 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Interactive 2D Visualization as a Sample Selection Strategy for Biomedical Time-Series Data Annotation
Mar 27, 2026Reliable machine-learning models in biomedical settings depend on accurate labels, yet annotating biomedical time-series data remains challenging. Algorithmic sample selection may support annotation, but evidence from studies involving real human annotators is scarce. Consequently, we compare three sample selection methods for annotation: random sampling (RND), farthest-first traversal (FAFT), and a graphical user interface-based method enabling exploration of complementary 2D visualizations (2DVs) of high-dimensional data. We evaluated the methods across four classification tasks in infant motility assessment (IMA) and speech emotion recognition (SER). Twelve annotators, categorized as experts or non-experts, performed data annotation under a limited annotation budget, and post-annotation experiments were conducted to evaluate the sampling methods. Across all classification tasks, 2DV performed best when aggregating labels across annotators. In IMA, 2DV most effectively captured rare classes, but also exhibited greater annotator-to-annotator label distribution variability resulting from the limited annotation budget, decreasing classification performance when models were trained on individual annotators' labels; in these cases, FAFT excelled. For SER, 2DV outperformed the other methods among expert annotators and matched their performance for non-experts in the individual-annotator setting. A failure risk analysis revealed that RND was the safest choice when annotator count or annotator expertise was uncertain, whereas 2DV had the highest risk due to its greater label distribution variability. Furthermore, post-experiment interviews indicated that 2DV made the annotation task more interesting and enjoyable. Overall, 2DV-based sampling appears promising for biomedical time-series data annotation, particularly when the annotation budget is not highly constrained.
PFML: Self-Supervised Learning of Time-Series Data Without Representation Collapse
Nov 15, 2024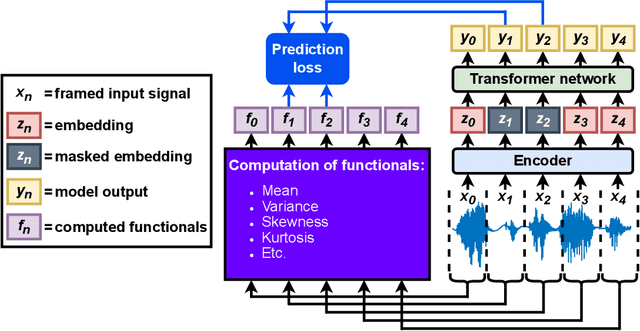
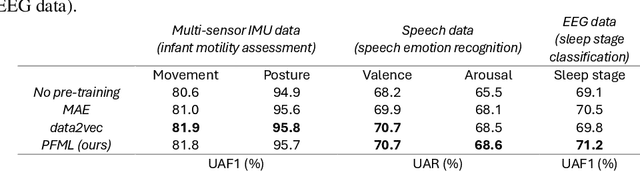
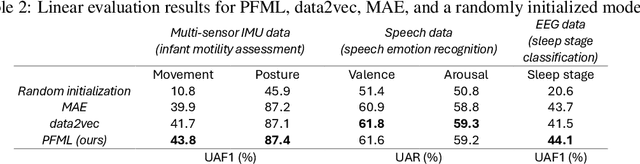
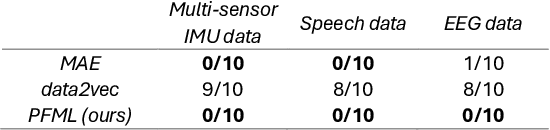
Self-supervised learning (SSL) is a data-driven learning approach that utilizes the innate structure of the data to guide the learning process. In contrast to supervised learning, which depends on external labels, SSL utilizes the inherent characteristics of the data to produce its own supervisory signal. However, one frequent issue with SSL methods is representation collapse, where the model outputs a constant input-invariant feature representation. This issue hinders the potential application of SSL methods to new data modalities, as trying to avoid representation collapse wastes researchers' time and effort. This paper introduces a novel SSL algorithm for time-series data called Prediction of Functionals from Masked Latents (PFML). Instead of predicting masked input signals or their latent representations directly, PFML operates by predicting statistical functionals of the input signal corresponding to masked embeddings, given a sequence of unmasked embeddings. The algorithm is designed to avoid representation collapse, rendering it straightforwardly applicable to different time-series data domains, such as novel sensor modalities in clinical data. We demonstrate the effectiveness of PFML through complex, real-life classification tasks across three different data modalities: infant posture and movement classification from multi-sensor inertial measurement unit data, emotion recognition from speech data, and sleep stage classification from EEG data. The results show that PFML is superior to a conceptually similar pre-existing SSL method and competitive against the current state-of-the-art SSL method, while also being conceptually simpler and without suffering from representation collapse.
Modeling 3D Infant Kinetics Using Adaptive Graph Convolutional Networks
Feb 22, 2024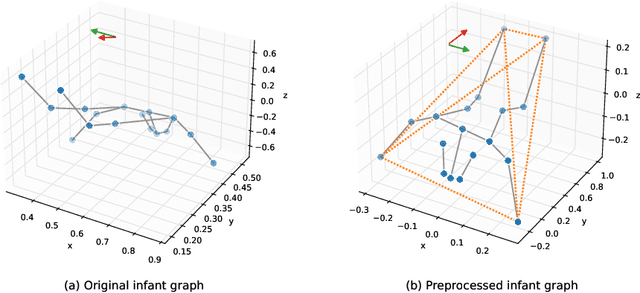


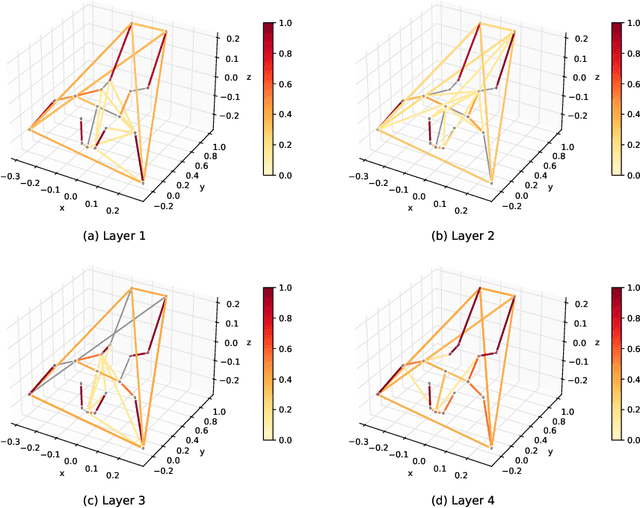
Reliable methods for the neurodevelopmental assessment of infants are essential for early detection of medical issues that may need prompt interventions. Spontaneous motor activity, or `kinetics', is shown to provide a powerful surrogate measure of upcoming neurodevelopment. However, its assessment is by and large qualitative and subjective, focusing on visually identified, age-specific gestures. Here, we follow an alternative approach, predicting infants' neurodevelopmental maturation based on data-driven evaluation of individual motor patterns. We utilize 3D video recordings of infants processed with pose-estimation to extract spatio-temporal series of anatomical landmarks, and apply adaptive graph convolutional networks to predict the actual age. We show that our data-driven approach achieves improvement over traditional machine learning baselines based on manually engineered features.
Evaluation of self-supervised pre-training for automatic infant movement classification using wearable movement sensors
May 16, 2023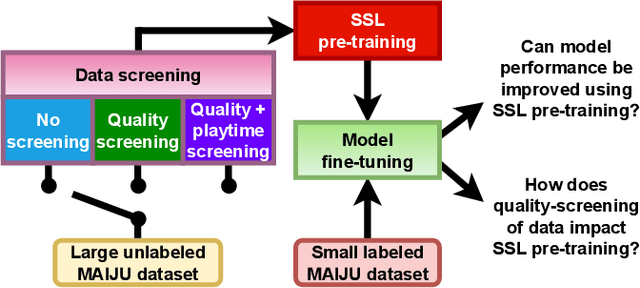
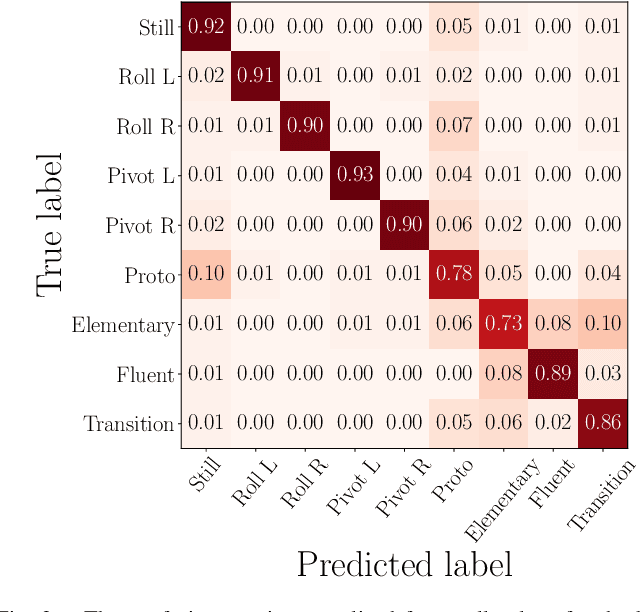
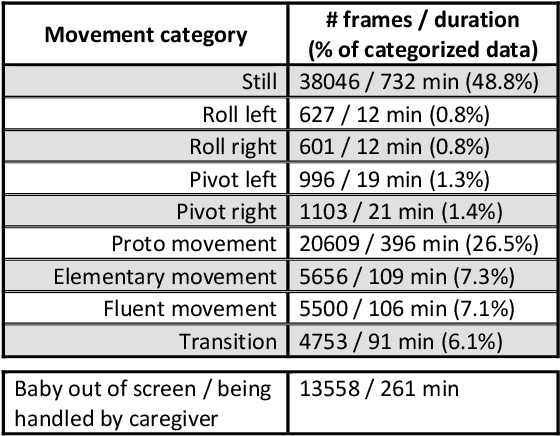
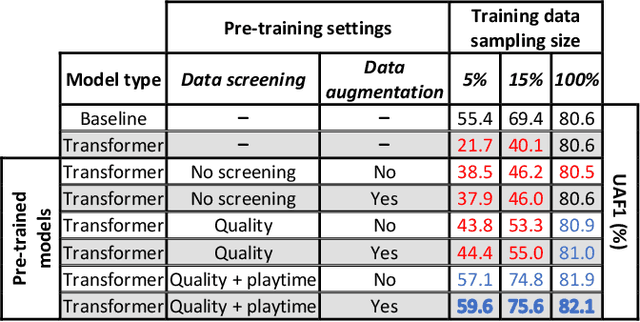
The recently-developed infant wearable MAIJU provides a means to automatically evaluate infants' motor performance in an objective and scalable manner in out-of-hospital settings. This information could be used for developmental research and to support clinical decision-making, such as detection of developmental problems and guiding of their therapeutic interventions. MAIJU-based analyses rely fully on the classification of infant's posture and movement; it is hence essential to study ways to increase the accuracy of such classifications, aiming to increase the reliability and robustness of the automated analysis. Here, we investigated how self-supervised pre-training improves performance of the classifiers used for analyzing MAIJU recordings, and we studied whether performance of the classifier models is affected by context-selective quality-screening of pre-training data to exclude periods of little infant movement or with missing sensors. Our experiments show that i) pre-training the classifier with unlabeled data leads to a robust accuracy increase of subsequent classification models, and ii) selecting context-relevant pre-training data leads to substantial further improvements in the classifier performance.
Analysis of Self-Supervised Learning and Dimensionality Reduction Methods in Clustering-Based Active Learning for Speech Emotion Recognition
Jun 21, 2022

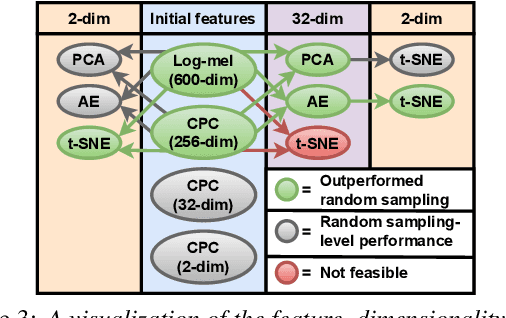
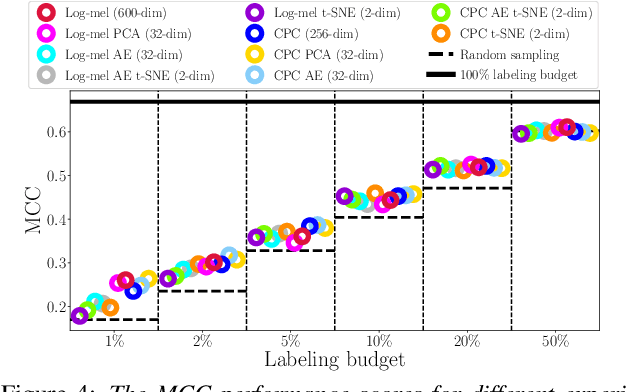
When domain experts are needed to perform data annotation for complex machine-learning tasks, reducing annotation effort is crucial in order to cut down time and expenses. For cases when there are no annotations available, one approach is to utilize the structure of the feature space for clustering-based active learning (AL) methods. However, these methods are heavily dependent on how the samples are organized in the feature space and what distance metric is used. Unsupervised methods such as contrastive predictive coding (CPC) can potentially be used to learn organized feature spaces, but these methods typically create high-dimensional features which might be challenging for estimating data density. In this paper, we combine CPC and multiple dimensionality reduction methods in search of functioning practices for clustering-based AL. Our experiments for simulating speech emotion recognition system deployment show that both the local and global topology of the feature space can be successfully used for AL, and that CPC can be used to improve clustering-based AL performance over traditional signal features. Additionally, we observe that compressing data dimensionality does not harm AL performance substantially, and that 2-D feature representations achieved similar AL performance as higher-dimensional representations when the number of annotations is not very low.
Comparison of end-to-end neural network architectures and data augmentation methods for automatic infant motility assessment using wearable sensors
Jul 02, 2021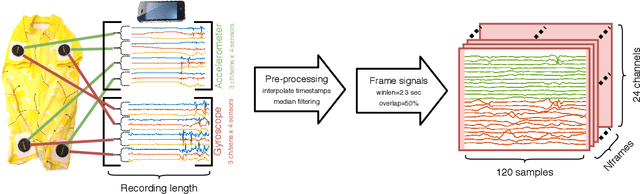

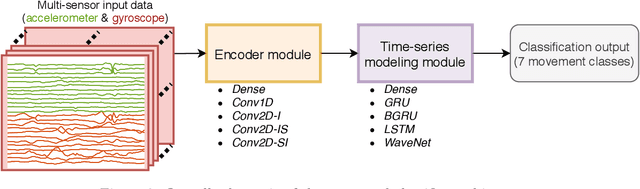
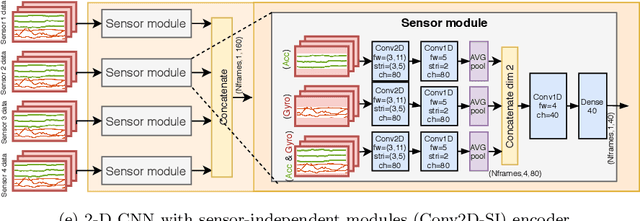
Infant motility assessment using intelligent wearables is a promising new approach for assessment of infant neurophysiological development, and where efficient signal analysis plays a central role. This study investigates the use of different end-to-end neural network architectures for processing infant motility data from wearable sensors. We focus on the performance and computational burden of alternative sensor encoder and time-series modelling modules and their combinations. In addition, we explore the benefits of data augmentation methods in ideal and non-ideal recording conditions. The experiments are conducted using a data-set of multi-sensor movement recordings from 7-month-old infants, as captured by a recently proposed smart jumpsuit for infant motility assessment. Our results indicate that the choice of the encoder module has a major impact on classifier performance. For sensor encoders, the best performance was obtained with parallel 2-dimensional convolutions for intra-sensor channel fusion with shared weights for all sensors. The results also indicate that a relatively compact feature representation is obtainable for within-sensor feature extraction without a drastic loss to classifier performance. Comparison of time-series models revealed that feed-forward dilated convolutions with residual and skip connections outperformed all RNN-based models in performance, training time, and training stability. The experiments also indicate that data augmentation improves model robustness in simulated packet loss or sensor dropout scenarios. In particular, signal- and sensor-dropout-based augmentation strategies provided considerable boosts to performance without negatively affecting the baseline performance. Overall the results provide tangible suggestions on how to optimize end-to-end neural network training for multi-channel movement sensor data.
Automatic Posture and Movement Tracking of Infants with Wearable Movement Sensors
Sep 21, 2019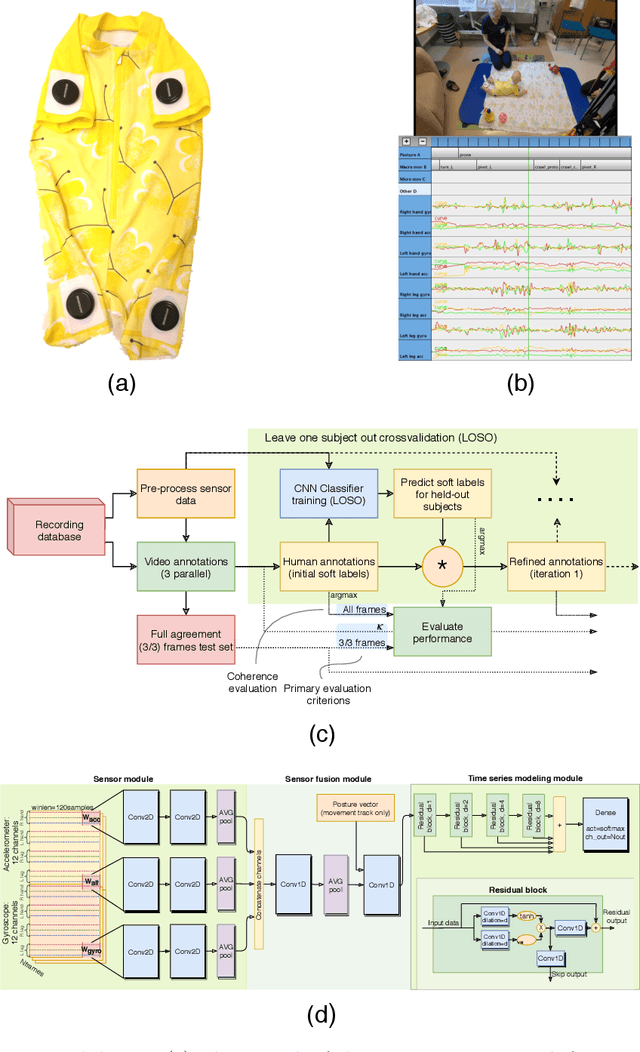
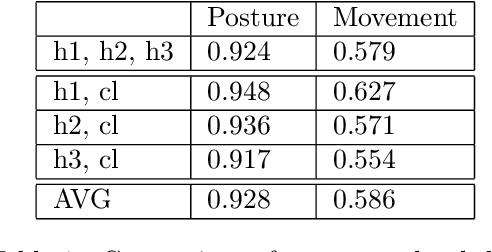
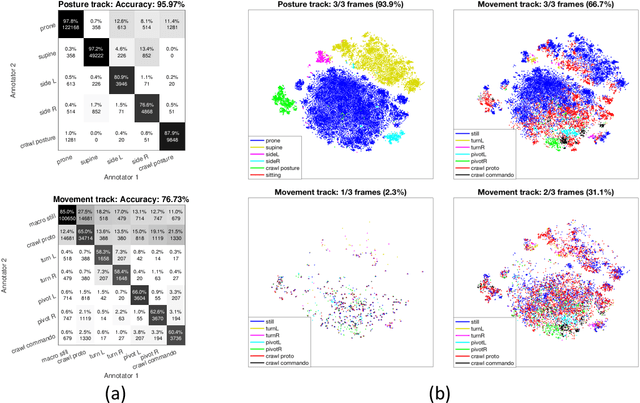

Infant's spontaneous movements mirror integrity of brain networks, and thus also predict the future development of higher cognitive functions. Early recognition of infants with compromised motor development holds promise for guiding early therapies to improve lifelong neurocognitive outcomes. It has been challenging, however, to assess motor performance in ways that are objective and quantitative. Novel wearable technology has shown promise for offering efficient, scalable and automated methods in movement assessment. Here, we describe the development of an infant wearable, a multi-sensor smart jumpsuit that allows mobile data collection during independent movements. A deep learning algorithm, based on convolutional neural networks (CNNs), was then trained using multiple human annotations that incorporate the substantial inherent ambiguity in movement classifications. We also quantify the substantial ambiguity of a human observer, allowing its transfer to improving the automated classifier. Comparison of different sensor configurations and classifier designs shows that four-limb recording and end-to-end CNN classifier architecture allows the best movement classification. Our results show that quantitative tracking of independent movement activities is possible with a human equivalent accuracy, i.e. it meets the human inter-rater agreement levels in infant posture and movement classification.
Speaker-independent raw waveform model for glottal excitation
Apr 25, 2018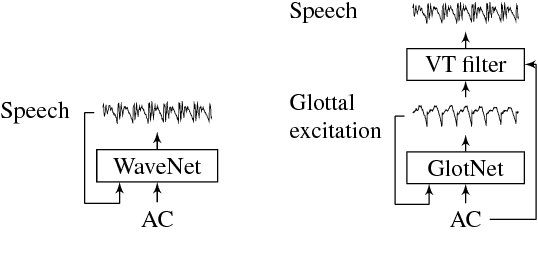


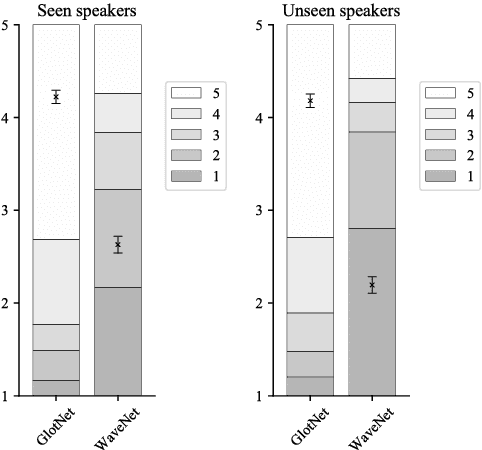
Recent speech technology research has seen a growing interest in using WaveNets as statistical vocoders, i.e., generating speech waveforms from acoustic features. These models have been shown to improve the generated speech quality over classical vocoders in many tasks, such as text-to-speech synthesis and voice conversion. Furthermore, conditioning WaveNets with acoustic features allows sharing the waveform generator model across multiple speakers without additional speaker codes. However, multi-speaker WaveNet models require large amounts of training data and computation to cover the entire acoustic space. This paper proposes leveraging the source-filter model of speech production to more effectively train a speaker-independent waveform generator with limited resources. We present a multi-speaker 'GlotNet' vocoder, which utilizes a WaveNet to generate glottal excitation waveforms, which are then used to excite the corresponding vocal tract filter to produce speech. Listening tests show that the proposed model performs favourably to a direct WaveNet vocoder trained with the same model architecture and data.
Speech waveform synthesis from MFCC sequences with generative adversarial networks
Apr 03, 2018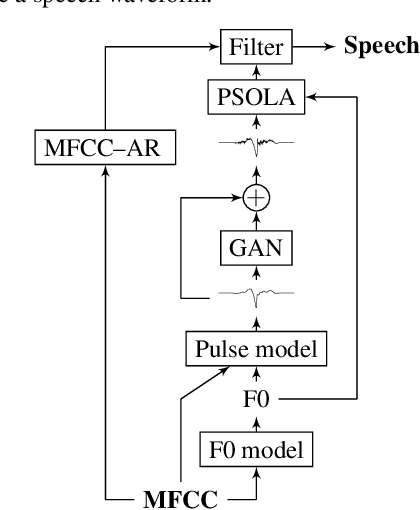
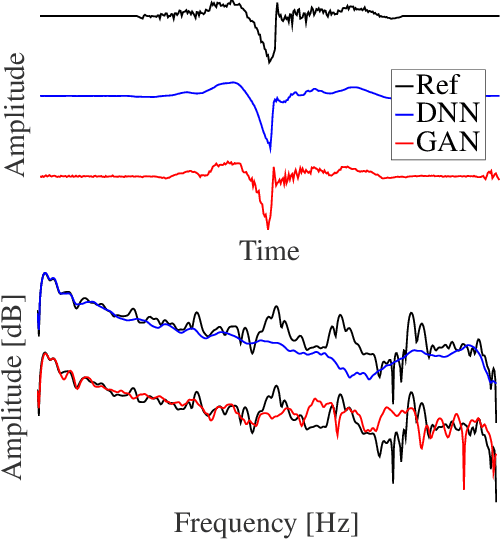
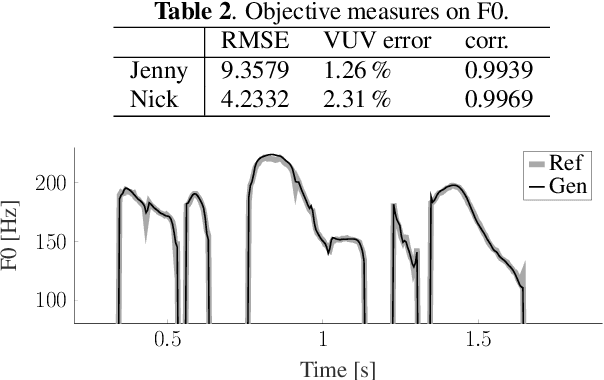

This paper proposes a method for generating speech from filterbank mel frequency cepstral coefficients (MFCC), which are widely used in speech applications, such as ASR, but are generally considered unusable for speech synthesis. First, we predict fundamental frequency and voicing information from MFCCs with an autoregressive recurrent neural net. Second, the spectral envelope information contained in MFCCs is converted to all-pole filters, and a pitch-synchronous excitation model matched to these filters is trained. Finally, we introduce a generative adversarial network -based noise model to add a realistic high-frequency stochastic component to the modeled excitation signal. The results show that high quality speech reconstruction can be obtained, given only MFCC information at test time.