 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Machine Distinguish High and Low Amount of Social Creak in Speech?
Oct 22, 2024Objectives: ncreased prevalence of social creak particularly among female speakers has been reported in several studies. The study of social creak has been previously conducted by combining perceptual evaluation of speech with conventional acoustical parameters such as the harmonic-to-noise ratio and cepstral peak prominence. In the current study, machine learning (ML) was used to automatically distinguish speech of low amount of social creak from speech of high amount of social creak. Methods: The amount of creak in continuous speech samples produced in Finnish by 90 female speakers was first perceptually assessed by two voice specialists. Based on their assessments, the speech samples were divided into two categories (low $vs$. high amount of creak). Using the speech signals and their creak labels, seven different ML models were trained. Three spectral representations were used as feature for each model. Results: The results show that the best performance (accuracy of 71.1\%) was obtained by the following two systems: an Adaboost classifier using the mel-spectrogram feature and a decision tree classifier using the mel-frequency cepstral coefficient feature. Conclusions: The study of social creak is becoming increasingly popular in sociolinguistic and vocological research. The conventional human perceptual assessment of the amount of creak is laborious and therefore ML technology could be used to assist researchers studying social creak. The classification systems reported in this study could be considered as baselines in future ML-based studies on social creak.
Wav2vec-based Detection and Severity Level Classification of Dysarthria from Speech
Sep 25, 2023
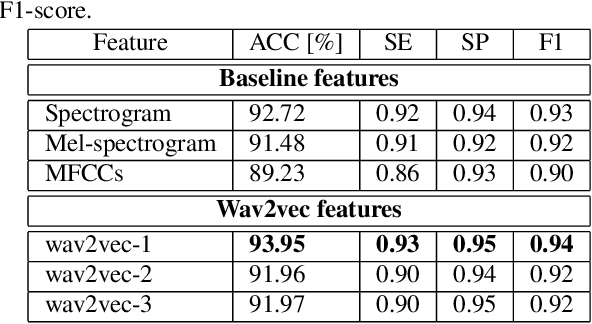
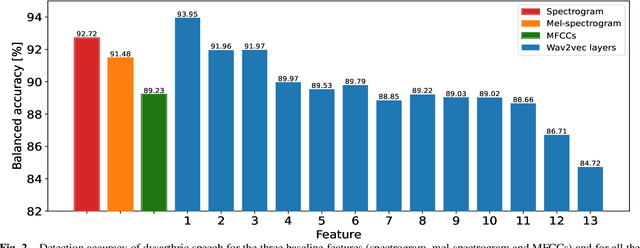
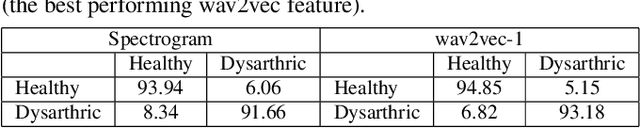
Automatic detection and severity level classification of dysarthria directly from acoustic speech signals can be used as a tool in medical diagnosis. In this work, the pre-trained wav2vec 2.0 model is studied as a feature extractor to build detection and severity level classification systems for dysarthric speech. The experiments were carried out with the popularly used UA-speech database. In the detection experiments, the results revealed that the best performance was obtained using the embeddings from the first layer of the wav2vec model that yielded an absolute improvement of 1.23% in accuracy compared to the best performing baseline feature (spectrogram). In the studied severity level classification task, the results revealed that the embeddings from the final layer gave an absolute improvement of 10.62% in accuracy compared to the best baseline features (mel-frequency cepstral coefficients).
Analysis and Detection of Pathological Voice using Glottal Source Features
Sep 25, 2023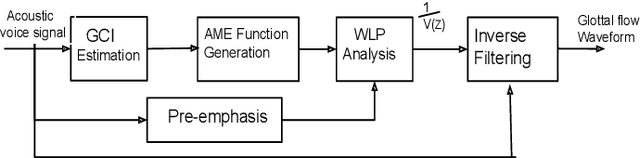
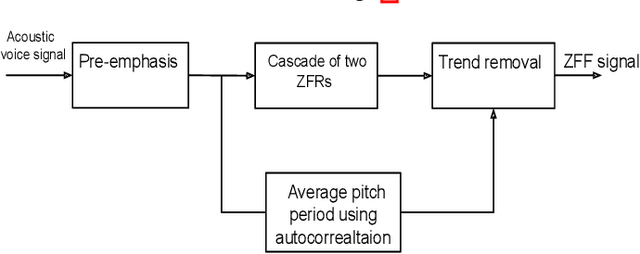
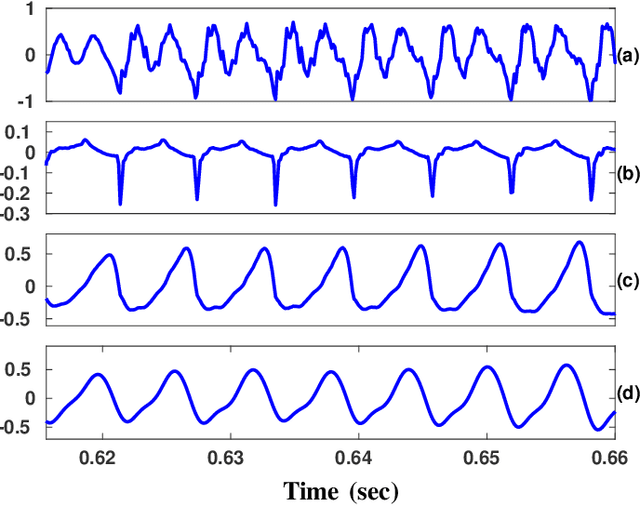
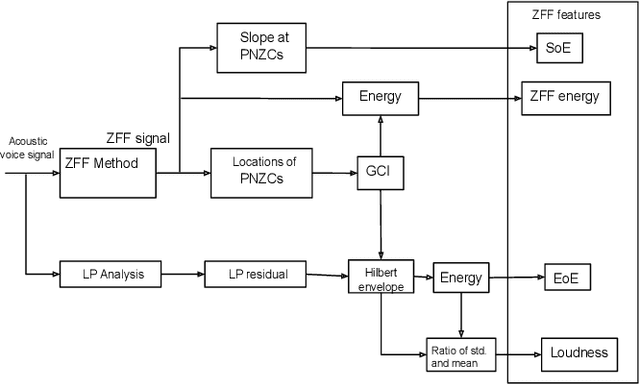
Automatic detection of voice pathology enables objective assessment and earlier intervention for the diagnosis. This study provides a systematic analysis of glottal source features and investigates their effectiveness in voice pathology detection. Glottal source features are extracted using glottal flows estimated with the quasi-closed phase (QCP) glottal inverse filtering method, using approximate glottal source signals computed with the zero frequency filtering (ZFF) method, and using acoustic voice signals directly. In addition, we propose to derive mel-frequency cepstral coefficients (MFCCs) from the glottal source waveforms computed by QCP and ZFF to effectively capture the variations in glottal source spectra of pathological voice. Experiments were carried out using two databases, the Hospital Universitario Principe de Asturias (HUPA) database and the Saarbrucken Voice Disorders (SVD) database. Analysis of features revealed that the glottal source contains information that discriminates normal and pathological voice. Pathology detection experiments were carried out using support vector machine (SVM). From the detection experiments it was observed that the performance achieved with the studied glottal source features is comparable or better than that of conventional MFCCs and perceptual linear prediction (PLP) features. The best detection performance was achieved when the glottal source features were combined with the conventional MFCCs and PLP features, which indicates the complementary nature of the features.
Time-Varying Quasi-Closed-Phase Analysis for Accurate Formant Tracking in Speech Signals
Aug 31, 2023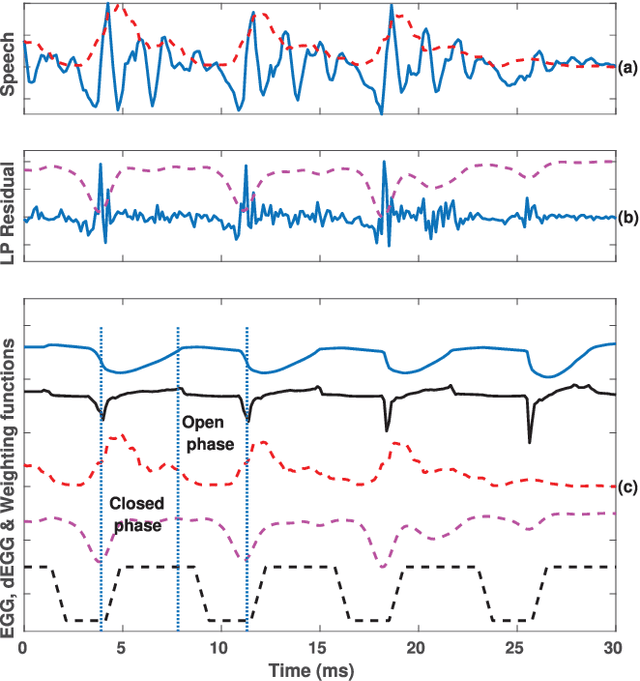
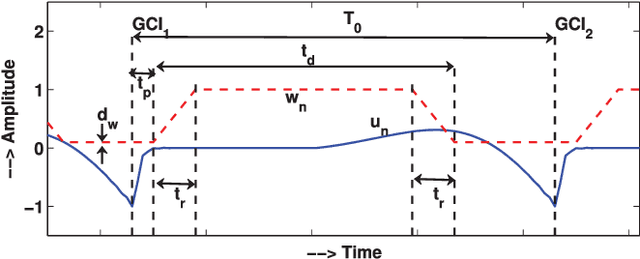

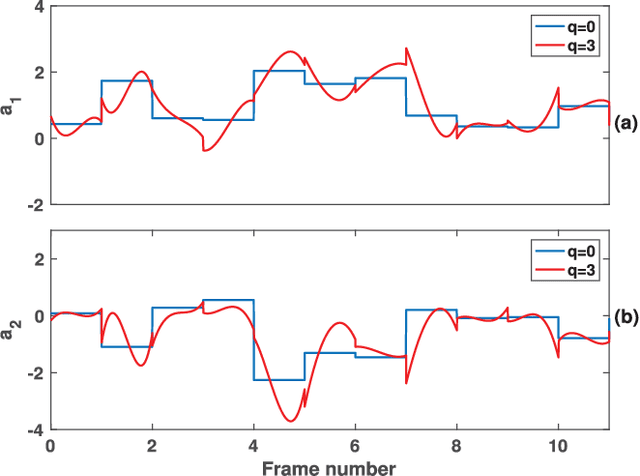
In this paper, we propose a new method for the accurate estimation and tracking of formants in speech signals using time-varying quasi-closed-phase (TVQCP) analysis. Conventional formant tracking methods typically adopt a two-stage estimate-and-track strategy wherein an initial set of formant candidates are estimated using short-time analysis (e.g., 10--50 ms), followed by a tracking stage based on dynamic programming or a linear state-space model. One of the main disadvantages of these approaches is that the tracking stage, however good it may be, cannot improve upon the formant estimation accuracy of the first stage. The proposed TVQCP method provides a single-stage formant tracking that combines the estimation and tracking stages into one. TVQCP analysis combines three approaches to improve formant estimation and tracking: (1) it uses temporally weighted quasi-closed-phase analysis to derive closed-phase estimates of the vocal tract with reduced interference from the excitation source, (2) it increases the residual sparsity by using the $L_1$ optimization and (3) it uses time-varying linear prediction analysis over long time windows (e.g., 100--200 ms) to impose a continuity constraint on the vocal tract model and hence on the formant trajectories. Formant tracking experiments with a wide variety of synthetic and natural speech signals show that the proposed TVQCP method performs better than conventional and popular formant tracking tools, such as Wavesurfer and Praat (based on dynamic programming), the KARMA algorithm (based on Kalman filtering), and DeepFormants (based on deep neural networks trained in a supervised manner). Matlab scripts for the proposed method can be found at: https://github.com/njaygowda/ftrack
Refining a Deep Learning-based Formant Tracker using Linear Prediction Methods
Aug 17, 2023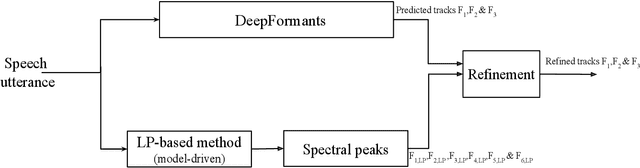
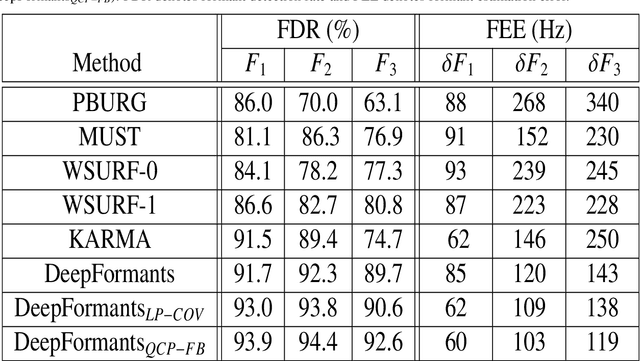
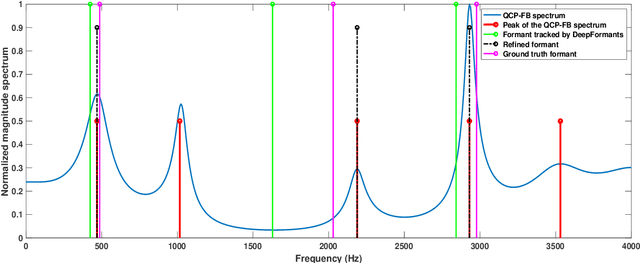
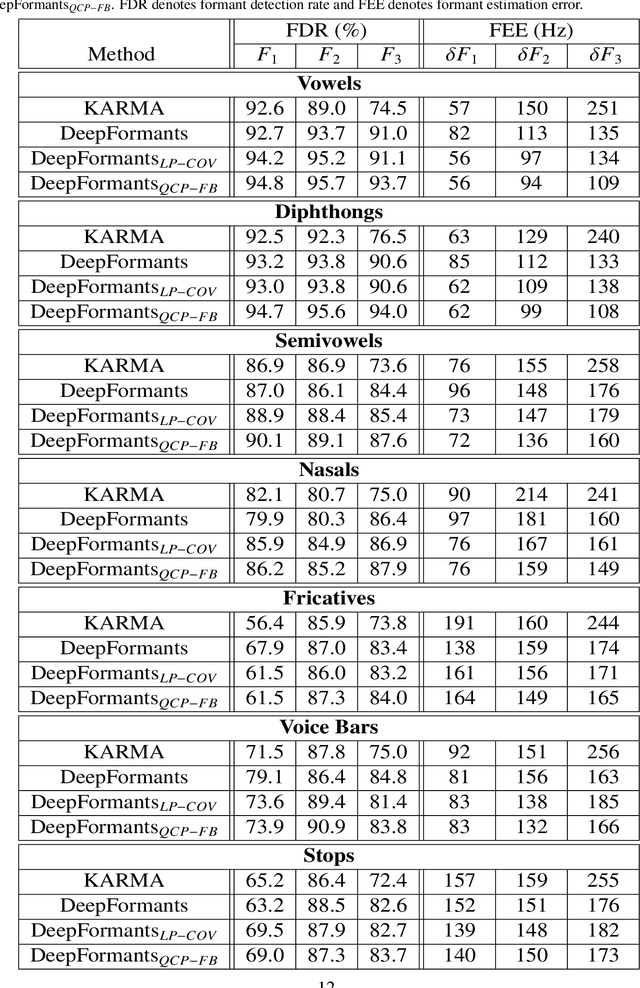
In this study, formant tracking is investigated by refining the formants tracked by an existing data-driven tracker, DeepFormants, using the formants estimated in a model-driven manner by linear prediction (LP)-based methods. As LP-based formant estimation methods, conventional covariance analysis (LP-COV) and the recently proposed quasi-closed phase forward-backward (QCP-FB) analysis are used. In the proposed refinement approach, the contours of the three lowest formants are first predicted by the data-driven DeepFormants tracker, and the predicted formants are replaced frame-wise with local spectral peaks shown by the model-driven LP-based methods. The refinement procedure can be plugged into the DeepFormants tracker with no need for any new data learning. Two refined DeepFormants trackers were compared with the original DeepFormants and with five known traditional trackers using the popular vocal tract resonance (VTR) corpus. The results indicated that the data-driven DeepFormants trackers outperformed the conventional trackers and that the best performance was obtained by refining the formants predicted by DeepFormants using QCP-FB analysis. In addition, by tracking formants using VTR speech that was corrupted by additive noise, the study showed that the refined DeepFormants trackers were more resilient to noise than the reference trackers. In general, these results suggest that LP-based model-driven approaches, which have traditionally been used in formant estimation, can be combined with a modern data-driven tracker easily with no further training to improve the tracker's performance.
Severity Classification of Parkinson's Disease from Speech using Single Frequency Filtering-based Features
Aug 17, 2023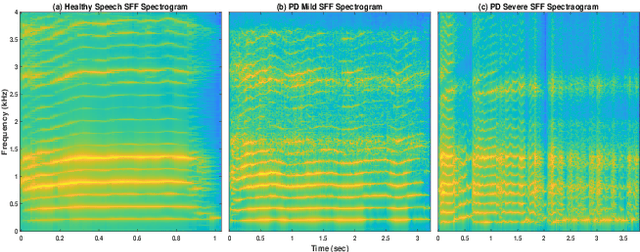
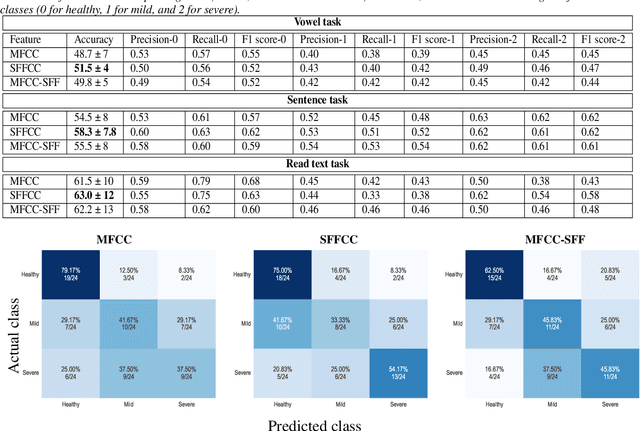
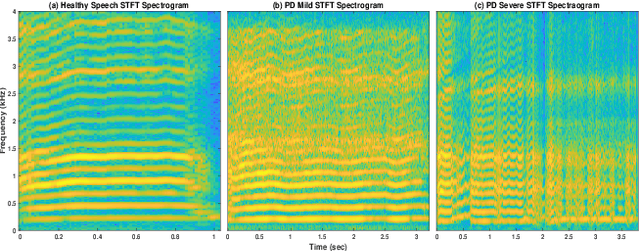
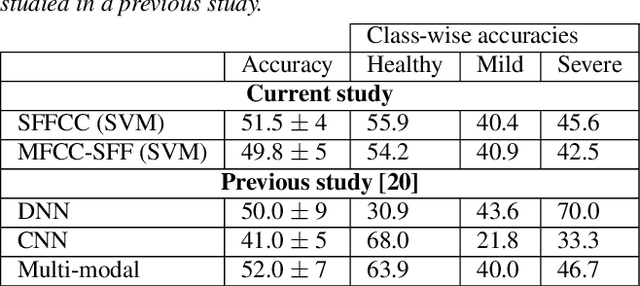
Developing objective methods for assessing the severity of Parkinson's disease (PD) is crucial for improving the diagnosis and treatment. This study proposes two sets of novel features derived from the single frequency filtering (SFF) method: (1) SFF cepstral coefficients (SFFCC) and (2) MFCCs from the SFF (MFCC-SFF) for the severity classification of PD. Prior studies have demonstrated that SFF offers greater spectro-temporal resolution compared to the short-time Fourier transform. The study uses the PC-GITA database, which includes speech of PD patients and healthy controls produced in three speaking tasks (vowels, sentences, text reading). Experiments using the SVM classifier revealed that the proposed features outperformed the conventional MFCCs in all three speaking tasks. The proposed SFFCC and MFCC-SFF features gave a relative improvement of 5.8% and 2.3% for the vowel task, 7.0% & 1.8% for the sentence task, and 2.4% and 1.1% for the read text task, in comparison to MFCC features.
Investigation of Self-supervised Pre-trained Models for Classification of Voice Quality from Speech and Neck Surface Accelerometer Signals
Aug 06, 2023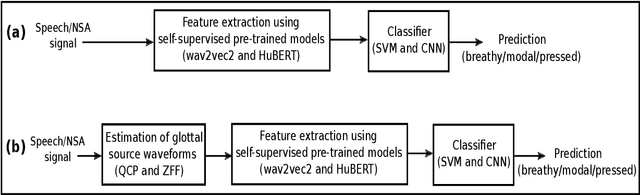

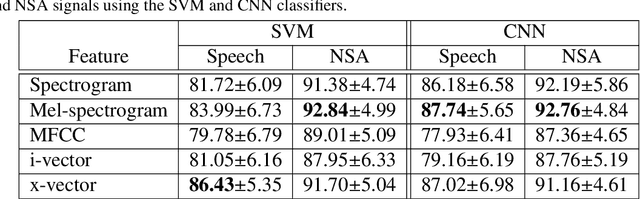
Prior studies in the automatic classification of voice quality have mainly studied the use of the acoustic speech signal as input. Recently, a few studies have been carried out by jointly using both speech and neck surface accelerometer (NSA) signals as inputs, and by extracting MFCCs and glottal source features. This study examines simultaneously-recorded speech and NSA signals in the classification of voice quality (breathy, modal, and pressed) using features derived from three self-supervised pre-trained models (wav2vec2-BASE, wav2vec2-LARGE, and HuBERT) and using a SVM as well as CNNs as classifiers. Furthermore, the effectiveness of the pre-trained models is compared in feature extraction between glottal source waveforms and raw signal waveforms for both speech and NSA inputs. Using two signal processing methods (quasi-closed phase (QCP) glottal inverse filtering and zero frequency filtering (ZFF)), glottal source waveforms are estimated from both speech and NSA signals. The study has three main goals: (1) to study whether features derived from pre-trained models improve classification accuracy compared to conventional features (spectrogram, mel-spectrogram, MFCCs, i-vector, and x-vector), (2) to investigate which of the two modalities (speech vs. NSA) is more effective in the classification task with pre-trained model-based features, and (3) to evaluate whether the deep learning-based CNN classifier can enhance the classification accuracy in comparison to the SVM classifier. The results revealed that the use of the NSA input showed better classification performance compared to the speech signal. Between the features, the pre-trained model-based features showed better classification accuracies, both for speech and NSA inputs compared to the conventional features. It was also found that the HuBERT features performed better than the wav2vec2-BASE and wav2vec2-LARGE features.
Formant Tracking Using Quasi-Closed Phase Forward-Backward Linear Prediction Analysis and Deep Neural Networks
Jan 05, 2022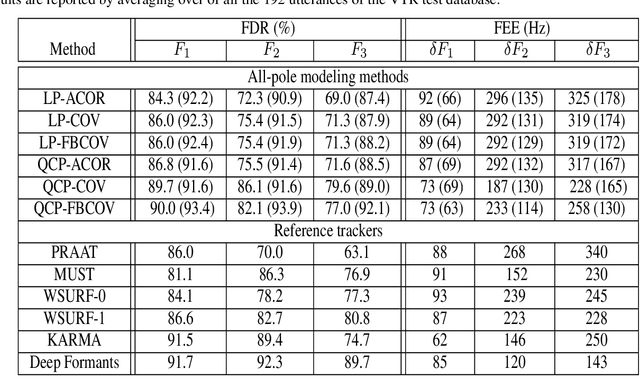
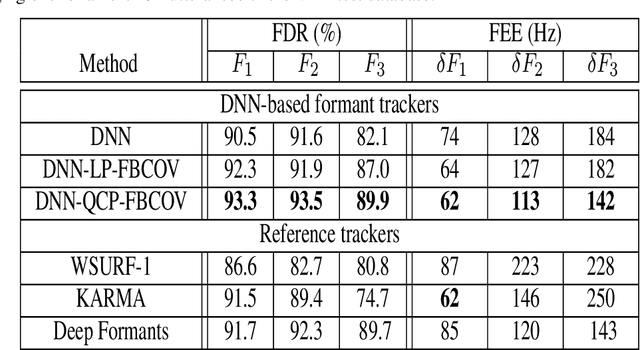
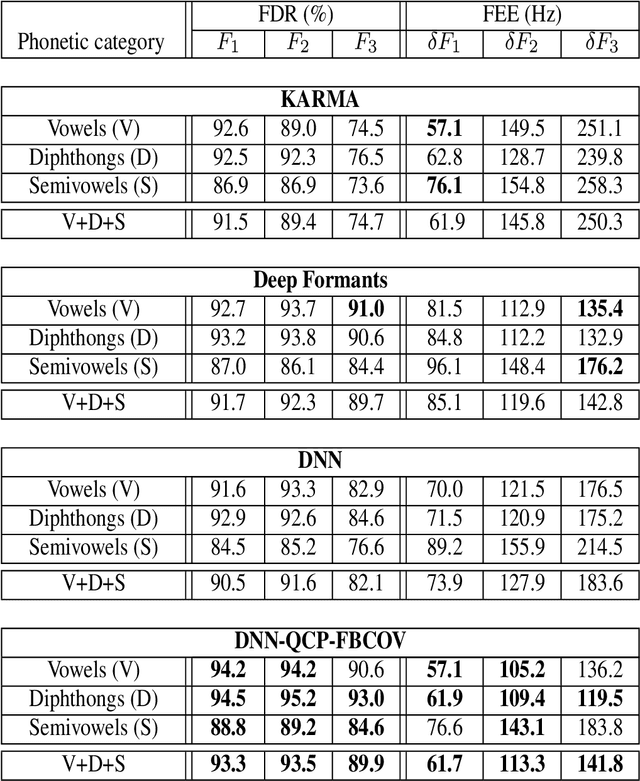
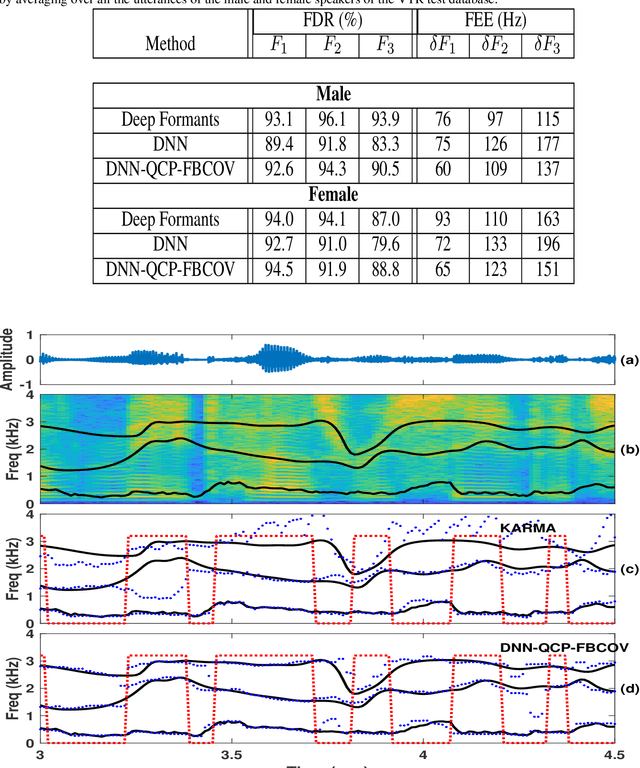
Formant tracking is investigated in this study by using trackers based on dynamic programming (DP) and deep neural nets (DNNs). Using the DP approach, six formant estimation methods were first compared. The six methods include linear prediction (LP) algorithms, weighted LP algorithms and the recently developed quasi-closed phase forward-backward (QCP-FB) method. QCP-FB gave the best performance in the comparison. Therefore, a novel formant tracking approach, which combines benefits of deep learning and signal processing based on QCP-FB, was proposed. In this approach, the formants predicted by a DNN-based tracker from a speech frame are refined using the peaks of the all-pole spectrum computed by QCP-FB from the same frame. Results show that the proposed DNN-based tracker performed better both in detection rate and estimation error for the lowest three formants compared to reference formant trackers. Compared to the popular Wavesurfer, for example, the proposed tracker gave a reduction of 29%, 48% and 35% in the estimation error for the lowest three formants, respectively.
Glottal Source Processing: from Analysis to Applications
Dec 29, 2019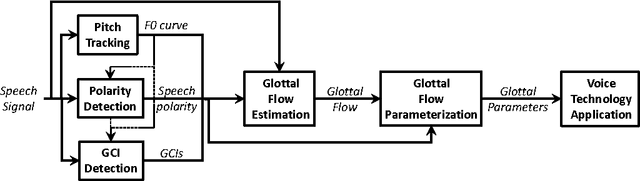
The great majority of current voice technology applications relies on acoustic features characterizing the vocal tract response, such as the widely used MFCC of LPC parameters. Nonetheless, the airflow passing through the vocal folds, and called glottal flow, is expected to exhibit a relevant complementarity. Unfortunately, glottal analysis from speech recordings requires specific and more complex processing operations, which explains why it has been generally avoided. This review gives a general overview of techniques which have been designed for glottal source processing. Starting from fundamental analysis tools of pitch tracking, glottal closure instant detection, glottal flow estimation and modelling, this paper then highlights how these solutions can be properly integrated within various voice technology applications.
GELP: GAN-Excited Linear Prediction for Speech Synthesis from Mel-spectrogram
Apr 10, 2019
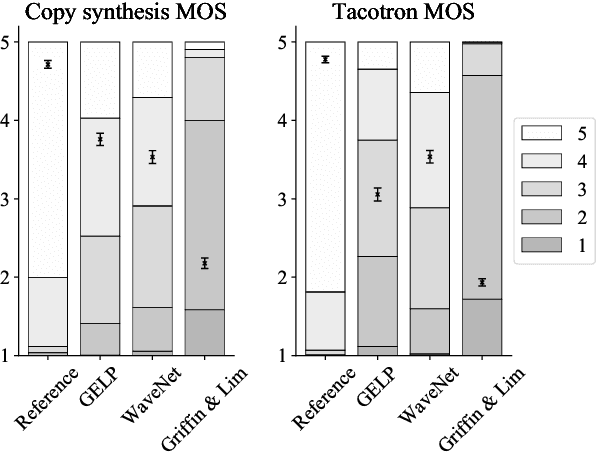
Recent advances in neural network -based text-to-speech have reached human level naturalness in synthetic speech. The present sequence-to-sequence models can directly map text to mel-spectrogram acoustic features, which are convenient for modeling, but present additional challenges for vocoding (i.e., waveform generation from the acoustic features). High-quality synthesis can be achieved with neural vocoders, such as WaveNet, but such autoregressive models suffer from slow sequential inference. Meanwhile, their existing parallel inference counterparts are difficult to train and require increasingly large model sizes. In this paper, we propose an alternative training strategy for a parallel neural vocoder utilizing generative adversarial networks, and integrate a linear predictive synthesis filter into the model. Results show that the proposed model achieves significant improvement in inference speed, while outperforming a WaveNet in copy-synthesis quality.