 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Optimizing Interventions in Shared Autonomy
Jan 01, 2022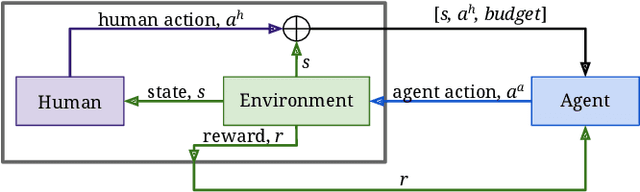
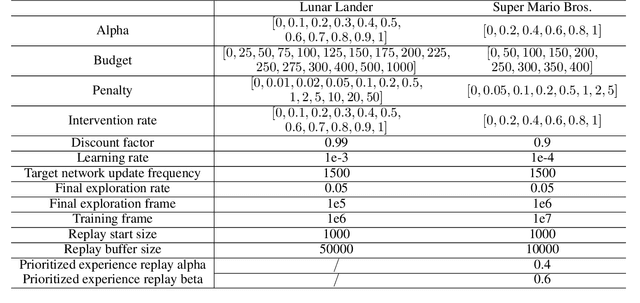

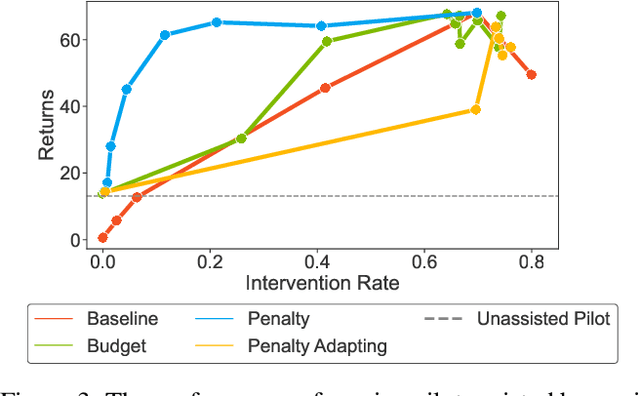
Shared autonomy refers to approaches for enabling an autonomous agent to collaborate with a human with the aim of improving human performance. However, besides improving performance, it may often also be beneficial that the agent concurrently accounts for preserving the user's experience or satisfaction of collaboration. In order to address this additional goal, we examine approaches for improving the user experience by constraining the number of interventions by the autonomous agent. We propose two model-free reinforcement learning methods that can account for both hard and soft constraints on the number of interventions. We show that not only does our method outperform the existing baseline, but also eliminates the need to manually tune a black-box hyperparameter for controlling the level of assistance. We also provide an in-depth analysis of intervention scenarios in order to further illuminate system understanding.
Semi-Supervised Few-Shot Intent Classification and Slot Filling
Sep 17, 2021
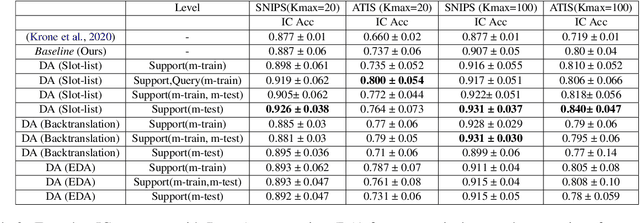
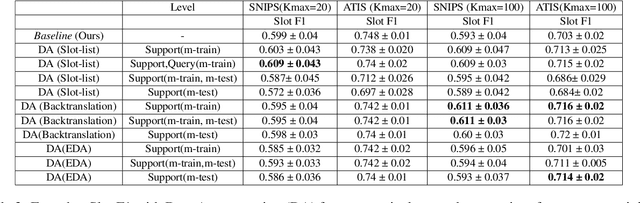

Intent classification (IC) and slot filling (SF) are two fundamental tasks in modern Natural Language Understanding (NLU) systems. Collecting and annotating large amounts of data to train deep learning models for such systems is not scalable. This problem can be addressed by learning from few examples using fast supervised meta-learning techniques such as prototypical networks. In this work, we systematically investigate how contrastive learning and unsupervised data augmentation methods can benefit these existing supervised meta-learning pipelines for jointly modelled IC/SF tasks. Through extensive experiments across standard IC/SF benchmarks (SNIPS and ATIS), we show that our proposed semi-supervised approaches outperform standard supervised meta-learning methods: contrastive losses in conjunction with prototypical networks consistently outperform the existing state-of-the-art for both IC and SF tasks, while data augmentation strategies primarily improve few-shot IC by a significant margin.
Optimal Resource Allocation for Serverless Queries
Jul 19, 2021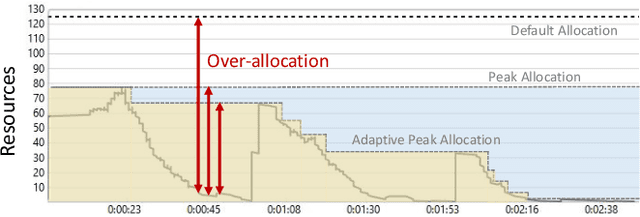
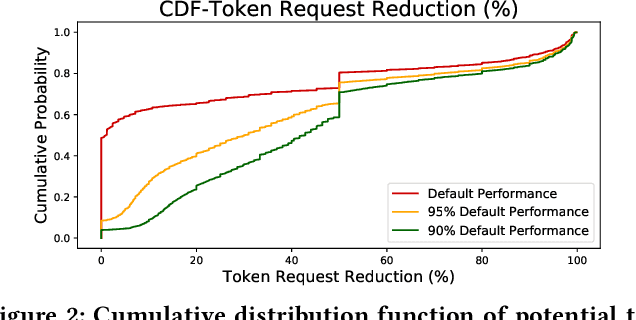

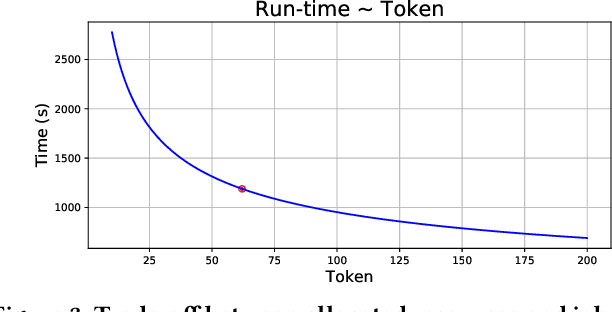
Optimizing resource allocation for analytical workloads is vital for reducing costs of cloud-data services. At the same time, it is incredibly hard for users to allocate resources per query in serverless processing systems, and they frequently misallocate by orders of magnitude. Unfortunately, prior work focused on predicting peak allocation while ignoring aggressive trade-offs between resource allocation and run-time. Additionally, these methods fail to predict allocation for queries that have not been observed in the past. In this paper, we tackle both these problems. We introduce a system for optimal resource allocation that can predict performance with aggressive trade-offs, for both new and past observed queries. We introduce the notion of a performance characteristic curve (PCC) as a parameterized representation that can compactly capture the relationship between resources and performance. To tackle training data sparsity, we introduce a novel data augmentation technique to efficiently synthesize the entire PCC using a single run of the query. Lastly, we demonstrate the advantages of a constrained loss function coupled with GNNs, over traditional ML methods, for capturing the domain specific behavior through an extensive experimental evaluation over SCOPE big data workloads at Microsoft.