 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLOS: An Infrastructure for Automated Software Performance Engineering
Jun 04, 2020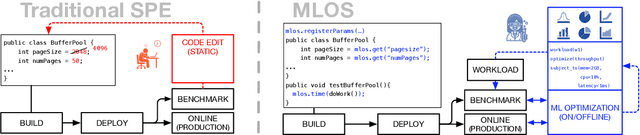
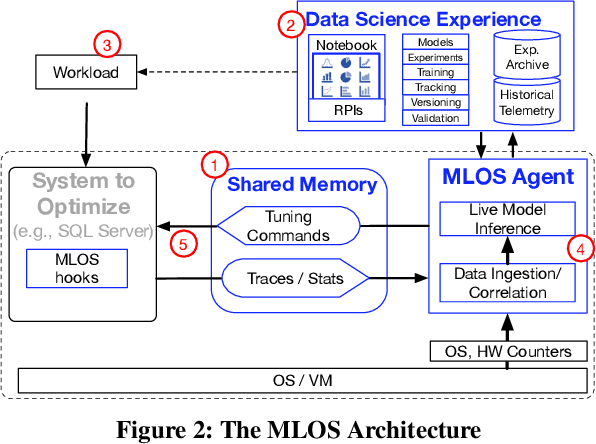
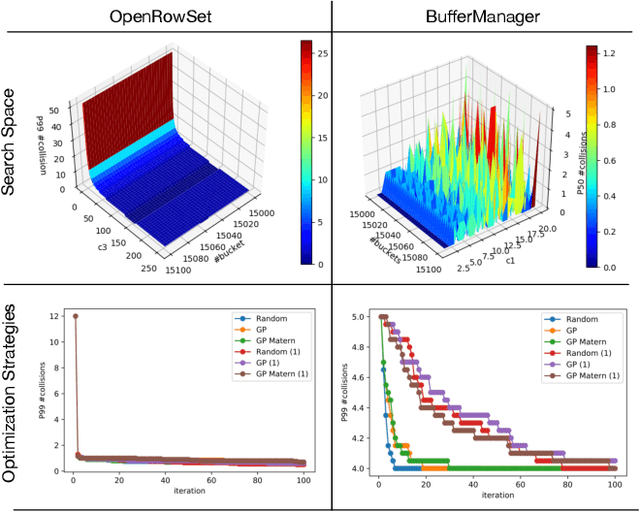
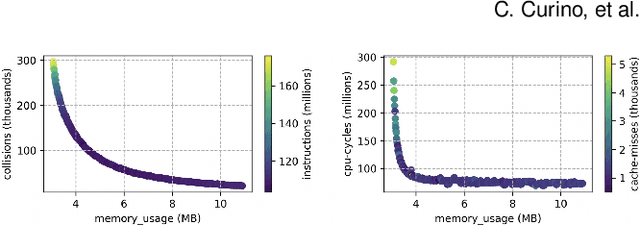
Developing modern systems software is a complex task that combines business logic programming and Software Performance Engineering (SPE). The later is an experimental and labor-intensive activity focused on optimizing the system for a given hardware, software, and workload (hw/sw/wl) context. Today's SPE is performed during build/release phases by specialized teams, and cursed by: 1) lack of standardized and automated tools, 2) significant repeated work as hw/sw/wl context changes, 3) fragility induced by a "one-size-fit-all" tuning (where improvements on one workload or component may impact others). The net result: despite costly investments, system software is often outside its optimal operating point - anecdotally leaving 30% to 40% of performance on the table. The recent developments in Data Science (DS) hints at an opportunity: combining DS tooling and methodologies with a new developer experience to transform the practice of SPE. In this paper we present: MLOS, an ML-powered infrastructure and methodology to democratize and automate Software Performance Engineering. MLOS enables continuous, instance-level, robust, and trackable systems optimization. MLOS is being developed and employed within Microsoft to optimize SQL Server performance. Early results indicated that component-level optimizations can lead to 20%-90% improvements when custom-tuning for a specific hw/sw/wl, hinting at a significant opportunity. However, several research challenges remain that will require community involvement. To this end, we are in the process of open-sourcing the MLOS core infrastructure, and we are engaging with academic institutions to create an educational program around Software 2.0 and MLOS ideas.
Learning How To Learn Within An LSM-based Key-Value Store
May 28, 2020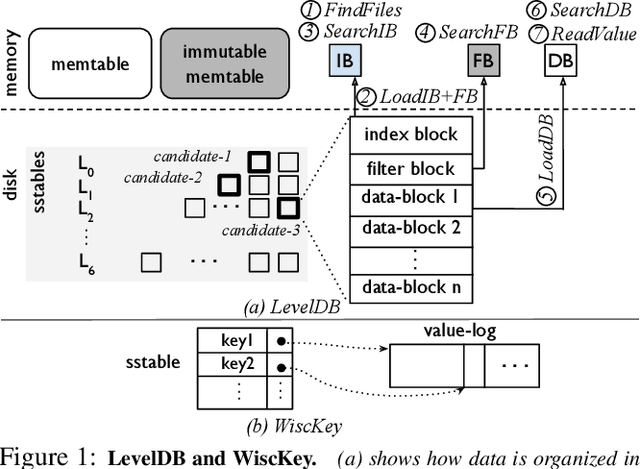
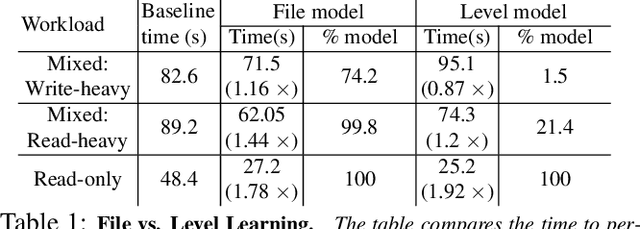
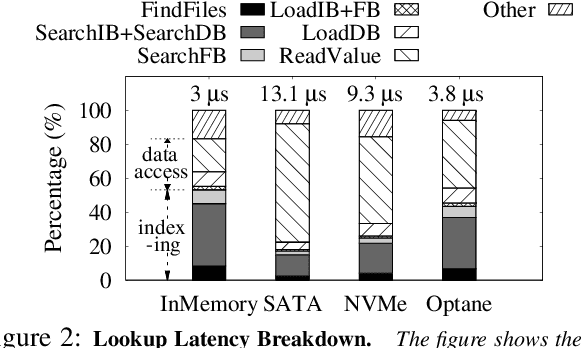
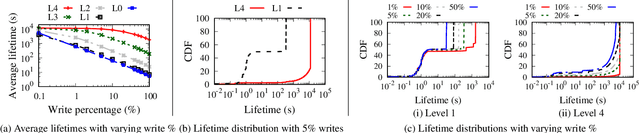
We introduce BOURBON, a log-structured merge (LSM) tree that utilizes machine learning to provide fast lookups. We base the design and implementation of BOURBON on empirically grounded principles that we derive through careful analysis of LSM design. BOURBON employs greedy piecewise linear regression to learn key distributions, enabling fast lookup with minimal computation, and applies a cost-benefit strategy to decide when learning will be worthwhile. Through a series of experiments on both synthetic and real-world datasets, we show that BOURBON improves lookup performance by 1.23x-1.78x as compared to state-of-the-art production LSMs.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019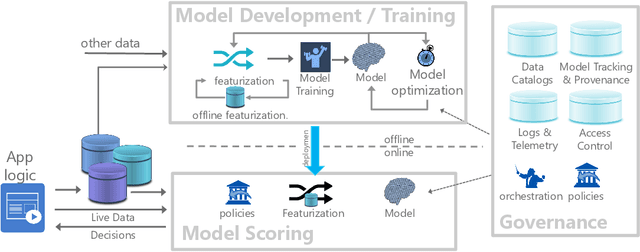
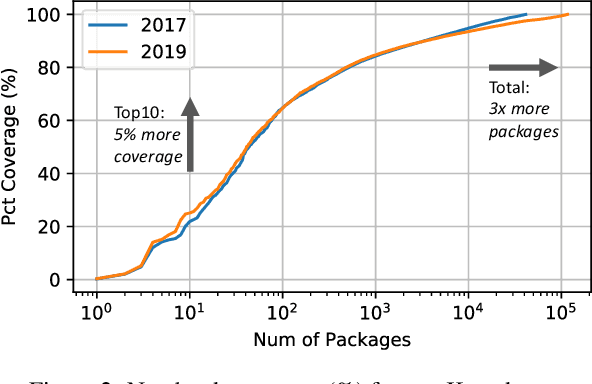
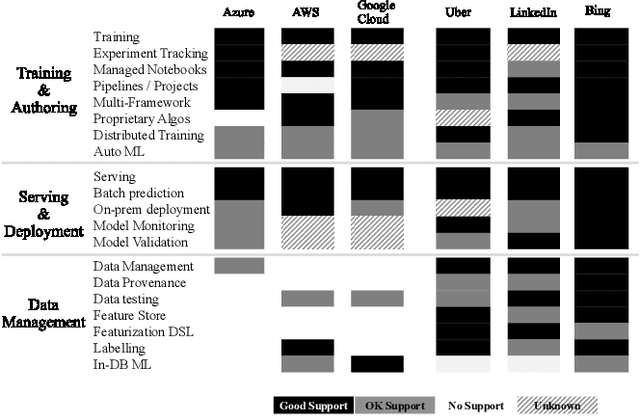
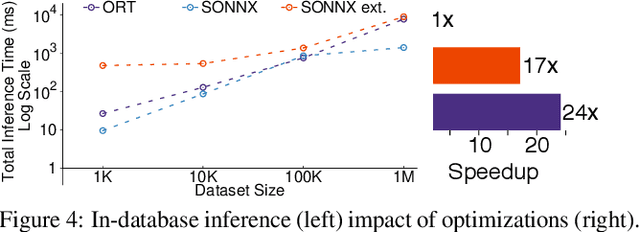
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.