 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Tabular Foundation Models via In-Context Kernel Regression
Feb 02, 2026Tabular foundation models like TabPFN and TabICL achieve state-of-the-art performance through in-context learning, yet their architectures remain fundamentally opaque. We introduce KernelICL, a framework to enhance tabular foundation models with quantifiable sample-based interpretability. Building on the insight that in-context learning is akin to kernel regression, we make this mechanism explicit by replacing the final prediction layer with kernel functions (Gaussian, dot-product, kNN) so that every prediction is a transparent weighted average of training labels. We introduce a two-dimensional taxonomy that formally unifies standard kernel methods, modern neighbor-based approaches, and attention mechanisms under a single framework, and quantify inspectability via the perplexity of the weight distribution over training samples. On 55 TALENT benchmark datasets, KernelICL achieves performance on par with existing tabular foundation models, demonstrating that explicit kernel constraints on the final layer enable inspectable predictions without sacrificing performance.
MEMERAG: A Multilingual End-to-End Meta-Evaluation Benchmark for Retrieval Augmented Generation
Feb 25, 2025Automatic evaluation of retrieval augmented generation (RAG) systems relies on fine-grained dimensions like faithfulness and relevance, as judged by expert human annotators. Meta-evaluation benchmarks support the development of automatic evaluators that correlate well with human judgement. However, existing benchmarks predominantly focus on English or use translated data, which fails to capture cultural nuances. A native approach provides a better representation of the end user experience. In this work, we develop a Multilingual End-to-end Meta-Evaluation RAG benchmark (MEMERAG). Our benchmark builds on the popular MIRACL dataset, using native-language questions and generating responses with diverse large language models (LLMs), which are then assessed by expert annotators for faithfulness and relevance. We describe our annotation process and show that it achieves high inter-annotator agreement. We then analyse the performance of the answer-generating LLMs across languages as per the human evaluators. Finally we apply the dataset to our main use-case which is to benchmark multilingual automatic evaluators (LLM-as-a-judge). We show that our benchmark can reliably identify improvements offered by advanced prompting techniques and LLMs. We will release our benchmark to support the community developing accurate evaluation methods for multilingual RAG systems.
Large-scale Recommendation for Portfolio Optimization
Mar 13, 2021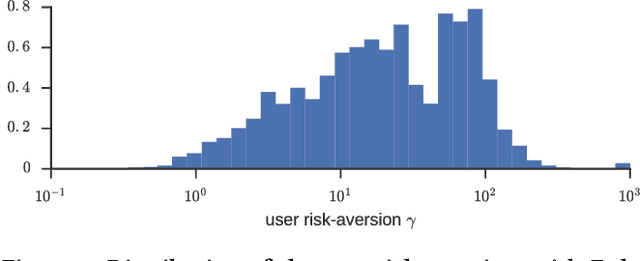

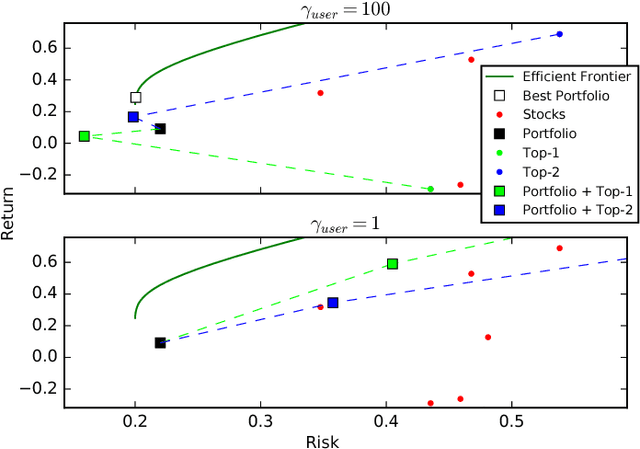
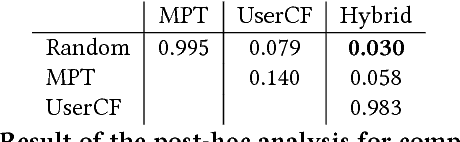
Individual investors are now massively using online brokers to trade stocks with convenient interfaces and low fees, albeit losing the advice and personalization traditionally provided by full-service brokers. We frame the problem faced by online brokers of replicating this level of service in a low-cost and automated manner for a very large number of users. Because of the care required in recommending financial products, we focus on a risk-management approach tailored to each user's portfolio and risk profile. We show that our hybrid approach, based on Modern Portfolio Theory and Collaborative Filtering, provides a sound and effective solution. The method is applicable to stocks as well as other financial assets, and can be easily combined with various financial forecasting models. We validate our proposal by comparing it with several baselines in a domain expert-based study.
PiRank: Learning To Rank via Differentiable Sorting
Dec 12, 2020

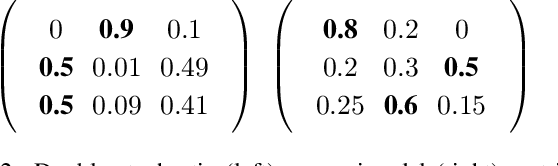
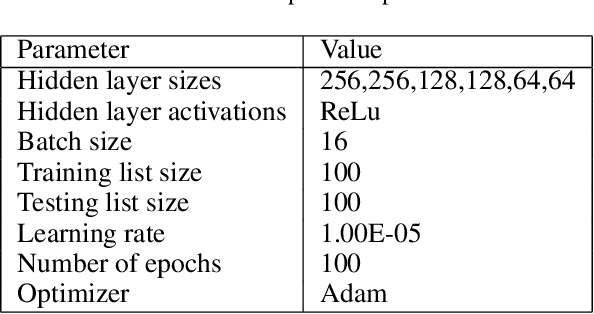
A key challenge with machine learning approaches for ranking is the gap between the performance metrics of interest and the surrogate loss functions that can be optimized with gradient-based methods. This gap arises because ranking metrics typically involve a sorting operation which is not differentiable w.r.t. the model parameters. Prior works have proposed surrogates that are loosely related to ranking metrics or simple smoothed versions thereof. We propose PiRank, a new class of differentiable surrogates for ranking, which employ a continuous, temperature-controlled relaxation to the sorting operator. We show that PiRank exactly recovers the desired metrics in the limit of zero temperature and scales favorably with the problem size, both in theory and practice. Empirically, we demonstrate that PiRank significantly improves over existing approaches on publicly available internet-scale learning-to-rank benchmarks.