 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching Clinical Data Using Generative AI
May 30, 2025Artificial Intelligence (AI) is making a major impact on healthcare, particularly through its application in natural language processing (NLP) and predictive analytics. The healthcare sector has increasingly adopted AI for tasks such as clinical data analysis and medical code assignment. However, searching for clinical information in large and often unorganized datasets remains a manual and error-prone process. Assisting this process with automations can help physicians improve their operational productivity significantly. In this paper, we present a generative AI approach, coined SearchAI, to enhance the accuracy and efficiency of searching clinical data. Unlike traditional code assignment, which is a one-to-one problem, clinical data search is a one-to-many problem, i.e., a given search query can map to a family of codes. Healthcare professionals typically search for groups of related diseases, drugs, or conditions that map to many codes, and therefore, they need search tools that can handle keyword synonyms, semantic variants, and broad open-ended queries. SearchAI employs a hierarchical model that respects the coding hierarchy and improves the traversal of relationships from parent to child nodes. SearchAI navigates these hierarchies predictively and ensures that all paths are reachable without losing any relevant nodes. To evaluate the effectiveness of SearchAI, we conducted a series of experiments using both public and production datasets. Our results show that SearchAI outperforms default hierarchical traversals across several metrics, including accuracy, robustness, performance, and scalability. SearchAI can help make clinical data more accessible, leading to streamlined workflows, reduced administrative burden, and enhanced coding and diagnostic accuracy.
Deploying a Steered Query Optimizer in Production at Microsoft
Oct 24, 2022
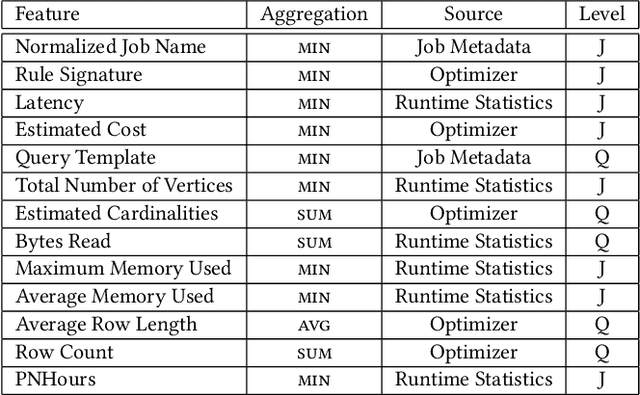
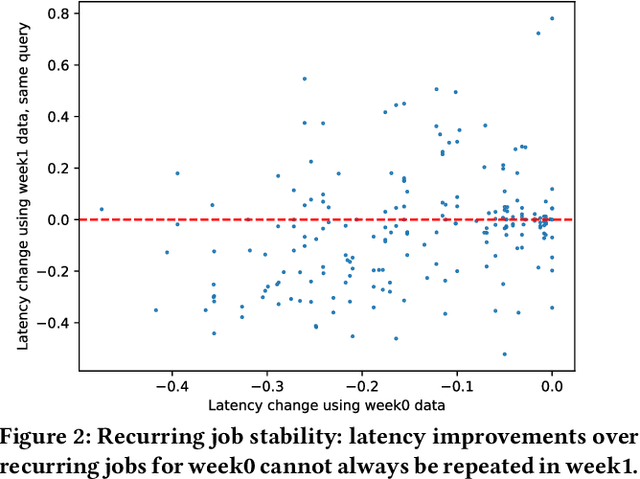
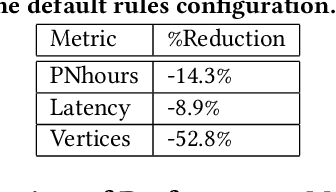
Modern analytical workloads are highly heterogeneous and massively complex, making generic query optimizers untenable for many customers and scenarios. As a result, it is important to specialize these optimizers to instances of the workloads. In this paper, we continue a recent line of work in steering a query optimizer towards better plans for a given workload, and make major strides in pushing previous research ideas to production deployment. Along the way we solve several operational challenges including, making steering actions more manageable, keeping the costs of steering within budget, and avoiding unexpected performance regressions in production. Our resulting system, QQ-advisor, essentially externalizes the query planner to a massive offline pipeline for better exploration and specialization. We discuss various aspects of our design and show detailed results over production SCOPE workloads at Microsoft, where the system is currently enabled by default.
Optimal Resource Allocation for Serverless Queries
Jul 19, 2021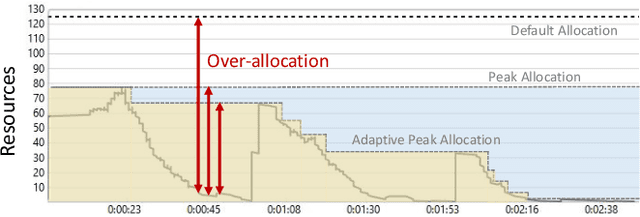
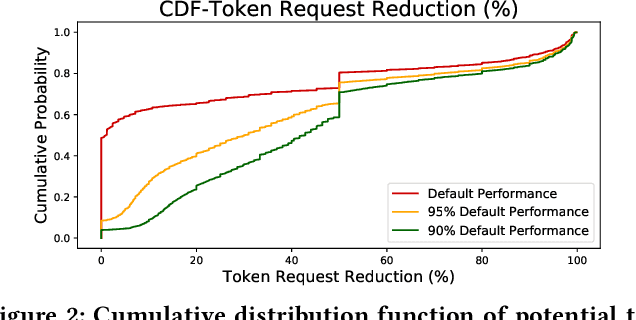

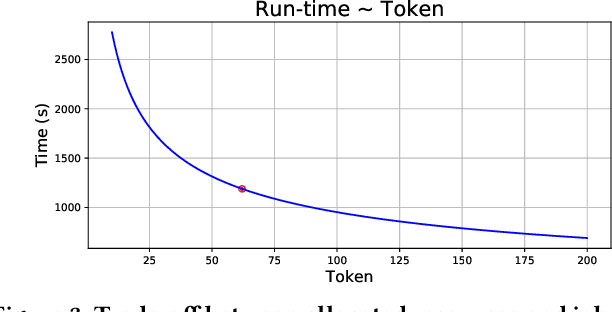
Optimizing resource allocation for analytical workloads is vital for reducing costs of cloud-data services. At the same time, it is incredibly hard for users to allocate resources per query in serverless processing systems, and they frequently misallocate by orders of magnitude. Unfortunately, prior work focused on predicting peak allocation while ignoring aggressive trade-offs between resource allocation and run-time. Additionally, these methods fail to predict allocation for queries that have not been observed in the past. In this paper, we tackle both these problems. We introduce a system for optimal resource allocation that can predict performance with aggressive trade-offs, for both new and past observed queries. We introduce the notion of a performance characteristic curve (PCC) as a parameterized representation that can compactly capture the relationship between resources and performance. To tackle training data sparsity, we introduce a novel data augmentation technique to efficiently synthesize the entire PCC using a single run of the query. Lastly, we demonstrate the advantages of a constrained loss function coupled with GNNs, over traditional ML methods, for capturing the domain specific behavior through an extensive experimental evaluation over SCOPE big data workloads at Microsoft.