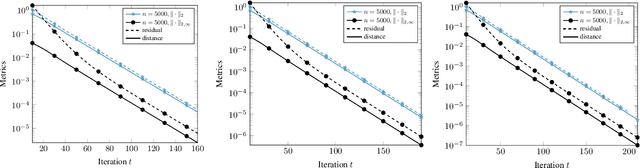
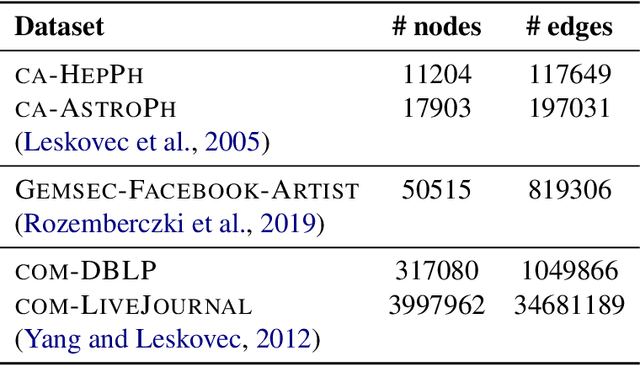
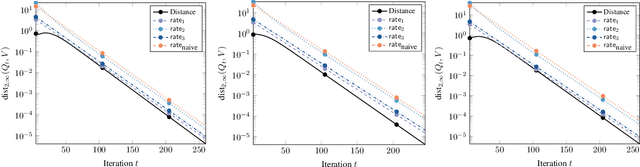
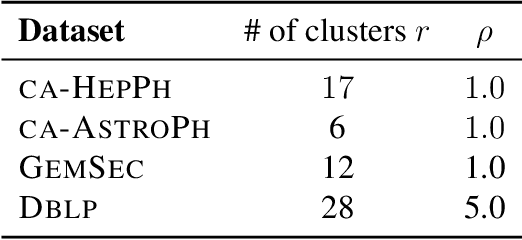
Several problems in machine learning, statistics, and other fields rely on computing eigenvectors. For large scale problems, the computation of these eigenvectors is typically performed via iterative schemes such as subspace iteration or Krylov methods. While there is classical and comprehensive analysis for subspace convergence guarantees with respect to the spectral norm, in many modern applications other notions of subspace distance are more appropriate. Recent theoretical work has focused on perturbations of subspaces measured in the $\ell_{2 \to \infty}$ norm, but does not consider the actual computation of eigenvectors. Here we address the convergence of subspace iteration when distances are measured in the $\ell_{2 \to \infty}$ norm and provide deterministic bounds. We complement our analysis with a practical stopping criterion and demonstrate its applicability via numerical experiments. Our results show that one can get comparable performance on downstream tasks while requiring fewer iterations, thereby saving substantial computational time.
Stochastic algorithms with geometric step decay converge linearly on sharp functions
Jul 22, 2019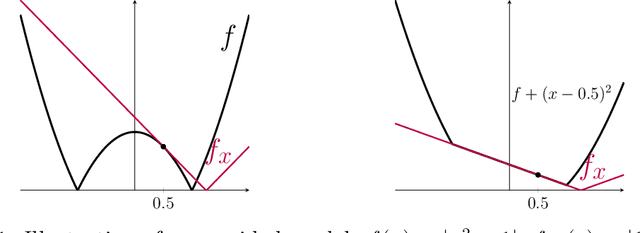
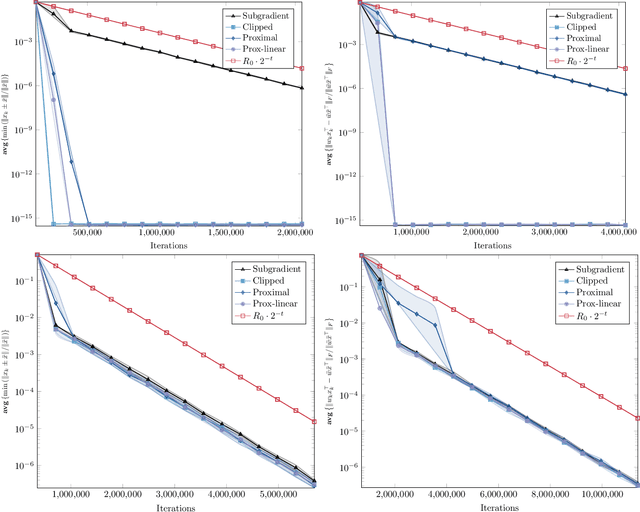
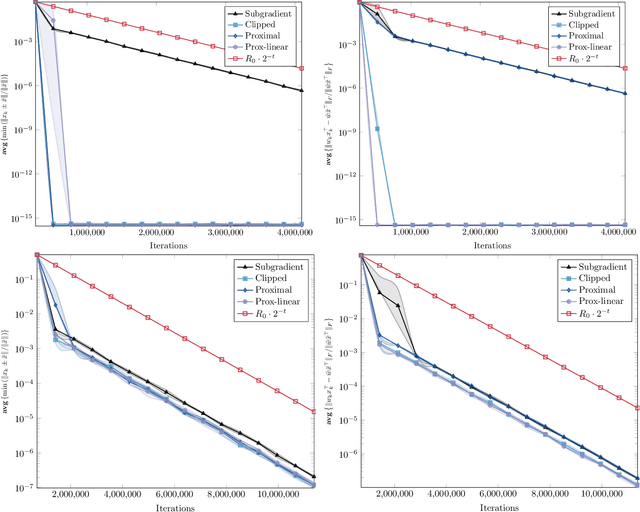
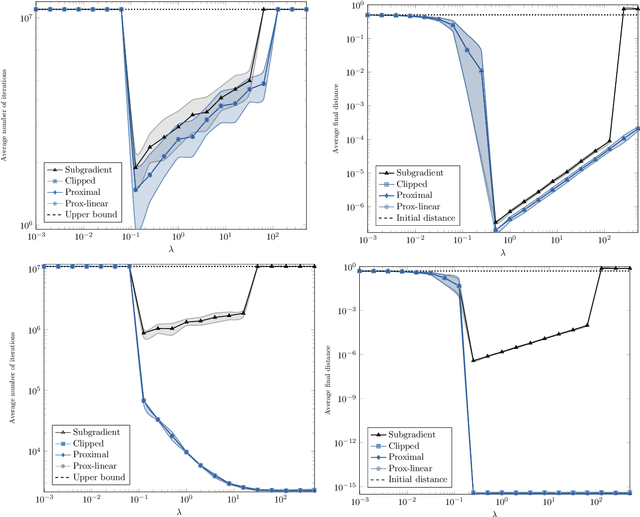
Stochastic (sub)gradient methods require step size schedule tuning to perform well in practice. Classical tuning strategies decay the step size polynomially and lead to optimal sublinear rates on (strongly) convex problems. An alternative schedule, popular in nonconvex optimization, is called \emph{geometric step decay} and proceeds by halving the step size after every few epochs. In recent work, geometric step decay was shown to improve exponentially upon classical sublinear rates for the class of \emph{sharp} convex functions. In this work, we ask whether geometric step decay similarly improves stochastic algorithms for the class of sharp nonconvex problems. Such losses feature in modern statistical recovery problems and lead to a new challenge not present in the convex setting: the region of convergence is local, so one must bound the probability of escape. Our main result shows that for a large class of stochastic, sharp, nonsmooth, and nonconvex problems a geometric step decay schedule endows well-known algorithms with a local linear rate of convergence to global minimizers. This guarantee applies to the stochastic projected subgradient, proximal point, and prox-linear algorithms. As an application of our main result, we analyze two statistical recovery tasks---phase retrieval and blind deconvolution---and match the best known guarantees under Gaussian measurement models and establish new guarantees under heavy-tailed distributions.
Low-rank matrix recovery with composite optimization: good conditioning and rapid convergence
Apr 22, 2019
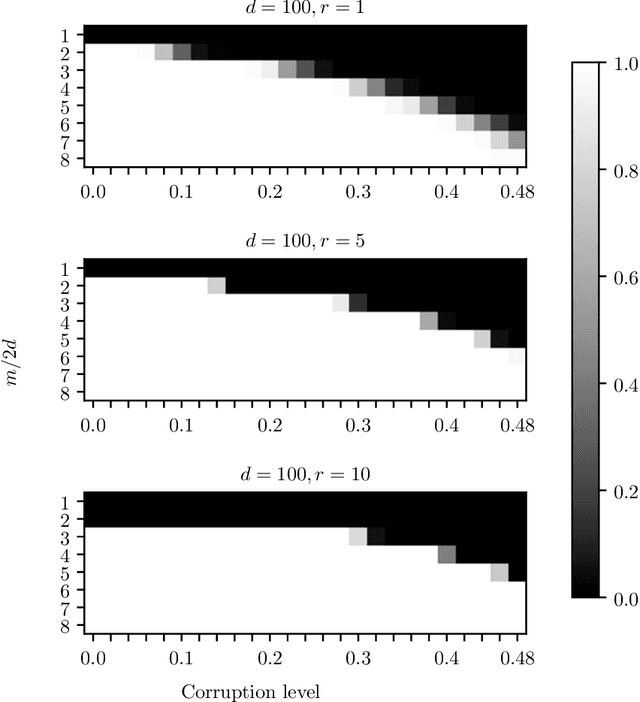
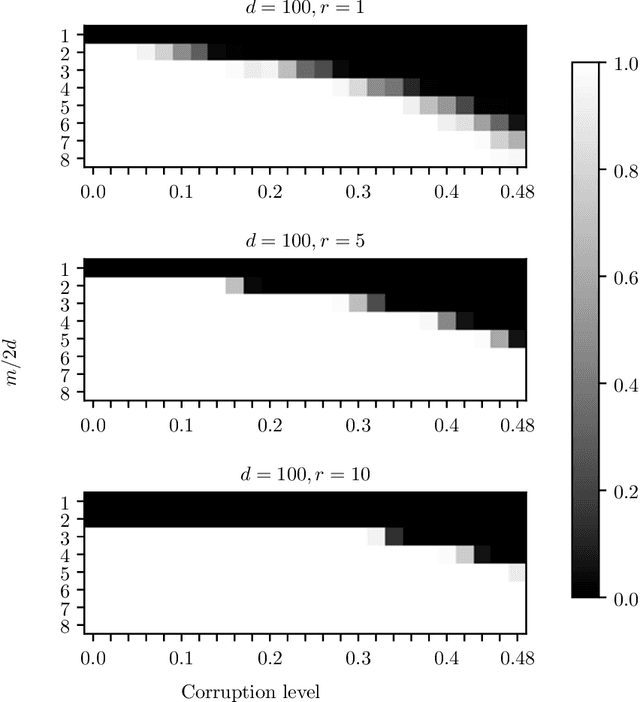
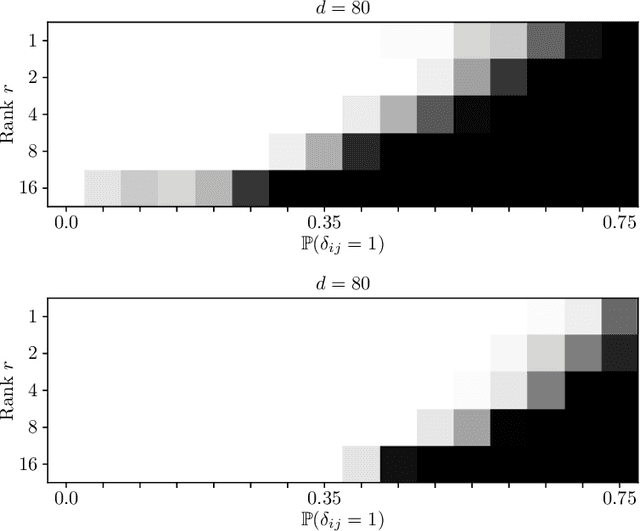
The task of recovering a low-rank matrix from its noisy linear measurements plays a central role in computational science. Smooth formulations of the problem often exhibit an undesirable phenomenon: the condition number, classically defined, scales poorly with the dimension of the ambient space. In contrast, we here show that in a variety of concrete circumstances, nonsmooth penalty formulations do not suffer from the same type of ill-conditioning. Consequently, standard algorithms for nonsmooth optimization, such as subgradient and prox-linear methods, converge at a rapid dimension-independent rate when initialized within constant relative error of the solution. Moreover, nonsmooth formulations are naturally robust against outliers. Our framework subsumes such important computational tasks as phase retrieval, blind deconvolution, quadratic sensing, matrix completion, and robust PCA. Numerical experiments on these problems illustrate the benefits of the proposed approach.