 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information-theoretic Approach to Machine-oriented Music Summarization
Sep 21, 2018
Music summarization allows for higher efficiency in processing, storage, and sharing of datasets. Machine-oriented approaches, being agnostic to human consumption, optimize these aspects even further. Such summaries have already been successfully validated in some MIR tasks. We now generalize previous conclusions by evaluating the impact of generic summarization of music from a probabilistic perspective. We estimate Gaussian distributions for original and summarized songs and compute their relative entropy, in order to measure information loss incurred by summarization. Our results suggest that relative entropy is a good predictor of summarization performance in the context of tasks relying on a bag-of-features model. Based on this observation, we further propose a straightforward yet expressive summarizer, which minimizes relative entropy with respect to the original song, that objectively outperforms previous methods and is better suited to avoid potential copyright issues.
Towards Deep Modeling of Music Semantics using EEG Regularizers
Dec 15, 2017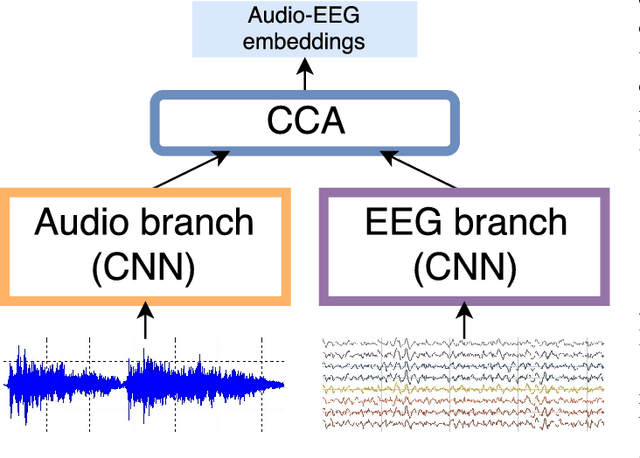
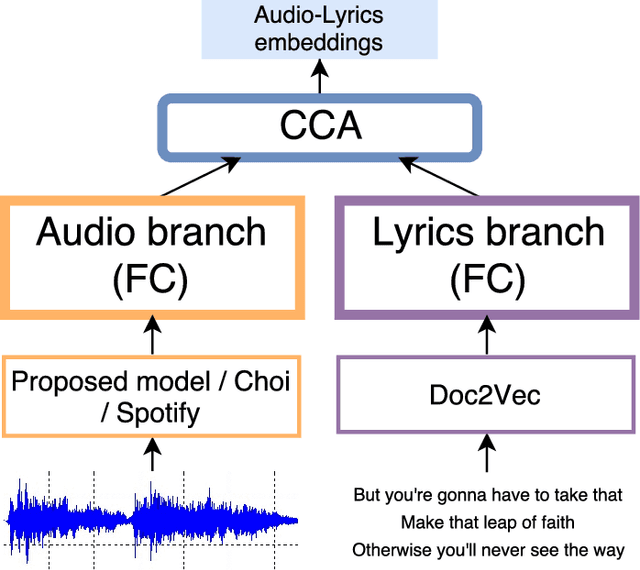
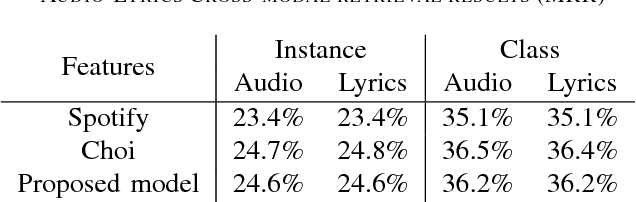
Modeling of music audio semantics has been previously tackled through learning of mappings from audio data to high-level tags or latent unsupervised spaces. The resulting semantic spaces are theoretically limited, either because the chosen high-level tags do not cover all of music semantics or because audio data itself is not enough to determine music semantics. In this paper, we propose a generic framework for semantics modeling that focuses on the perception of the listener, through EEG data, in addition to audio data. We implement this framework using a novel end-to-end 2-view Neural Network (NN) architecture and a Deep Canonical Correlation Analysis (DCCA) loss function that forces the semantic embedding spaces of both views to be maximally correlated. We also detail how the EEG dataset was collected and use it to train our proposed model. We evaluate the learned semantic space in a transfer learning context, by using it as an audio feature extractor in an independent dataset and proxy task: music audio-lyrics cross-modal retrieval. We show that our embedding model outperforms Spotify features and performs comparably to a state-of-the-art embedding model that was trained on 700 times more data. We further discuss improvements to the model that are likely to improve its performance.
Summarization of Films and Documentaries Based on Subtitles and Scripts
Mar 09, 2016
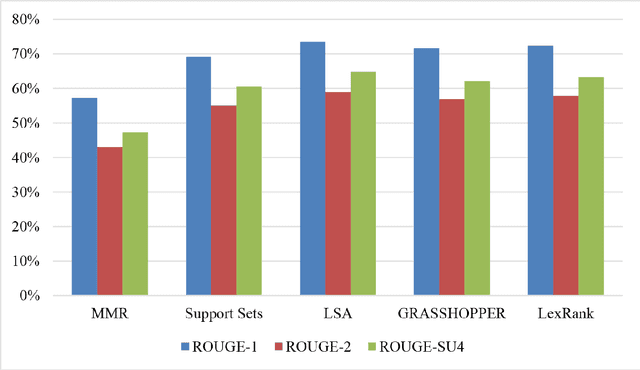
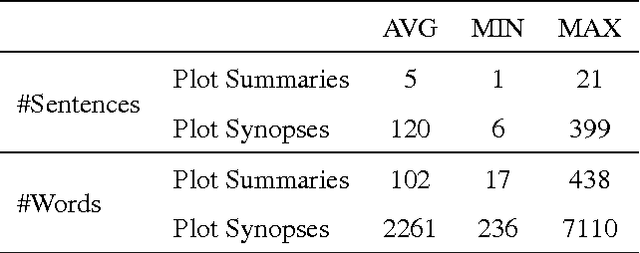
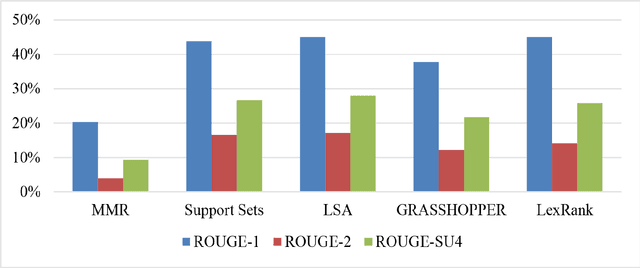
We assess the performance of generic text summarization algorithms applied to films and documentaries, using the well-known behavior of summarization of news articles as reference. We use three datasets: (i) news articles, (ii) film scripts and subtitles, and (iii) documentary subtitles. Standard ROUGE metrics are used for comparing generated summaries against news abstracts, plot summaries, and synopses. We show that the best performing algorithms are LSA, for news articles and documentaries, and LexRank and Support Sets, for films. Despite the different nature of films and documentaries, their relative behavior is in accordance with that obtained for news articles.
* 7 pages, 9 tables, 4 figures, submitted to Pattern Recognition Letters (Elsevier)
Using Generic Summarization to Improve Music Information Retrieval Tasks
Mar 09, 2016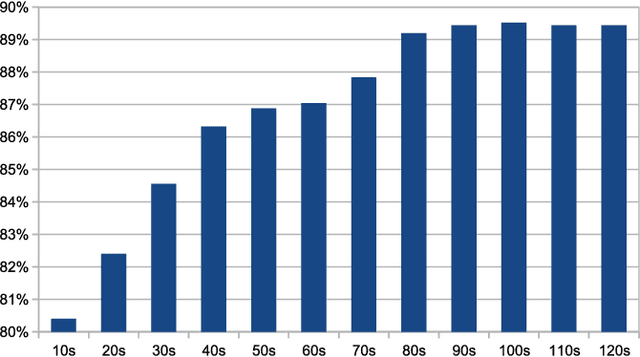
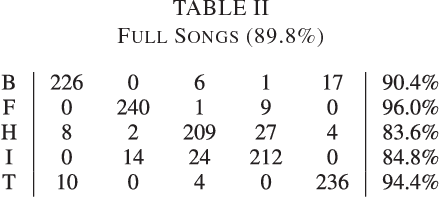
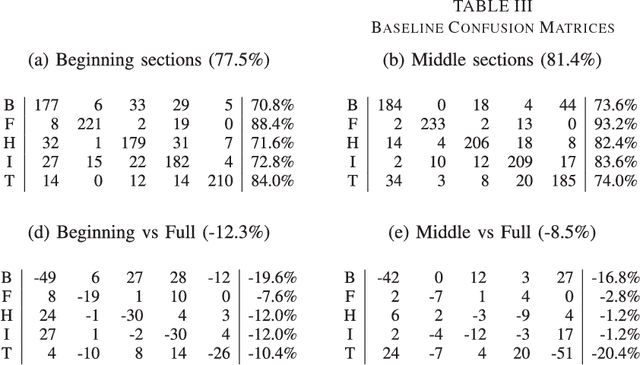
In order to satisfy processing time constraints, many MIR tasks process only a segment of the whole music signal. This practice may lead to decreasing performance, since the most important information for the tasks may not be in those processed segments. In this paper, we leverage generic summarization algorithms, previously applied to text and speech summarization, to summarize items in music datasets. These algorithms build summaries, that are both concise and diverse, by selecting appropriate segments from the input signal which makes them good candidates to summarize music as well. We evaluate the summarization process on binary and multiclass music genre classification tasks, by comparing the performance obtained using summarized datasets against the performances obtained using continuous segments (which is the traditional method used for addressing the previously mentioned time constraints) and full songs of the same original dataset. We show that GRASSHOPPER, LexRank, LSA, MMR, and a Support Sets-based Centrality model improve classification performance when compared to selected 30-second baselines. We also show that summarized datasets lead to a classification performance whose difference is not statistically significant from using full songs. Furthermore, we make an argument stating the advantages of sharing summarized datasets for future MIR research.
* 24 pages, 10 tables; Submitted to IEEE/ACM Transactions on Audio, Speech and Language Processing
On the Application of Generic Summarization Algorithms to Music
Jun 18, 2014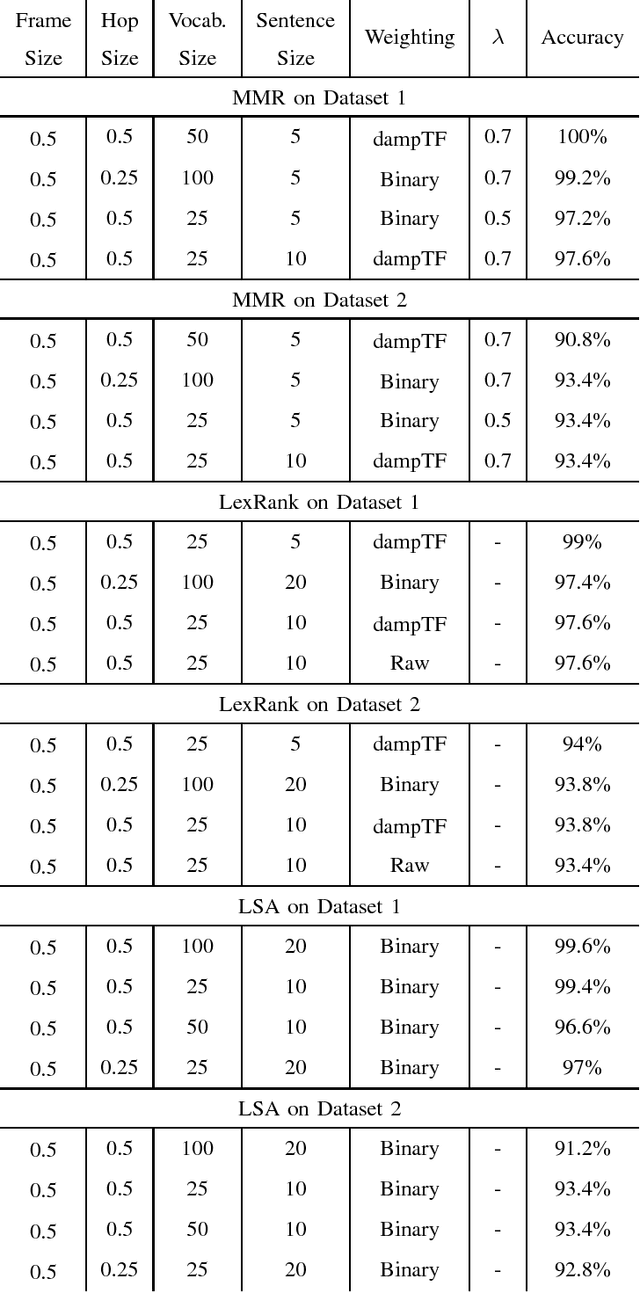
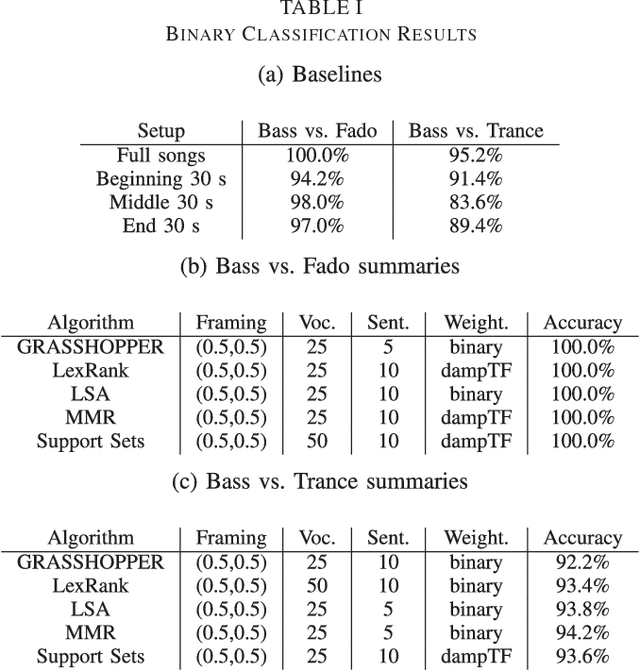
Several generic summarization algorithms were developed in the past and successfully applied in fields such as text and speech summarization. In this paper, we review and apply these algorithms to music. To evaluate this summarization's performance, we adopt an extrinsic approach: we compare a Fado Genre Classifier's performance using truncated contiguous clips against the summaries extracted with those algorithms on 2 different datasets. We show that Maximal Marginal Relevance (MMR), LexRank and Latent Semantic Analysis (LSA) all improve classification performance in both datasets used for testing.
* 12 pages, 1 table; Submitted to IEEE Signal Processing Letters