 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-based Audio Retrieval Task in DCASE 2022 Challenge
Oct 04, 2022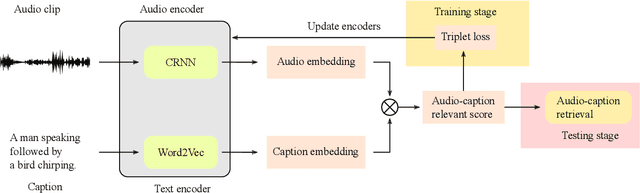
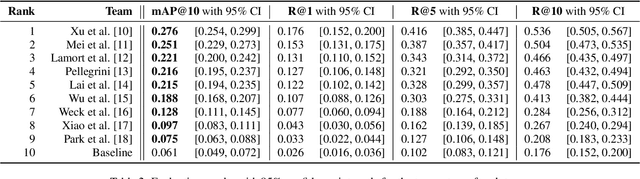
Language-based audio retrieval is a task, where natural language textual captions are used as queries to retrieve audio signals from a dataset. It has been first introduced into DCASE 2022 Challenge as Subtask 6B of task 6, which aims at developing computational systems to model relationships between audio signals and free-form textual descriptions. Compared with audio captioning (Subtask 6A), which is about generating audio captions for audio signals, language-based audio retrieval (Subtask 6B) focuses on ranking audio signals according to their relevance to natural language textual captions. In DCASE 2022 Challenge, the provided baseline system for Subtask 6B was significantly outperformed, with top performance being 0.276 in mAP@10. This paper presents the outcome of Subtask 6B in terms of submitted systems' performance and analysis.
DCASE 2022 Challenge Task 6B: Language-Based Audio Retrieval
Jun 15, 2022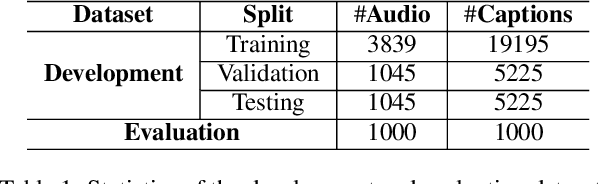
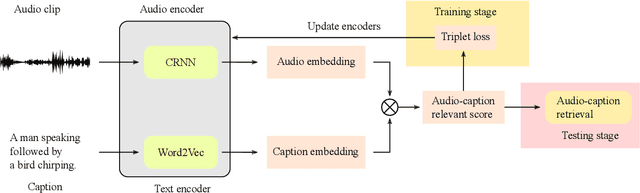

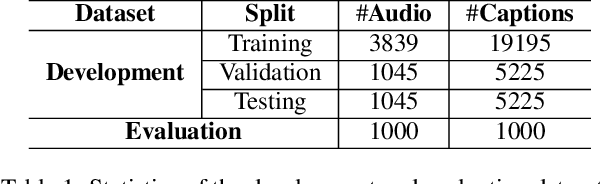
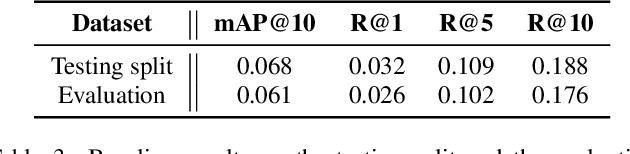
In this report, we introduce the task setup and the baseline system for the sub-task B of the DCASE 2022 Challenge Task 6: language-based audio retrieval subtask. For this subtask, the Clotho v2 dataset is utilized as the development dataset, and an additional dataset consisting of 1,000 audio-caption pairs as the evaluation dataset. We train the baseline system with the development dataset, and evaluate it on the evaluation dataset to provide some initial results for this subtask.
Clotho-AQA: A Crowdsourced Dataset for Audio Question Answering
Apr 20, 2022
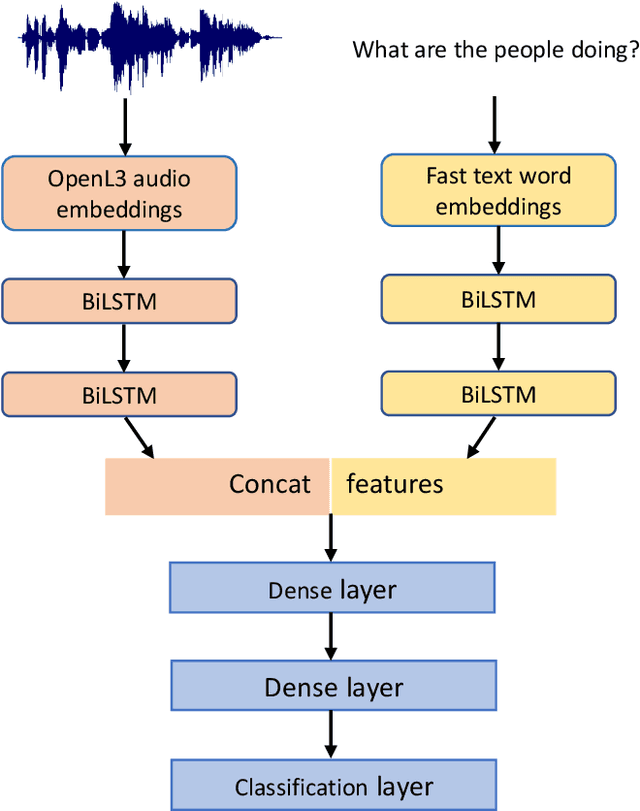
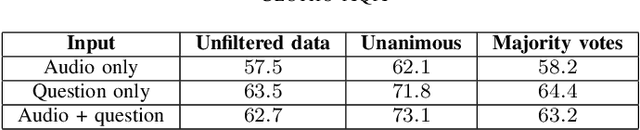

Audio question answering (AQA) is a multimodal translation task where a system analyzes an audio signal and a natural language question, to generate a desirable natural language answer. In this paper, we introduce Clotho-AQA, a dataset for Audio question answering consisting of 1991 audio files each between 15 to 30 seconds in duration selected from the Clotho dataset [1]. For each audio file, we collect six different questions and corresponding answers by crowdsourcing using Amazon Mechanical Turk. The questions and answers are produced by different annotators. Out of the six questions for each audio, two questions each are designed to have 'yes' and 'no' as answers, while the remaining two questions have other single-word answers. For each question, we collect answers from three different annotators. We also present two baseline experiments to describe the usage of our dataset for the AQA task - an LSTM-based multimodal binary classifier for 'yes' or 'no' type answers and an LSTM-based multimodal multi-class classifier for 828 single-word answers. The binary classifier achieved an accuracy of 62.7% and the multi-class classifier achieved a top-1 accuracy of 54.2% and a top-5 accuracy of 93.7%. Clotho-AQA dataset is freely available online at https://zenodo.org/record/6473207.
Clotho: An Audio Captioning Dataset
Oct 21, 2019
Audio captioning is the novel task of general audio content description using free text. It is an intermodal translation task (not speech-to-text), where a system accepts as an input an audio signal and outputs the textual description (i.e. the caption) of that signal. In this paper we present Clotho, a dataset for audio captioning consisting of 4981 audio samples of 15 to 30 seconds duration and 24 905 captions of eight to 20 words length, and a baseline method to provide initial results. Clotho is built with focus on audio content and caption diversity, and the splits of the data are not hampering the training or evaluation of methods. All sounds are from the Freesound platform, and captions are crowdsourced using Amazon Mechanical Turk and annotators from English speaking countries. Unique words, named entities, and speech transcription are removed with post-processing. Clotho is freely available online (https://zenodo.org/record/3490684).