 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbrace rejection: Kernel matrix approximation by accelerated randomly pivoted Cholesky
Oct 04, 2024

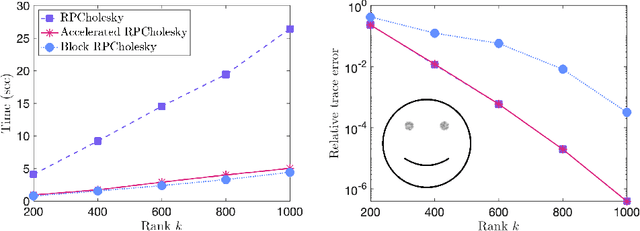

Randomly pivoted Cholesky (RPCholesky) is an algorithm for constructing a low-rank approximation of a positive-semidefinite matrix using a small number of columns. This paper develops an accelerated version of RPCholesky that employs block matrix computations and rejection sampling to efficiently simulate the execution of the original algorithm. For the task of approximating a kernel matrix, the accelerated algorithm can run over $40\times$ faster. The paper contains implementation details, theoretical guarantees, experiments on benchmark data sets, and an application to computational chemistry.
Robust, randomized preconditioning for kernel ridge regression
Apr 29, 2023



This paper introduces two randomized preconditioning techniques for robustly solving kernel ridge regression (KRR) problems with a medium to large number of data points ($10^4 \leq N \leq 10^7$). The first method, RPCholesky preconditioning, is capable of accurately solving the full-data KRR problem in $O(N^2)$ arithmetic operations, assuming sufficiently rapid polynomial decay of the kernel matrix eigenvalues. The second method, KRILL preconditioning, offers an accurate solution to a restricted version of the KRR problem involving $k \ll N$ selected data centers at a cost of $O((N + k^2) k \log k)$ operations. The proposed methods solve a broad range of KRR problems and overcome the failure modes of previous KRR preconditioners, making them ideal for practical applications.
Randomly pivoted Cholesky: Practical approximation of a kernel matrix with few entry evaluations
Jul 19, 2022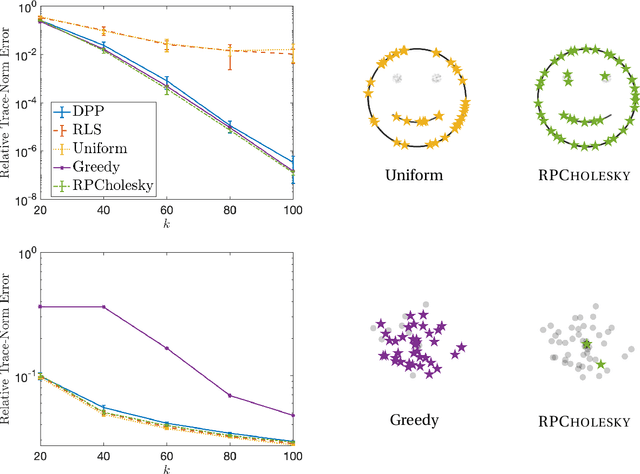
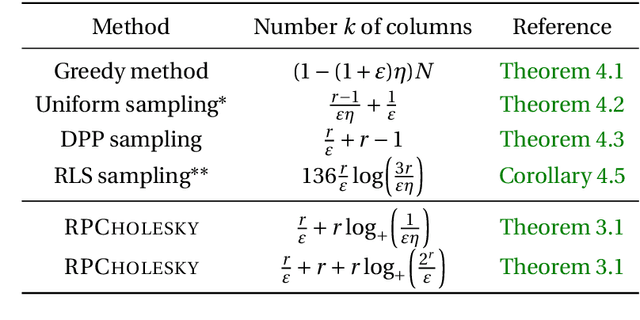
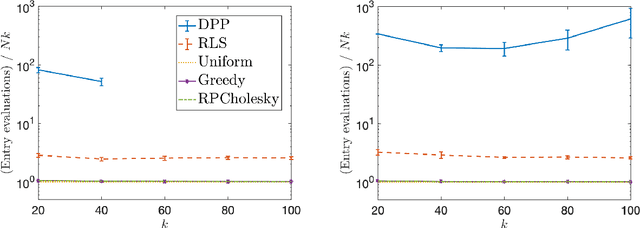
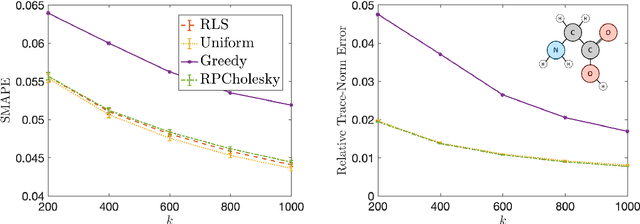
Randomly pivoted Cholesky (RPCholesky) is a natural algorithm for computing a rank-k approximation of an N x N positive semidefinite (psd) matrix. RPCholesky can be implemented with just a few lines of code. It requires only (k+1)N entry evaluations and O(k^2 N) additional arithmetic operations. This paper offers the first serious investigation of its experimental and theoretical behavior. Empirically, RPCholesky matches or improves on the performance of alternative algorithms for low-rank psd approximation. Furthermore, RPCholesky provably achieves near-optimal approximation guarantees. The simplicity, effectiveness, and robustness of this algorithm strongly support its use in scientific computing and machine learning applications.
Jackknife Variability Estimation For Randomized Matrix Computations
Jul 13, 2022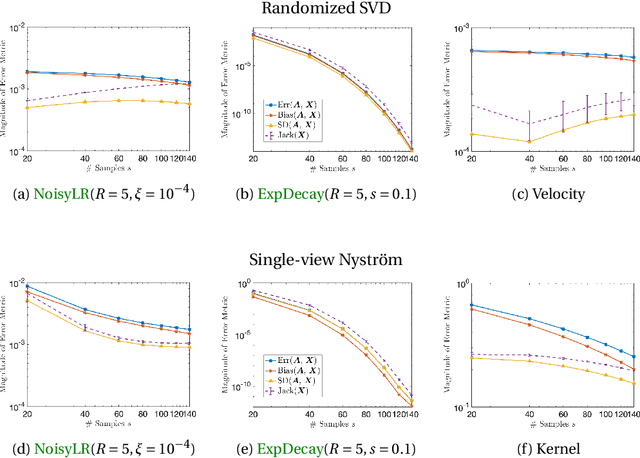
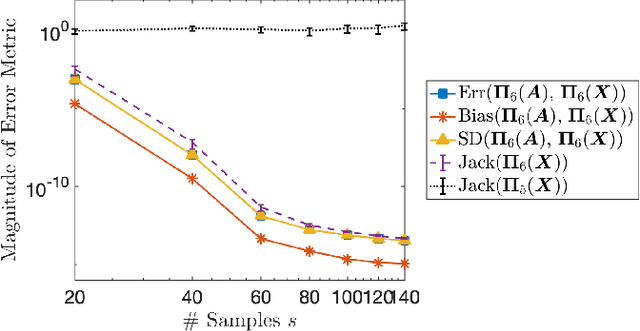
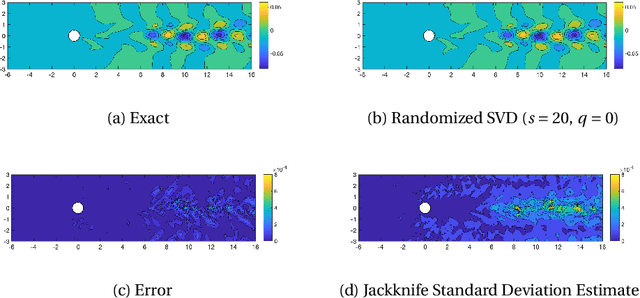
Randomized algorithms based on sketching have become a workhorse tool in low-rank matrix approximation. To use these algorithms safely in applications, they should be coupled with diagnostics to assess the quality of approximation. To meet this need, this paper proposes a jackknife resampling method to estimate the variability of the output of a randomized matrix computation. The variability estimate can recognize that a computation requires additional data or that the computation is intrinsically unstable. As examples, the paper studies jackknife estimates for two randomized low-rank matrix approximation algorithms. In each case, the operation count for the jackknife estimate is independent of the dimensions of the target matrix. In numerical experiments, the estimator accurately assesses variability and also provides an order-of-magnitude estimate of the mean-square error.
Learning to Forecast Dynamical Systems from Streaming Data
Sep 21, 2021
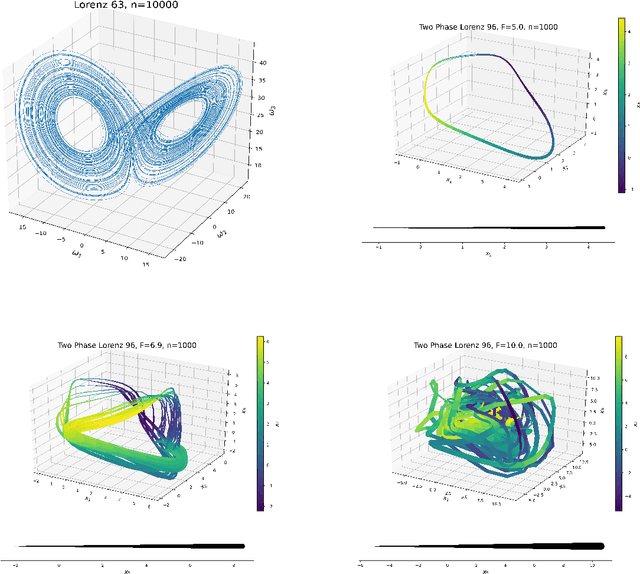
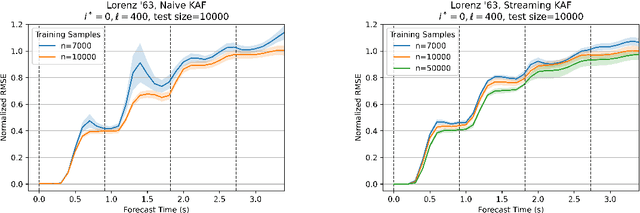

Kernel analog forecasting (KAF) is a powerful methodology for data-driven, non-parametric forecasting of dynamically generated time series data. This approach has a rigorous foundation in Koopman operator theory and it produces good forecasts in practice, but it suffers from the heavy computational costs common to kernel methods. This paper proposes a streaming algorithm for KAF that only requires a single pass over the training data. This algorithm dramatically reduces the costs of training and prediction without sacrificing forecasting skill. Computational experiments demonstrate that the streaming KAF method can successfully forecast several classes of dynamical systems (periodic, quasi-periodic, and chaotic) in both data-scarce and data-rich regimes. The overall methodology may have wider interest as a new template for streaming kernel regression.
Tensor Random Projection for Low Memory Dimension Reduction
Apr 30, 2021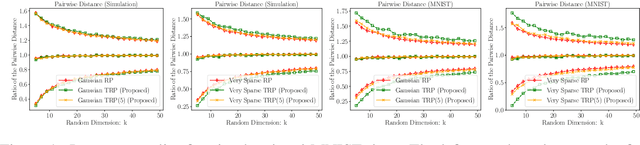

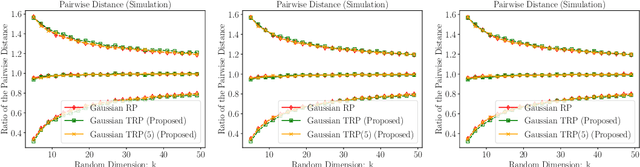
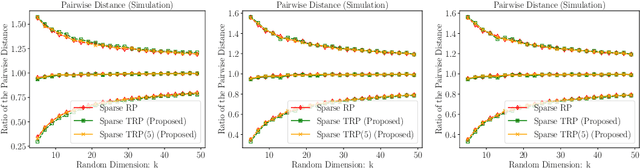
Random projections reduce the dimension of a set of vectors while preserving structural information, such as distances between vectors in the set. This paper proposes a novel use of row-product random matrices in random projection, where we call it Tensor Random Projection (TRP). It requires substantially less memory than existing dimension reduction maps. The TRP map is formed as the Khatri-Rao product of several smaller random projections, and is compatible with any base random projection including sparse maps, which enable dimension reduction with very low query cost and no floating point operations. We also develop a reduced variance extension. We provide a theoretical analysis of the bias and variance of the TRP, and a non-asymptotic error analysis for a TRP composed of two smaller maps. Experiments on both synthetic and MNIST data show that our method performs as well as conventional methods with substantially less storage.
An Optimal-Storage Approach to Semidefinite Programming using Approximate Complementarity
Feb 09, 2019
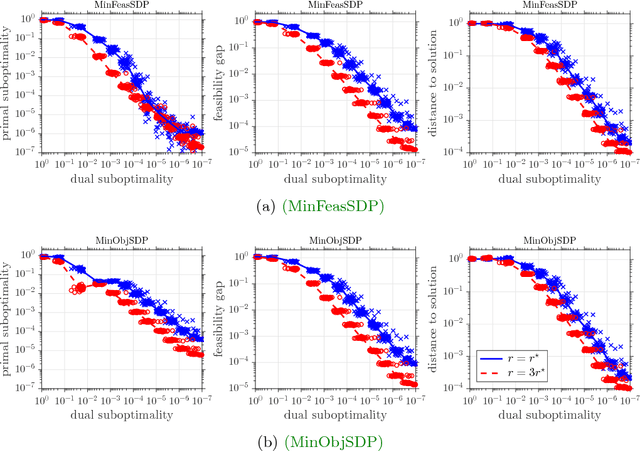

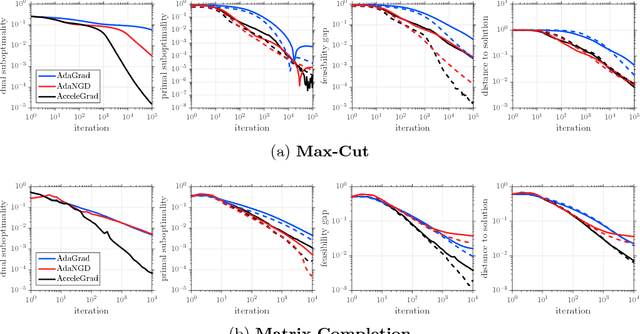
This paper develops a new storage-optimal algorithm that provably solves generic semidefinite programs (SDPs) in standard form. This method is particularly effective for weakly constrained SDPs. The key idea is to formulate an approximate complementarity principle: Given an approximate solution to the dual SDP, the primal SDP has an approximate solution whose range is contained in the eigenspace with small eigenvalues of the dual slack matrix. For weakly constrained SDPs, this eigenspace has very low dimension, so this observation significantly reduces the search space for the primal solution. This result suggests an algorithmic strategy that can be implemented with minimal storage: (1) Solve the dual SDP approximately; (2) compress the primal SDP to the eigenspace with small eigenvalues of the dual slack matrix; (3) solve the compressed primal SDP. The paper also provides numerical experiments showing that this approach is successful for a range of interesting large-scale SDPs.
Practical sketching algorithms for low-rank matrix approximation
Jan 02, 2018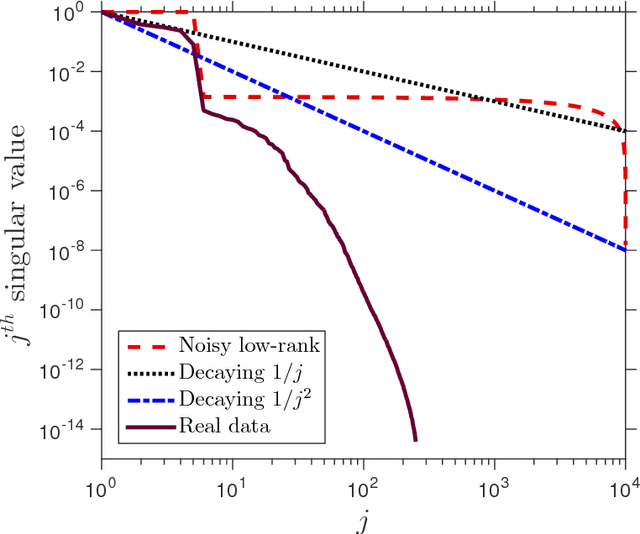
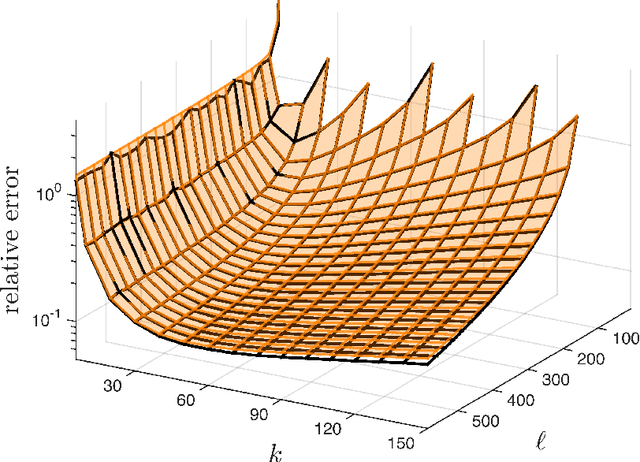
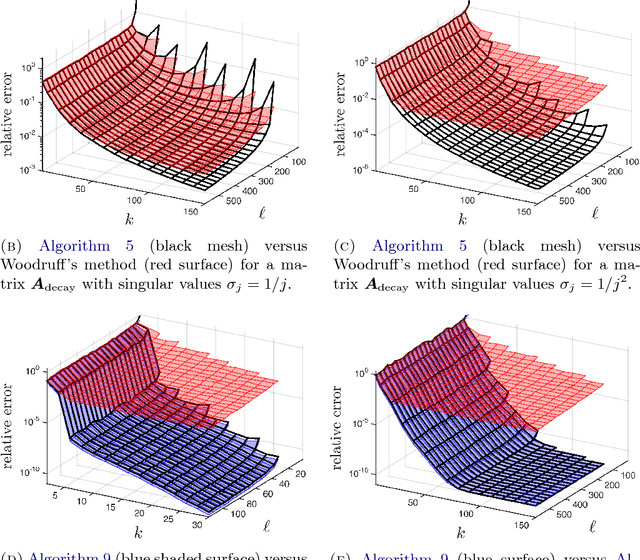
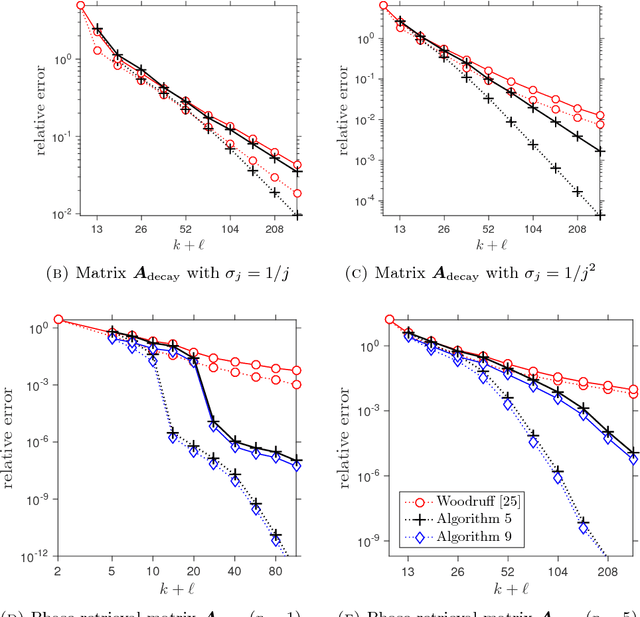
This paper describes a suite of algorithms for constructing low-rank approximations of an input matrix from a random linear image of the matrix, called a sketch. These methods can preserve structural properties of the input matrix, such as positive-semidefiniteness, and they can produce approximations with a user-specified rank. The algorithms are simple, accurate, numerically stable, and provably correct. Moreover, each method is accompanied by an informative error bound that allows users to select parameters a priori to achieve a given approximation quality. These claims are supported by numerical experiments with real and synthetic data.
Universality laws for randomized dimension reduction, with applications
Sep 17, 2017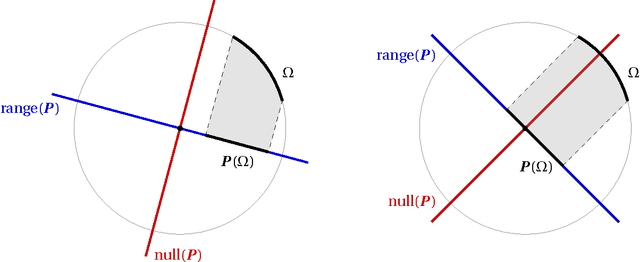
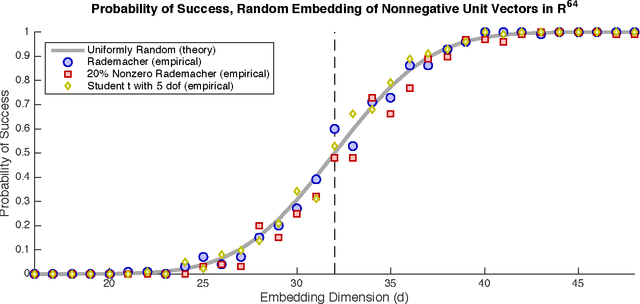
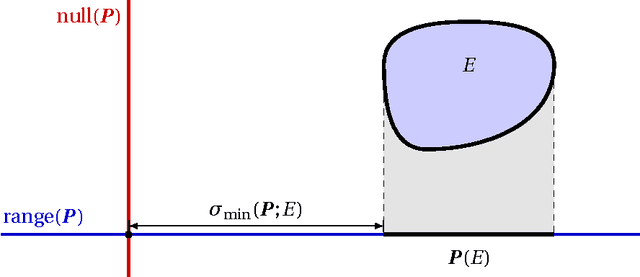
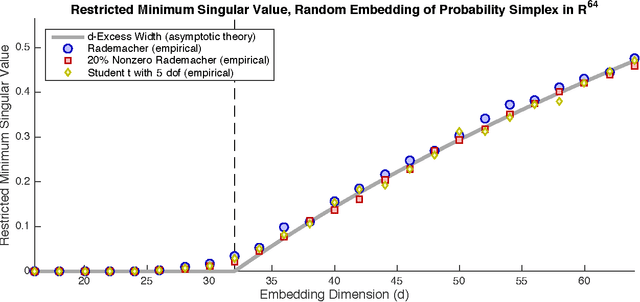
Dimension reduction is the process of embedding high-dimensional data into a lower dimensional space to facilitate its analysis. In the Euclidean setting, one fundamental technique for dimension reduction is to apply a random linear map to the data. This dimension reduction procedure succeeds when it preserves certain geometric features of the set. The question is how large the embedding dimension must be to ensure that randomized dimension reduction succeeds with high probability. This paper studies a natural family of randomized dimension reduction maps and a large class of data sets. It proves that there is a phase transition in the success probability of the dimension reduction map as the embedding dimension increases. For a given data set, the location of the phase transition is the same for all maps in this family. Furthermore, each map has the same stability properties, as quantified through the restricted minimum singular value. These results can be viewed as new universality laws in high-dimensional stochastic geometry. Universality laws for randomized dimension reduction have many applications in applied mathematics, signal processing, and statistics. They yield design principles for numerical linear algebra algorithms, for compressed sensing measurement ensembles, and for random linear codes. Furthermore, these results have implications for the performance of statistical estimation methods under a large class of random experimental designs.
Fixed-Rank Approximation of a Positive-Semidefinite Matrix from Streaming Data
Jun 18, 2017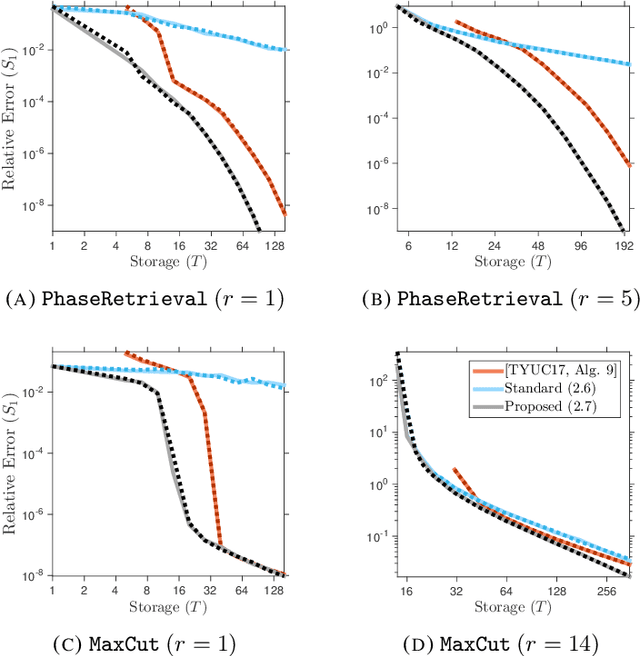
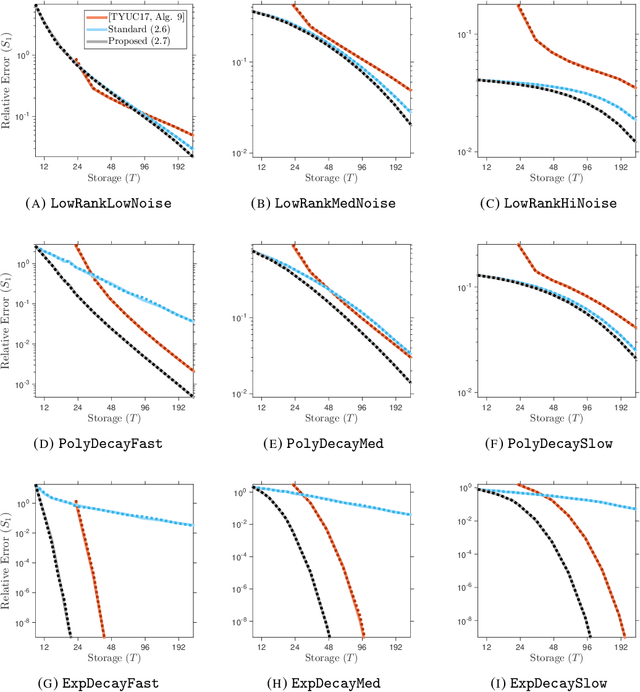
Several important applications, such as streaming PCA and semidefinite programming, involve a large-scale positive-semidefinite (psd) matrix that is presented as a sequence of linear updates. Because of storage limitations, it may only be possible to retain a sketch of the psd matrix. This paper develops a new algorithm for fixed-rank psd approximation from a sketch. The approach combines the Nystrom approximation with a novel mechanism for rank truncation. Theoretical analysis establishes that the proposed method can achieve any prescribed relative error in the Schatten 1-norm and that it exploits the spectral decay of the input matrix. Computer experiments show that the proposed method dominates alternative techniques for fixed-rank psd matrix approximation across a wide range of examples.