 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Generic Summarization to Improve Music Information Retrieval Tasks
Paper and Code
Mar 09, 2016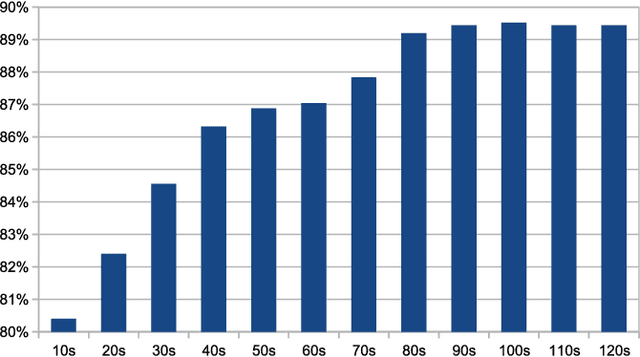
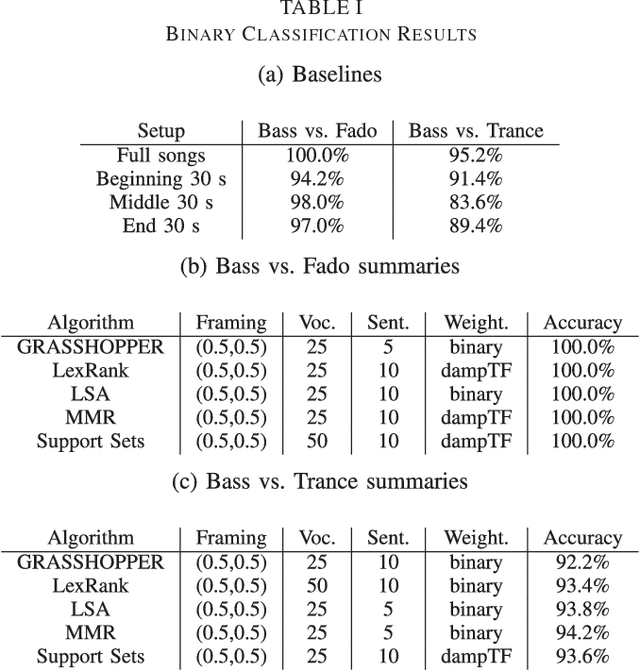
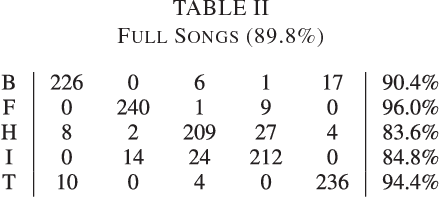
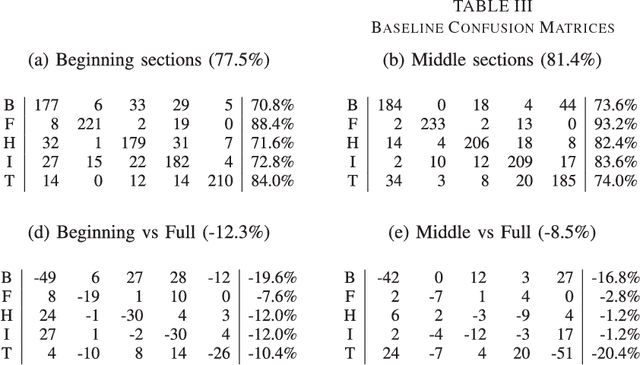
In order to satisfy processing time constraints, many MIR tasks process only a segment of the whole music signal. This practice may lead to decreasing performance, since the most important information for the tasks may not be in those processed segments. In this paper, we leverage generic summarization algorithms, previously applied to text and speech summarization, to summarize items in music datasets. These algorithms build summaries, that are both concise and diverse, by selecting appropriate segments from the input signal which makes them good candidates to summarize music as well. We evaluate the summarization process on binary and multiclass music genre classification tasks, by comparing the performance obtained using summarized datasets against the performances obtained using continuous segments (which is the traditional method used for addressing the previously mentioned time constraints) and full songs of the same original dataset. We show that GRASSHOPPER, LexRank, LSA, MMR, and a Support Sets-based Centrality model improve classification performance when compared to selected 30-second baselines. We also show that summarized datasets lead to a classification performance whose difference is not statistically significant from using full songs. Furthermore, we make an argument stating the advantages of sharing summarized datasets for future MIR research.