 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label Zero-Shot Audio Classification with Temporal Attention
Aug 31, 2024Zero-shot learning models are capable of classifying new classes by transferring knowledge from the seen classes using auxiliary information. While most of the existing zero-shot learning methods focused on single-label classification tasks, the present study introduces a method to perform multi-label zero-shot audio classification. To address the challenge of classifying multi-label sounds while generalizing to unseen classes, we adapt temporal attention. The temporal attention mechanism assigns importance weights to different audio segments based on their acoustic and semantic compatibility, thus enabling the model to capture the varying dominance of different sound classes within an audio sample by focusing on the segments most relevant for each class. This leads to more accurate multi-label zero-shot classification than methods employing temporally aggregated acoustic features without weighting, which treat all audio segments equally. We evaluate our approach on a subset of AudioSet against a zero-shot model using uniformly aggregated acoustic features, a zero-rule baseline, and the proposed method in the supervised scenario. Our results show that temporal attention enhances the zero-shot audio classification performance in multi-label scenario.
Zero-Shot Audio Classification using Image Embeddings
Jun 10, 2022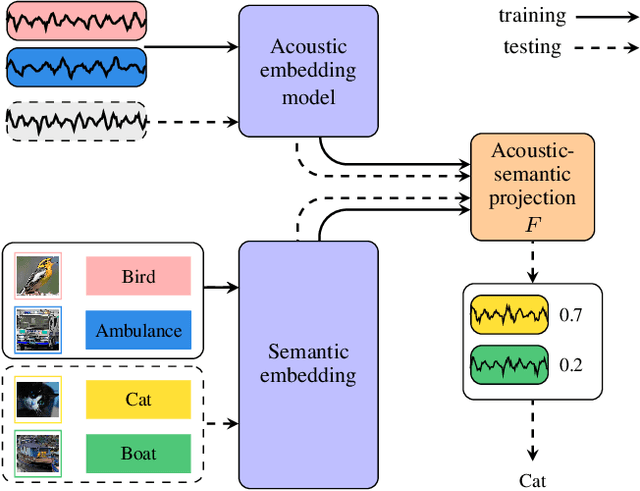
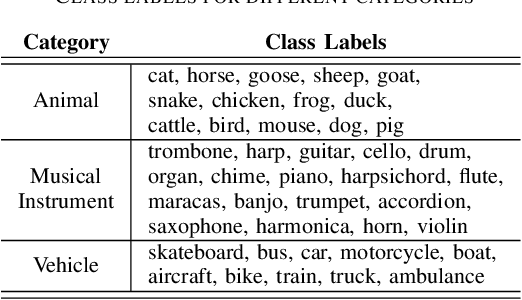
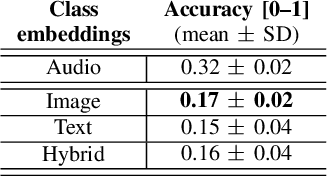
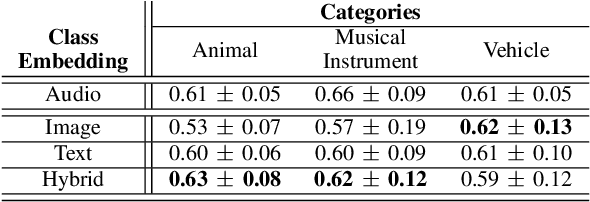
Supervised learning methods can solve the given problem in the presence of a large set of labeled data. However, the acquisition of a dataset covering all the target classes typically requires manual labeling which is expensive and time-consuming. Zero-shot learning models are capable of classifying the unseen concepts by utilizing their semantic information. The present study introduces image embeddings as side information on zero-shot audio classification by using a nonlinear acoustic-semantic projection. We extract the semantic image representations from the Open Images dataset and evaluate the performance of the models on an audio subset of AudioSet using semantic information in different domains; image, audio, and textual. We demonstrate that the image embeddings can be used as semantic information to perform zero-shot audio classification. The experimental results show that the image and textual embeddings display similar performance both individually and together. We additionally calculate the semantic acoustic embeddings from the test samples to provide an upper limit to the performance. The results show that the classification performance is highly sensitive to the semantic relation between test and training classes and textual and image embeddings can reach up to the semantic acoustic embeddings when the seen and unseen classes are semantically similar.