 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Reduction in Communication Rounds for Non-Smooth Convex Federated Learning
Mar 27, 2025

Multiple local steps are key to communication-efficient federated learning. However, theoretical guarantees for such algorithms, without data heterogeneity-bounding assumptions, have been lacking in general non-smooth convex problems. Leveraging projection-efficient optimization methods, we propose FedMLS, a federated learning algorithm with provable improvements from multiple local steps. FedMLS attains an $\epsilon$-suboptimal solution in $\mathcal{O}(1/\epsilon)$ communication rounds, requiring a total of $\mathcal{O}(1/\epsilon^2)$ stochastic subgradient oracle calls.
Revisiting Frank-Wolfe for Structured Nonconvex Optimization
Mar 11, 2025We introduce a new projection-free (Frank-Wolfe) method for optimizing structured nonconvex functions that are expressed as a difference of two convex functions. This problem class subsumes smooth nonconvex minimization, positioning our method as a promising alternative to the classical Frank-Wolfe algorithm. DC decompositions are not unique; by carefully selecting a decomposition, we can better exploit the problem structure, improve computational efficiency, and adapt to the underlying problem geometry to find better local solutions. We prove that the proposed method achieves a first-order stationary point in $O(1/\epsilon^2)$ iterations, matching the complexity of the standard Frank-Wolfe algorithm for smooth nonconvex minimization in general. Specific decompositions can, for instance, yield a gradient-efficient variant that requires only $O(1/\epsilon)$ calls to the gradient oracle. Finally, we present numerical experiments demonstrating the effectiveness of the proposed method compared to the standard Frank-Wolfe algorithm.
Implicit Bias in Matrix Factorization and its Explicit Realization in a New Architecture
Jan 27, 2025



Gradient descent for matrix factorization is known to exhibit an implicit bias toward approximately low-rank solutions. While existing theories often assume the boundedness of iterates, empirically the bias persists even with unbounded sequences. We thus hypothesize that implicit bias is driven by divergent dynamics markedly different from the convergent dynamics for data fitting. Using this perspective, we introduce a new factorization model: $X\approx UDV^\top$, where $U$ and $V$ are constrained within norm balls, while $D$ is a diagonal factor allowing the model to span the entire search space. Our experiments reveal that this model exhibits a strong implicit bias regardless of initialization and step size, yielding truly (rather than approximately) low-rank solutions. Furthermore, drawing parallels between matrix factorization and neural networks, we propose a novel neural network model featuring constrained layers and diagonal components. This model achieves strong performance across various regression and classification tasks while finding low-rank solutions, resulting in efficient and lightweight networks.
Convex Formulations for Training Two-Layer ReLU Neural Networks
Oct 29, 2024



Solving non-convex, NP-hard optimization problems is crucial for training machine learning models, including neural networks. However, non-convexity often leads to black-box machine learning models with unclear inner workings. While convex formulations have been used for verifying neural network robustness, their application to training neural networks remains less explored. In response to this challenge, we reformulate the problem of training infinite-width two-layer ReLU networks as a convex completely positive program in a finite-dimensional (lifted) space. Despite the convexity, solving this problem remains NP-hard due to the complete positivity constraint. To overcome this challenge, we introduce a semidefinite relaxation that can be solved in polynomial time. We then experimentally evaluate the tightness of this relaxation, demonstrating its competitive performance in test accuracy across a range of classification tasks.
Federated Frank-Wolfe Algorithm
Aug 19, 2024Federated learning (FL) has gained a lot of attention in recent years for building privacy-preserving collaborative learning systems. However, FL algorithms for constrained machine learning problems are still limited, particularly when the projection step is costly. To this end, we propose a Federated Frank-Wolfe Algorithm (FedFW). FedFW features data privacy, low per-iteration cost, and communication of sparse signals. In the deterministic setting, FedFW achieves an $\varepsilon$-suboptimal solution within $O(\varepsilon^{-2})$ iterations for smooth and convex objectives, and $O(\varepsilon^{-3})$ iterations for smooth but non-convex objectives. Furthermore, we present a stochastic variant of FedFW and show that it finds a solution within $O(\varepsilon^{-3})$ iterations in the convex setting. We demonstrate the empirical performance of FedFW on several machine learning tasks.
Personalized Multi-tier Federated Learning
Jul 19, 2024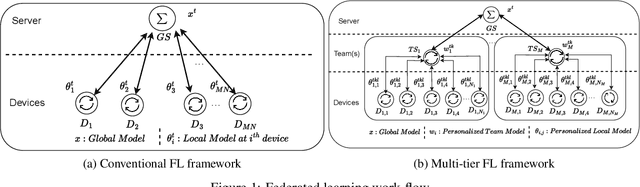
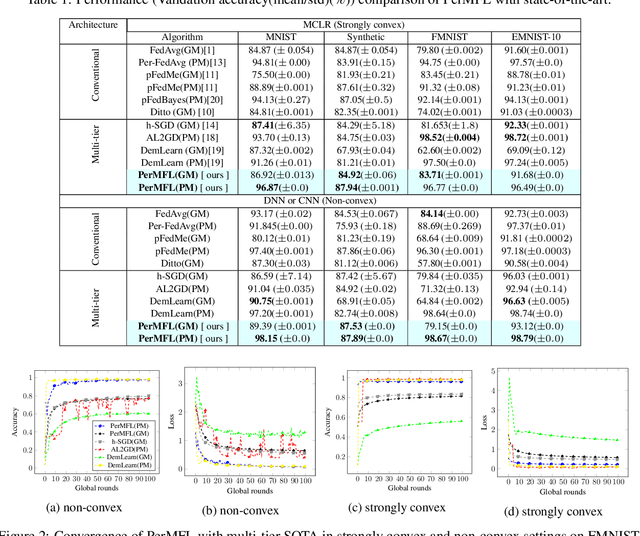

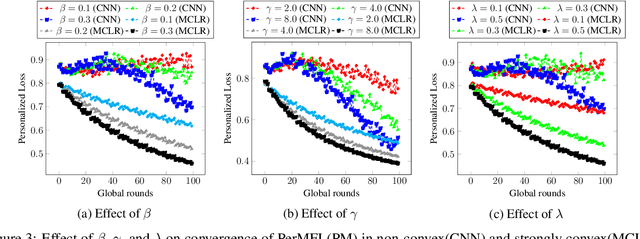
The key challenge of personalized federated learning (PerFL) is to capture the statistical heterogeneity properties of data with inexpensive communications and gain customized performance for participating devices. To address these, we introduced personalized federated learning in multi-tier architecture (PerMFL) to obtain optimized and personalized local models when there are known team structures across devices. We provide theoretical guarantees of PerMFL, which offers linear convergence rates for smooth strongly convex problems and sub-linear convergence rates for smooth non-convex problems. We conduct numerical experiments demonstrating the robust empirical performance of PerMFL, outperforming the state-of-the-art in multiple personalized federated learning tasks.
A Variational Perspective on High-Resolution ODEs
Nov 03, 2023


We consider unconstrained minimization of smooth convex functions. We propose a novel variational perspective using forced Euler-Lagrange equation that allows for studying high-resolution ODEs. Through this, we obtain a faster convergence rate for gradient norm minimization using Nesterov's accelerated gradient method. Additionally, we show that Nesterov's method can be interpreted as a rate-matching discretization of an appropriately chosen high-resolution ODE. Finally, using the results from the new variational perspective, we propose a stochastic method for noisy gradients. Several numerical experiments compare and illustrate our stochastic algorithm with state of the art methods.
Q-FW: A Hybrid Classical-Quantum Frank-Wolfe for Quadratic Binary Optimization
Mar 23, 2022

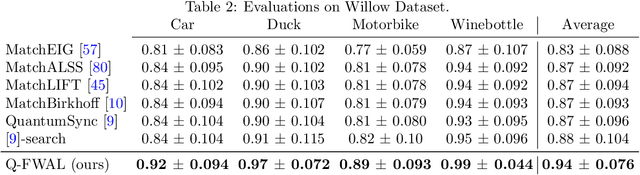
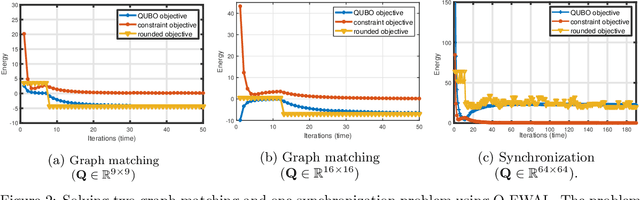
We present a hybrid classical-quantum framework based on the Frank-Wolfe algorithm, Q-FW, for solving quadratic, linearly-constrained, binary optimization problems on quantum annealers (QA). The computational premise of quantum computers has cultivated the re-design of various existing vision problems into quantum-friendly forms. Experimental QA realizations can solve a particular non-convex problem known as the quadratic unconstrained binary optimization (QUBO). Yet a naive-QUBO cannot take into account the restrictions on the parameters. To introduce additional structure in the parameter space, researchers have crafted ad-hoc solutions incorporating (linear) constraints in the form of regularizers. However, this comes at the expense of a hyper-parameter, balancing the impact of regularization. To date, a true constrained solver of quadratic binary optimization (QBO) problems has lacked. Q-FW first reformulates constrained-QBO as a copositive program (CP), then employs Frank-Wolfe iterations to solve CP while satisfying linear (in)equality constraints. This procedure unrolls the original constrained-QBO into a set of unconstrained QUBOs all of which are solved, in a sequel, on a QA. We use D-Wave Advantage QA to conduct synthetic and real experiments on two important computer vision problems, graph matching and permutation synchronization, which demonstrate that our approach is effective in alleviating the need for an explicit regularization coefficient.
Faster One-Sample Stochastic Conditional Gradient Method for Composite Convex Minimization
Feb 26, 2022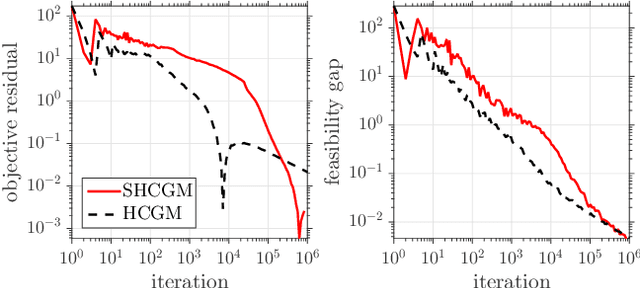

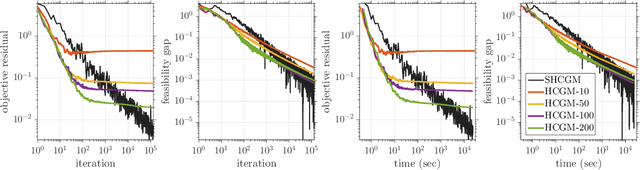
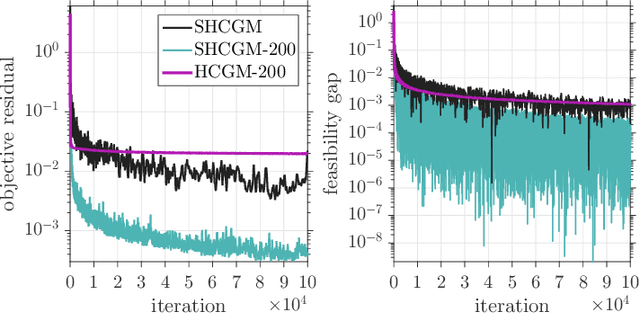
We propose a stochastic conditional gradient method (CGM) for minimizing convex finite-sum objectives formed as a sum of smooth and non-smooth terms. Existing CGM variants for this template either suffer from slow convergence rates, or require carefully increasing the batch size over the course of the algorithm's execution, which leads to computing full gradients. In contrast, the proposed method, equipped with a stochastic average gradient (SAG) estimator, requires only one sample per iteration. Nevertheless, it guarantees fast convergence rates on par with more sophisticated variance reduction techniques. In applications we put special emphasis on problems with a large number of separable constraints. Such problems are prevalent among semidefinite programming (SDP) formulations arising in machine learning and theoretical computer science. We provide numerical experiments on matrix completion, unsupervised clustering, and sparsest-cut SDPs.
An Optimal-Storage Approach to Semidefinite Programming using Approximate Complementarity
Feb 09, 2019
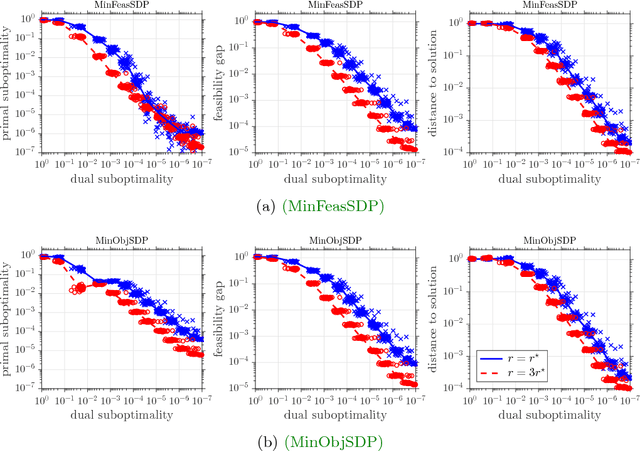

This paper develops a new storage-optimal algorithm that provably solves generic semidefinite programs (SDPs) in standard form. This method is particularly effective for weakly constrained SDPs. The key idea is to formulate an approximate complementarity principle: Given an approximate solution to the dual SDP, the primal SDP has an approximate solution whose range is contained in the eigenspace with small eigenvalues of the dual slack matrix. For weakly constrained SDPs, this eigenspace has very low dimension, so this observation significantly reduces the search space for the primal solution. This result suggests an algorithmic strategy that can be implemented with minimal storage: (1) Solve the dual SDP approximately; (2) compress the primal SDP to the eigenspace with small eigenvalues of the dual slack matrix; (3) solve the compressed primal SDP. The paper also provides numerical experiments showing that this approach is successful for a range of interesting large-scale SDPs.