 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Discovery of Recurring Speech Patterns Using Probabilistic Adaptive Metrics
Paper and Code
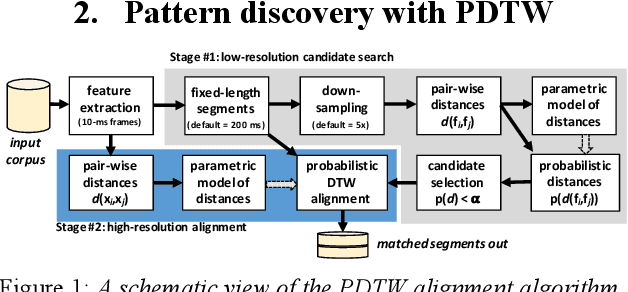
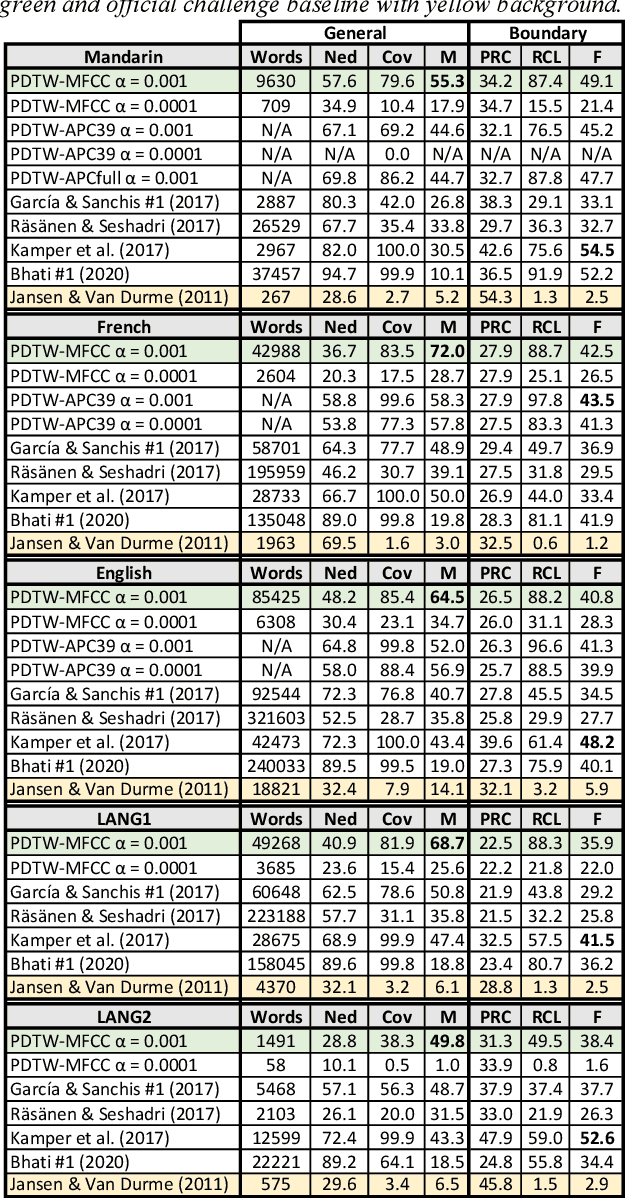
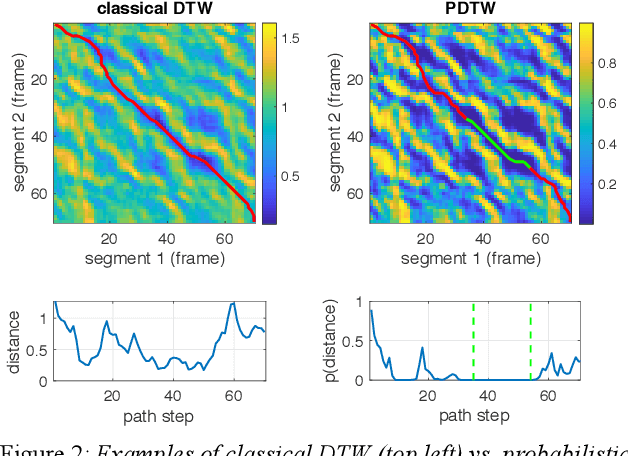
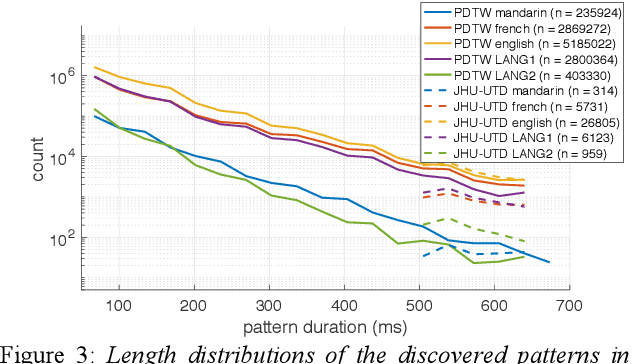
Unsupervised spoken term discovery (UTD) aims at finding recurring segments of speech from a corpus of acoustic speech data. One potential approach to this problem is to use dynamic time warping (DTW) to find well-aligning patterns from the speech data. However, automatic selection of initial candidate segments for the DTW-alignment and detection of "sufficiently good" alignments among those require some type of pre-defined criteria, often operationalized as threshold parameters for pair-wise distance metrics between signal representations. In the existing UTD systems, the optimal hyperparameters may differ across datasets, limiting their applicability to new corpora and truly low-resource scenarios. In this paper, we propose a novel probabilistic approach to DTW-based UTD named as PDTW. In PDTW, distributional characteristics of the processed corpus are utilized for adaptive evaluation of alignment quality, thereby enabling systematic discovery of pattern pairs that have similarity what would be expected by coincidence. We test PDTW on Zero Resource Speech Challenge 2017 datasets as a part of 2020 implementation of the challenge. The results show that the system performs consistently on all five tested languages using fixed hyperparameters, clearly outperforming the earlier DTW-based system in terms of coverage of the detected patterns.