Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCASE 2022 Challenge Task 6B: Language-Based Audio Retrieval
Paper and Code
Jun 15, 2022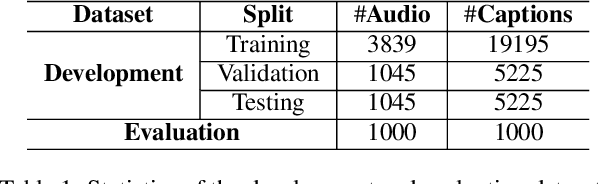
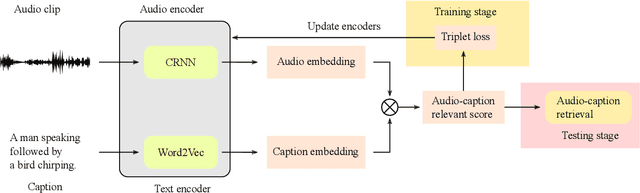

In this report, we introduce the task setup and the baseline system for the sub-task B of the DCASE 2022 Challenge Task 6: language-based audio retrieval subtask. For this subtask, the Clotho v2 dataset is utilized as the development dataset, and an additional dataset consisting of 1,000 audio-caption pairs as the evaluation dataset. We train the baseline system with the development dataset, and evaluate it on the evaluation dataset to provide some initial results for this subtask.
View paper on