 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQE-EBM: Using Quality Estimators as Energy Loss for Machine Translation
Oct 14, 2024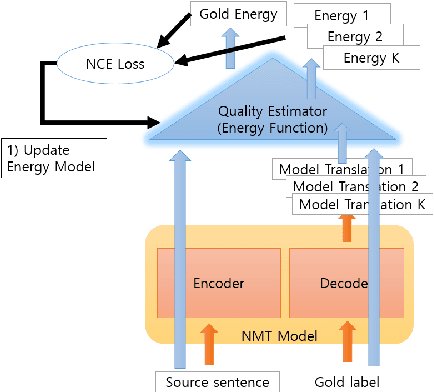



Reinforcement learning has shown great promise in aligning language models with human preferences in a variety of text generation tasks, including machine translation. For translation tasks, rewards can easily be obtained from quality estimation (QE) models which can generate rewards for unlabeled data. Despite its usefulness, reinforcement learning cannot exploit the gradients with respect to the QE score. We propose QE-EBM, a method of employing quality estimators as trainable loss networks that can directly backpropagate to the NMT model. We examine our method on several low and high resource target languages with English as the source language. QE-EBM outperforms strong baselines such as REINFORCE and proximal policy optimization (PPO) as well as supervised fine-tuning for all target languages, especially low-resource target languages. Most notably, for English-to-Mongolian translation, our method achieves improvements of 2.5 BLEU, 7.1 COMET-KIWI, 5.3 COMET, and 6.4 XCOMET relative to the supervised baseline.