 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisambiguate Entity Matching through Relation Discovery with Large Language Models
Mar 26, 2024Entity matching is a critical challenge in data integration and cleaning, central to tasks like fuzzy joins and deduplication. Traditional approaches have focused on overcoming fuzzy term representations through methods such as edit distance, Jaccard similarity, and more recently, embeddings and deep neural networks, including advancements from large language models (LLMs) like GPT. However, the core challenge in entity matching extends beyond term fuzziness to the ambiguity in defining what constitutes a "match," especially when integrating with external databases. This ambiguity arises due to varying levels of detail and granularity among entities, complicating exact matches. We propose a novel approach that shifts focus from purely identifying semantic similarities to understanding and defining the "relations" between entities as crucial for resolving ambiguities in matching. By predefining a set of relations relevant to the task at hand, our method allows analysts to navigate the spectrum of similarity more effectively, from exact matches to conceptually related entities.
JoinBoost: Grow Trees Over Normalized Data Using Only SQL
Jul 01, 2023
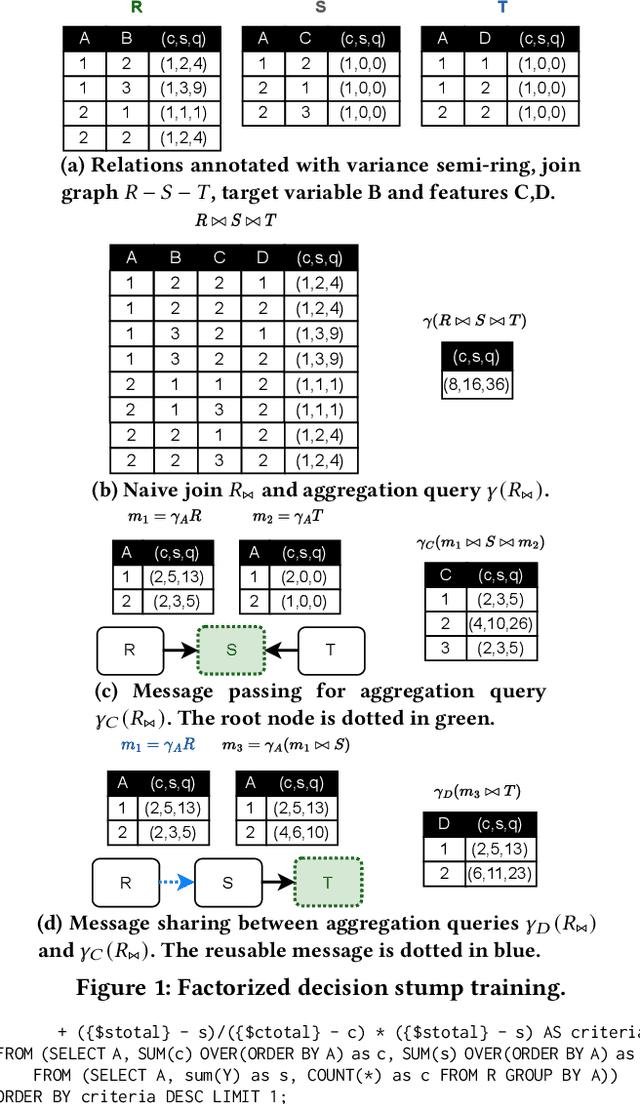
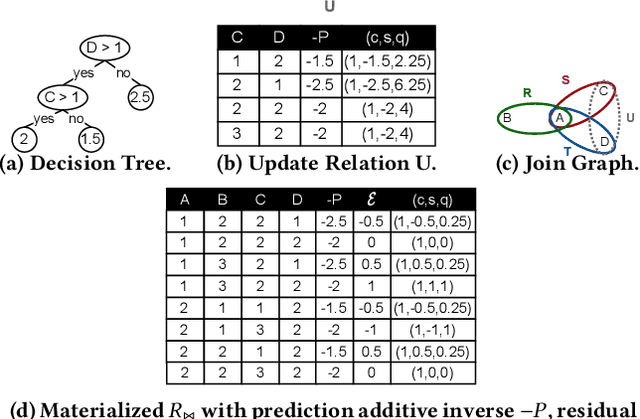

Although dominant for tabular data, ML libraries that train tree models over normalized databases (e.g., LightGBM, XGBoost) require the data to be denormalized as a single table, materialized, and exported. This process is not scalable, slow, and poses security risks. In-DB ML aims to train models within DBMSes to avoid data movement and provide data governance. Rather than modify a DBMS to support In-DB ML, is it possible to offer competitive tree training performance to specialized ML libraries...with only SQL? We present JoinBoost, a Python library that rewrites tree training algorithms over normalized databases into pure SQL. It is portable to any DBMS, offers performance competitive with specialized ML libraries, and scales with the underlying DBMS capabilities. JoinBoost extends prior work from both algorithmic and systems perspectives. Algorithmically, we support factorized gradient boosting, by updating the $Y$ variable to the residual in the non-materialized join result. Although this view update problem is generally ambiguous, we identify addition-to-multiplication preserving, the key property of variance semi-ring to support rmse, the most widely used criterion. System-wise, we identify residual updates as a performance bottleneck. Such overhead can be natively minimized on columnar DBMSes by creating a new column of residual values and adding it as a projection. We validate this with two implementations on DuckDB, with no or minimal modifications to its internals for portability. Our experiment shows that JoinBoost is 3x (1.1x) faster for random forests (gradient boosting) compared to LightGBM, and over an order magnitude faster than state-of-the-art In-DB ML systems. Further, JoinBoost scales well beyond LightGBM in terms of the # features, DB size (TPC-DS SF=1000), and join graph complexity (galaxy schemas).