 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbrace rejection: Kernel matrix approximation by accelerated randomly pivoted Cholesky
Oct 04, 2024

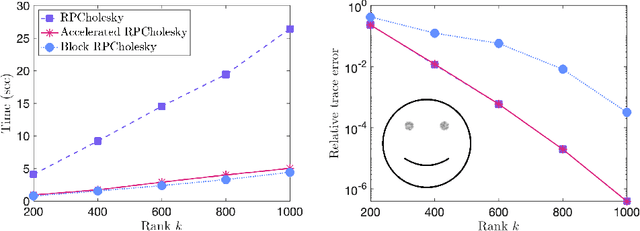

Randomly pivoted Cholesky (RPCholesky) is an algorithm for constructing a low-rank approximation of a positive-semidefinite matrix using a small number of columns. This paper develops an accelerated version of RPCholesky that employs block matrix computations and rejection sampling to efficiently simulate the execution of the original algorithm. For the task of approximating a kernel matrix, the accelerated algorithm can run over $40\times$ faster. The paper contains implementation details, theoretical guarantees, experiments on benchmark data sets, and an application to computational chemistry.
Dynamical mixture modeling with fast, automatic determination of Markov chains
Jun 07, 2024



Markov state modeling has gained popularity in various scientific fields due to its ability to reduce complex time series data into transitions between a few states. Yet, current frameworks are limited by assuming a single Markov chain describes the data, and they suffer an inability to discern heterogeneities. As a solution, this paper proposes a variational expectation-maximization algorithm that identifies a mixture of Markov chains in a time-series data set. The method is agnostic to the definition of the Markov states, whether data-driven (e.g. by spectral clustering) or based on domain knowledge. Variational EM efficiently and organically identifies the number of Markov chains and dynamics of each chain without expensive model comparisons or posterior sampling. The approach is supported by a theoretical analysis and numerical experiments, including simulated and observational data sets based on ${\tt Last.fm}$ music listening, ultramarathon running, and gene expression. The results show the new algorithm is competitive with contemporary mixture modeling approaches and powerful in identifying meaningful heterogeneities in time series data.
Robust, randomized preconditioning for kernel ridge regression
Apr 29, 2023



This paper introduces two randomized preconditioning techniques for robustly solving kernel ridge regression (KRR) problems with a medium to large number of data points ($10^4 \leq N \leq 10^7$). The first method, RPCholesky preconditioning, is capable of accurately solving the full-data KRR problem in $O(N^2)$ arithmetic operations, assuming sufficiently rapid polynomial decay of the kernel matrix eigenvalues. The second method, KRILL preconditioning, offers an accurate solution to a restricted version of the KRR problem involving $k \ll N$ selected data centers at a cost of $O((N + k^2) k \log k)$ operations. The proposed methods solve a broad range of KRR problems and overcome the failure modes of previous KRR preconditioners, making them ideal for practical applications.
Understanding and eliminating spurious modes in variational Monte Carlo using collective variables
Nov 11, 2022The use of neural network parametrizations to represent the ground state in variational Monte Carlo (VMC) calculations has generated intense interest in recent years. However, as we demonstrate in the context of the periodic Heisenberg spin chain, this approach can produce unreliable wave function approximations. One of the most obvious signs of failure is the occurrence of random, persistent spikes in the energy estimate during training. These energy spikes are caused by regions of configuration space that are over-represented by the wave function density, which are called ``spurious modes'' in the machine learning literature. After exploring these spurious modes in detail, we demonstrate that a collective-variable-based penalization yields a substantially more robust training procedure, preventing the formation of spurious modes and improving the accuracy of energy estimates. Because the penalization scheme is cheap to implement and is not specific to the particular model studied here, it can be extended to other applications of VMC where a reasonable choice of collective variable is available.
Randomly pivoted Cholesky: Practical approximation of a kernel matrix with few entry evaluations
Jul 19, 2022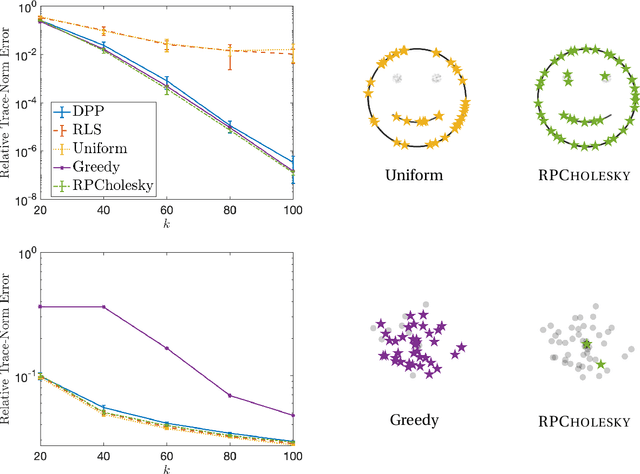
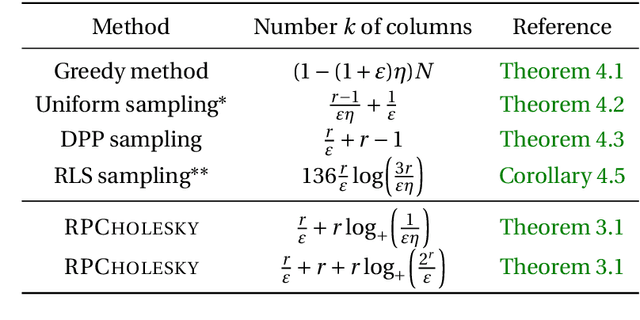
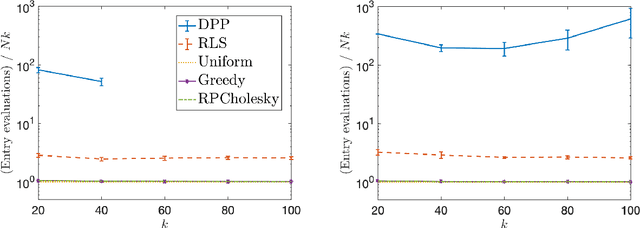
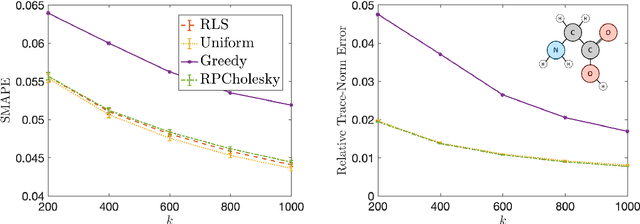
Randomly pivoted Cholesky (RPCholesky) is a natural algorithm for computing a rank-k approximation of an N x N positive semidefinite (psd) matrix. RPCholesky can be implemented with just a few lines of code. It requires only (k+1)N entry evaluations and O(k^2 N) additional arithmetic operations. This paper offers the first serious investigation of its experimental and theoretical behavior. Empirically, RPCholesky matches or improves on the performance of alternative algorithms for low-rank psd approximation. Furthermore, RPCholesky provably achieves near-optimal approximation guarantees. The simplicity, effectiveness, and robustness of this algorithm strongly support its use in scientific computing and machine learning applications.
Rayleigh-Gauss-Newton optimization with enhanced sampling for variational Monte Carlo
Jul 03, 2021
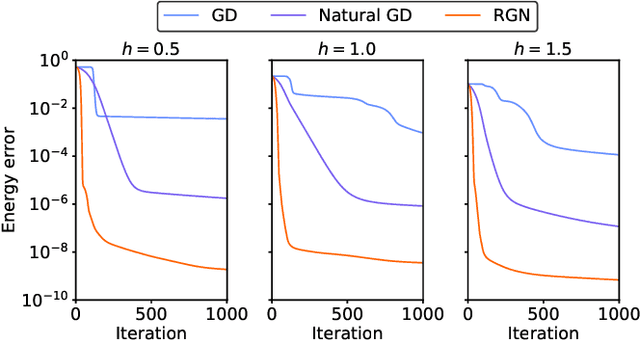
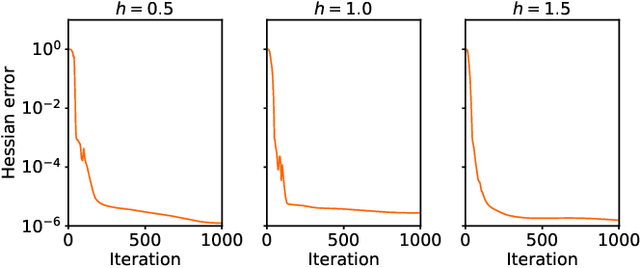
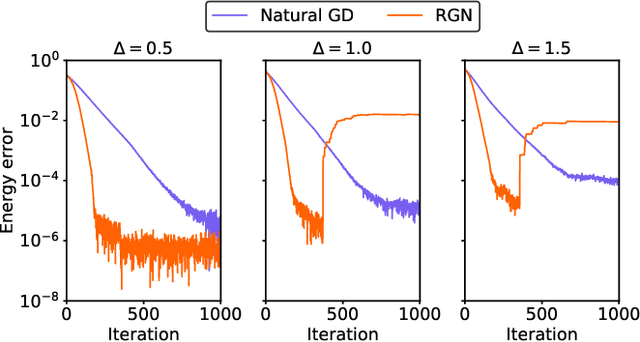
Variational Monte Carlo (VMC) is an approach for computing ground-state wavefunctions that has recently become more powerful due to the introduction of neural network-based wavefunction parametrizations. However, efficiently training neural wavefunctions to converge to an energy minimum remains a difficult problem. In this work, we analyze optimization and sampling methods used in VMC and introduce alterations to improve their performance. First, based on theoretical convergence analysis in a noiseless setting, we motivate a new optimizer that we call the Rayleigh-Gauss-Newton method, which can improve upon gradient descent and natural gradient descent to achieve superlinear convergence with little added computational cost. Second, in order to realize this favorable comparison in the presence of stochastic noise, we analyze the effect of sampling error on VMC parameter updates and experimentally demonstrate that it can be reduced by the parallel tempering method. In particular, we demonstrate that RGN can be made robust to energy spikes that occur when new regions of configuration space become available to the sampler over the course of optimization. Finally, putting theory into practice, we apply our enhanced optimization and sampling methods to the transverse-field Ising and XXZ models on large lattices, yielding ground-state energy estimates with remarkably high accuracy after just 200-500 parameter updates.