 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinearization Algorithms for Fully Composite Optimization
Feb 24, 2023In this paper, we study first-order algorithms for solving fully composite optimization problems over bounded sets. We treat the differentiable and non-differentiable parts of the objective separately, linearizing only the smooth components. This provides us with new generalizations of the classical and accelerated Frank-Wolfe methods, that are applicable to non-differentiable problems whenever we can access the structure of the objective. We prove global complexity bounds for our algorithms that are optimal in several settings.
Faster One-Sample Stochastic Conditional Gradient Method for Composite Convex Minimization
Feb 26, 2022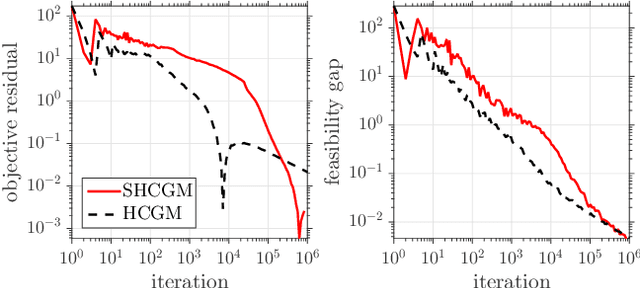

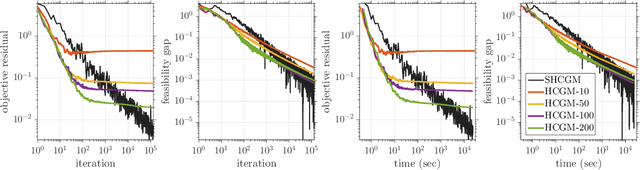
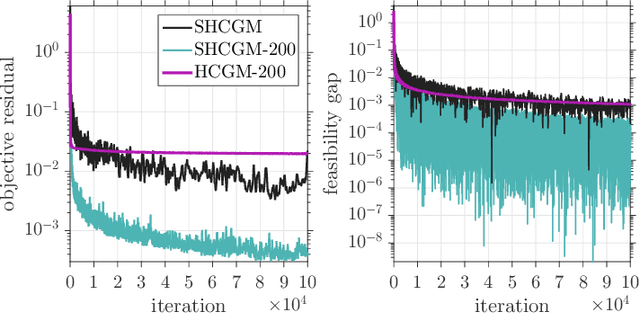
We propose a stochastic conditional gradient method (CGM) for minimizing convex finite-sum objectives formed as a sum of smooth and non-smooth terms. Existing CGM variants for this template either suffer from slow convergence rates, or require carefully increasing the batch size over the course of the algorithm's execution, which leads to computing full gradients. In contrast, the proposed method, equipped with a stochastic average gradient (SAG) estimator, requires only one sample per iteration. Nevertheless, it guarantees fast convergence rates on par with more sophisticated variance reduction techniques. In applications we put special emphasis on problems with a large number of separable constraints. Such problems are prevalent among semidefinite programming (SDP) formulations arising in machine learning and theoretical computer science. We provide numerical experiments on matrix completion, unsupervised clustering, and sparsest-cut SDPs.
A first-order primal-dual method with adaptivity to local smoothness
Oct 28, 2021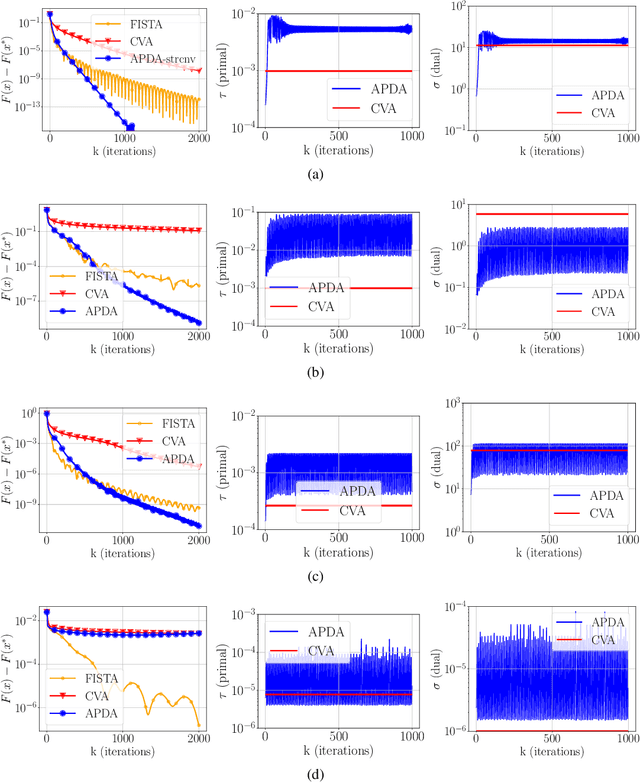
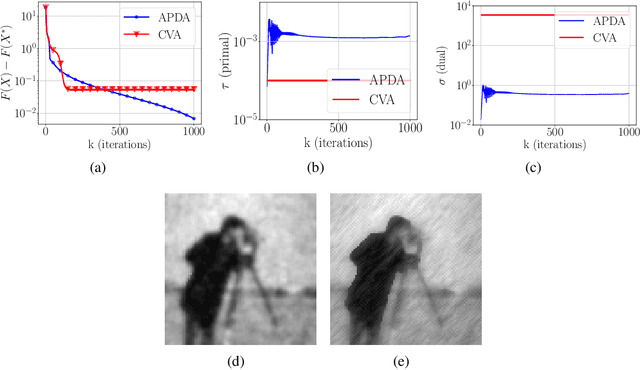
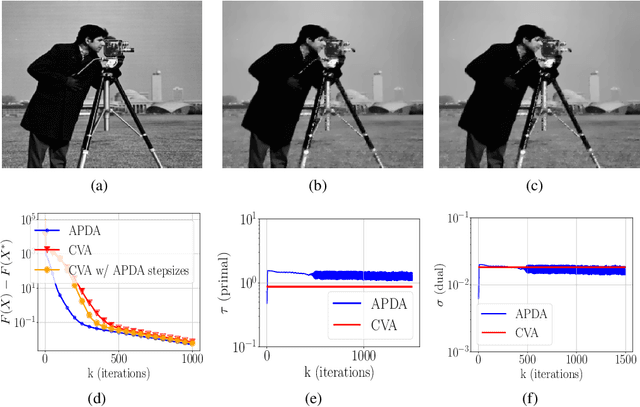
We consider the problem of finding a saddle point for the convex-concave objective $\min_x \max_y f(x) + \langle Ax, y\rangle - g^*(y)$, where $f$ is a convex function with locally Lipschitz gradient and $g$ is convex and possibly non-smooth. We propose an adaptive version of the Condat-V\~u algorithm, which alternates between primal gradient steps and dual proximal steps. The method achieves stepsize adaptivity through a simple rule involving $\|A\|$ and the norm of recently computed gradients of $f$. Under standard assumptions, we prove an $\mathcal{O}(k^{-1})$ ergodic convergence rate. Furthermore, when $f$ is also locally strongly convex and $A$ has full row rank we show that our method converges with a linear rate. Numerical experiments are provided for illustrating the practical performance of the algorithm.
Conditional gradient methods for stochastically constrained convex minimization
Jul 07, 2020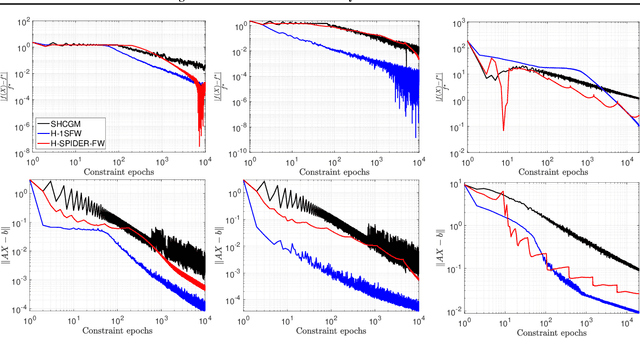
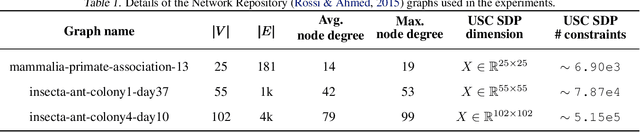
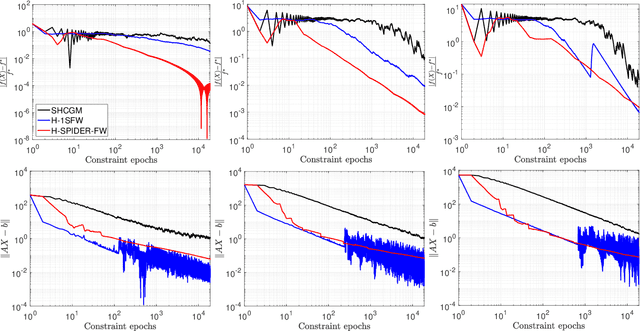
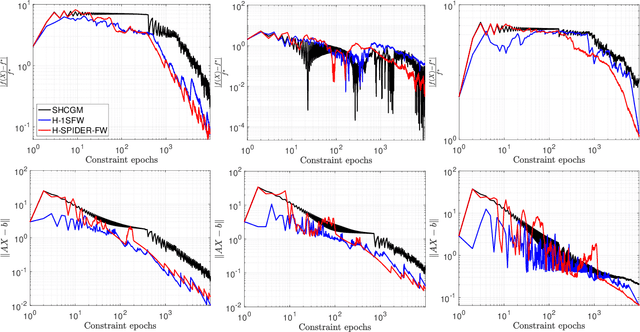
We propose two novel conditional gradient-based methods for solving structured stochastic convex optimization problems with a large number of linear constraints. Instances of this template naturally arise from SDP-relaxations of combinatorial problems, which involve a number of constraints that is polynomial in the problem dimension. The most important feature of our framework is that only a subset of the constraints is processed at each iteration, thus gaining a computational advantage over prior works that require full passes. Our algorithms rely on variance reduction and smoothing used in conjunction with conditional gradient steps, and are accompanied by rigorous convergence guarantees. Preliminary numerical experiments are provided for illustrating the practical performance of the methods.