 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on World Models Is Not Merely Injecting World Knowledge into Specific Tasks
Feb 02, 2026World models have emerged as a critical frontier in AI research, aiming to enhance large models by infusing them with physical dynamics and world knowledge. The core objective is to enable agents to understand, predict, and interact with complex environments. However, current research landscape remains fragmented, with approaches predominantly focused on injecting world knowledge into isolated tasks, such as visual prediction, 3D estimation, or symbol grounding, rather than establishing a unified definition or framework. While these task-specific integrations yield performance gains, they often lack the systematic coherence required for holistic world understanding. In this paper, we analyze the limitations of such fragmented approaches and propose a unified design specification for world models. We suggest that a robust world model should not be a loose collection of capabilities but a normative framework that integrally incorporates interaction, perception, symbolic reasoning, and spatial representation. This work aims to provide a structured perspective to guide future research toward more general, robust, and principled models of the world.
CoF-T2I: Video Models as Pure Visual Reasoners for Text-to-Image Generation
Jan 15, 2026Recent video generation models have revealed the emergence of Chain-of-Frame (CoF) reasoning, enabling frame-by-frame visual inference. With this capability, video models have been successfully applied to various visual tasks (e.g., maze solving, visual puzzles). However, their potential to enhance text-to-image (T2I) generation remains largely unexplored due to the absence of a clearly defined visual reasoning starting point and interpretable intermediate states in the T2I generation process. To bridge this gap, we propose CoF-T2I, a model that integrates CoF reasoning into T2I generation via progressive visual refinement, where intermediate frames act as explicit reasoning steps and the final frame is taken as output. To establish such an explicit generation process, we curate CoF-Evol-Instruct, a dataset of CoF trajectories that model the generation process from semantics to aesthetics. To further improve quality and avoid motion artifacts, we enable independent encoding operation for each frame. Experiments show that CoF-T2I significantly outperforms the base video model and achieves competitive performance on challenging benchmarks, reaching 0.86 on GenEval and 7.468 on Imagine-Bench. These results indicate the substantial promise of video models for advancing high-quality text-to-image generation.
AdaptMol: Adaptive Fusion from Sequence String to Topological Structure for Few-shot Drug Discovery
May 17, 2025



Accurate molecular property prediction (MPP) is a critical step in modern drug development. However, the scarcity of experimental validation data poses a significant challenge to AI-driven research paradigms. Under few-shot learning scenarios, the quality of molecular representations directly dictates the theoretical upper limit of model performance. We present AdaptMol, a prototypical network integrating Adaptive multimodal fusion for Molecular representation. This framework employs a dual-level attention mechanism to dynamically integrate global and local molecular features derived from two modalities: SMILES sequences and molecular graphs. (1) At the local level, structural features such as atomic interactions and substructures are extracted from molecular graphs, emphasizing fine-grained topological information; (2) At the global level, the SMILES sequence provides a holistic representation of the molecule. To validate the necessity of multimodal adaptive fusion, we propose an interpretable approach based on identifying molecular active substructures to demonstrate that multimodal adaptive fusion can efficiently represent molecules. Extensive experiments on three commonly used benchmarks under 5-shot and 10-shot settings demonstrate that AdaptMol achieves state-of-the-art performance in most cases. The rationale-extracted method guides the fusion of two modalities and highlights the importance of both modalities.
NsBM-GAT: A Non-stationary Block Maximum and Graph Attention Framework for General Traffic Crash Risk Prediction
Mar 06, 2025



Accurate prediction of traffic crash risks for individual vehicles is essential for enhancing vehicle safety. While significant attention has been given to traffic crash risk prediction, existing studies face two main challenges: First, due to the scarcity of individual vehicle data before crashes, most models rely on hypothetical scenarios deemed dangerous by researchers. This raises doubts about their applicability to actual pre-crash conditions. Second, some crash risk prediction frameworks were learned from dashcam videos. Although such videos capture the pre-crash behavior of individual vehicles, they often lack critical information about the movements of surrounding vehicles. However, the interaction between a vehicle and its surrounding vehicles is highly influential in crash occurrences. To overcome these challenges, we propose a novel non-stationary extreme value theory (EVT), where the covariate function is optimized in a nonlinear fashion using a graph attention network. The EVT component incorporates the stochastic nature of crashes through probability distribution, which enhances model interpretability. Notably, the nonlinear covariate function enables the model to capture the interactive behavior between the target vehicle and its multiple surrounding vehicles, facilitating crash risk prediction across different driving tasks. We train and test our model using 100 sets of vehicle trajectory data before real crashes, collected via drones over three years from merging and weaving segments. We demonstrate that our model successfully learns micro-level precursors of crashes and fits a more accurate distribution with the aid of the nonlinear covariate function. Our experiments on the testing dataset show that the proposed model outperforms existing models by providing more accurate predictions for both rear-end and sideswipe crashes simultaneously.
A Novel Compact LLM Framework for Local, High-Privacy EHR Data Applications
Dec 03, 2024Large Language Models (LLMs) have shown impressive capabilities in natural language processing, yet their use in sensitive domains like healthcare, particularly with Electronic Health Records (EHR), faces significant challenges due to privacy concerns and limited computational resources. This paper presents a compact LLM framework designed for local deployment in settings with strict privacy requirements and limited access to high-performance GPUs. We introduce a novel preprocessing technique that uses information extraction methods, e.g., regular expressions, to filter and emphasize critical information in clinical notes, enhancing the performance of smaller LLMs on EHR data. Our framework is evaluated using zero-shot and few-shot learning paradigms on both private and publicly available (MIMIC-IV) datasets, and we also compare its performance with fine-tuned LLMs on the MIMIC-IV dataset. The results demonstrate that our preprocessing approach significantly boosts the prediction accuracy of smaller LLMs, making them suitable for high-privacy, resource-constrained applications. This study offers valuable insights into optimizing LLM performance for sensitive, data-intensive tasks while addressing computational and privacy limitations.
Learning How To Learn Within An LSM-based Key-Value Store
May 28, 2020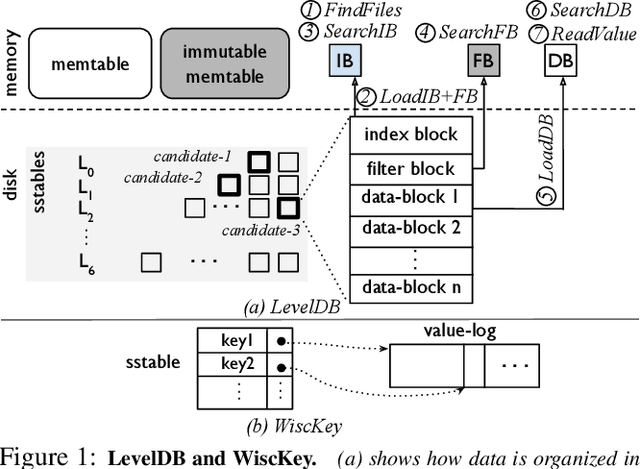
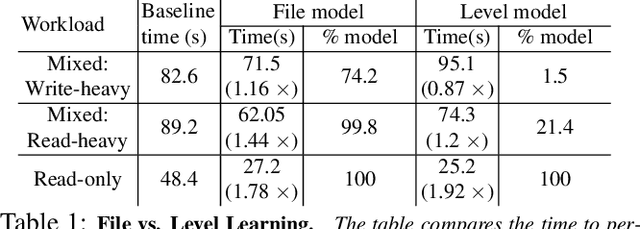
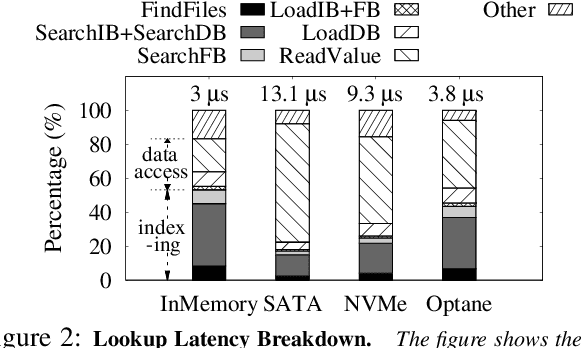
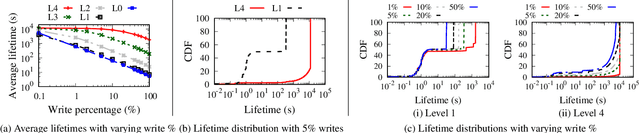
We introduce BOURBON, a log-structured merge (LSM) tree that utilizes machine learning to provide fast lookups. We base the design and implementation of BOURBON on empirically grounded principles that we derive through careful analysis of LSM design. BOURBON employs greedy piecewise linear regression to learn key distributions, enabling fast lookup with minimal computation, and applies a cost-benefit strategy to decide when learning will be worthwhile. Through a series of experiments on both synthetic and real-world datasets, we show that BOURBON improves lookup performance by 1.23x-1.78x as compared to state-of-the-art production LSMs.