 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWav2vec-based Detection and Severity Level Classification of Dysarthria from Speech
Sep 25, 2023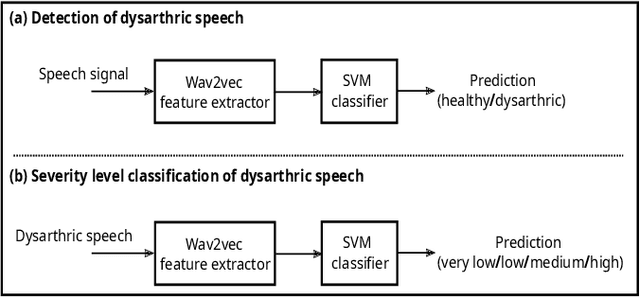
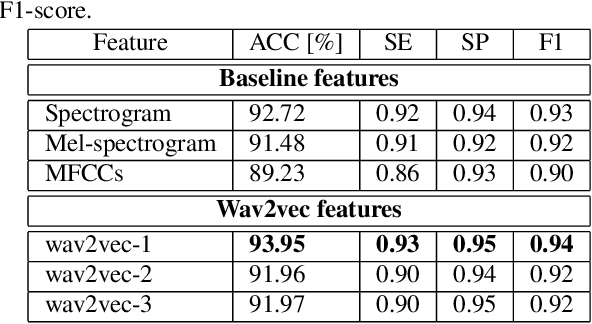
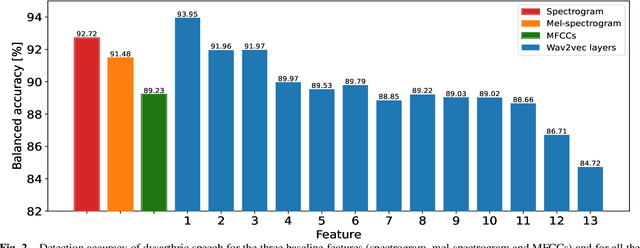
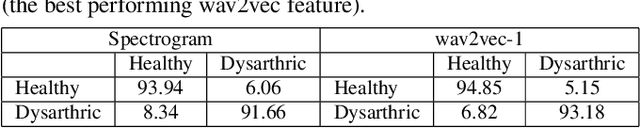
Automatic detection and severity level classification of dysarthria directly from acoustic speech signals can be used as a tool in medical diagnosis. In this work, the pre-trained wav2vec 2.0 model is studied as a feature extractor to build detection and severity level classification systems for dysarthric speech. The experiments were carried out with the popularly used UA-speech database. In the detection experiments, the results revealed that the best performance was obtained using the embeddings from the first layer of the wav2vec model that yielded an absolute improvement of 1.23% in accuracy compared to the best performing baseline feature (spectrogram). In the studied severity level classification task, the results revealed that the embeddings from the final layer gave an absolute improvement of 10.62% in accuracy compared to the best baseline features (mel-frequency cepstral coefficients).