 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgevoice2mode: Phonation Mode Classification in Singing using Self-Supervised Speech Models
Feb 14, 2026We present voice2mode, a method for classification of four singing phonation modes (breathy, neutral (modal), flow, and pressed) using embeddings extracted from large self-supervised speech models. Prior work on singing phonation has relied on handcrafted signal features or task-specific neural nets; this work evaluates the transferability of speech foundation models to singing phonation classification. voice2mode extracts layer-wise representations from HuBERT and two wav2vec2 variants, applies global temporal pooling, and classifies the pooled embeddings with lightweight classifiers (SVM, XGBoost). Experiments on a publicly available soprano dataset (763 sustained vowel recordings, four labels) show that foundation-model features substantially outperform conventional spectral baselines (spectrogram, mel-spectrogram, MFCC). HuBERT embeddings obtained from early layers yield the best result (~95.7% accuracy with SVM), an absolute improvement of ~12-15% over the best traditional baseline. We also show layer-wise behaviour: lower layers, which retain acoustic/phonetic detail, are more effective than top layers specialized for Automatic Speech Recognition (ASR).
Zero-Shot KWS for Children's Speech using Layer-Wise Features from SSL Models
Aug 28, 2025Numerous methods have been proposed to enhance Keyword Spotting (KWS) in adult speech, but children's speech presents unique challenges for KWS systems due to its distinct acoustic and linguistic characteristics. This paper introduces a zero-shot KWS approach that leverages state-of-the-art self-supervised learning (SSL) models, including Wav2Vec2, HuBERT and Data2Vec. Features are extracted layer-wise from these SSL models and used to train a Kaldi-based DNN KWS system. The WSJCAM0 adult speech dataset was used for training, while the PFSTAR children's speech dataset was used for testing, demonstrating the zero-shot capability of our method. Our approach achieved state-of-the-art results across all keyword sets for children's speech. Notably, the Wav2Vec2 model, particularly layer 22, performed the best, delivering an ATWV score of 0.691, a MTWV score of 0.7003 and probability of false alarm and probability of miss of 0.0164 and 0.0547 respectively, for a set of 30 keywords. Furthermore, age-specific performance evaluation confirmed the system's effectiveness across different age groups of children. To assess the system's robustness against noise, additional experiments were conducted using the best-performing layer of the best-performing Wav2Vec2 model. The results demonstrated a significant improvement over traditional MFCC-based baseline, emphasizing the potential of SSL embeddings even in noisy conditions. To further generalize the KWS framework, the experiments were repeated for an additional CMU dataset. Overall the results highlight the significant contribution of SSL features in enhancing Zero-Shot KWS performance for children's speech, effectively addressing the challenges associated with the distinct characteristics of child speakers.
* Accepted
Can Layer-wise SSL Features Improve Zero-Shot ASR Performance for Children's Speech?
Aug 28, 2025Automatic Speech Recognition (ASR) systems often struggle to accurately process children's speech due to its distinct and highly variable acoustic and linguistic characteristics. While recent advancements in self-supervised learning (SSL) models have greatly enhanced the transcription of adult speech, accurately transcribing children's speech remains a significant challenge. This study investigates the effectiveness of layer-wise features extracted from state-of-the-art SSL pre-trained models - specifically, Wav2Vec2, HuBERT, Data2Vec, and WavLM in improving the performance of ASR for children's speech in zero-shot scenarios. A detailed analysis of features extracted from these models was conducted, integrating them into a simplified DNN-based ASR system using the Kaldi toolkit. The analysis identified the most effective layers for enhancing ASR performance on children's speech in a zero-shot scenario, where WSJCAM0 adult speech was used for training and PFSTAR children speech for testing. Experimental results indicated that Layer 22 of the Wav2Vec2 model achieved the lowest Word Error Rate (WER) of 5.15%, representing a 51.64% relative improvement over the direct zero-shot decoding using Wav2Vec2 (WER of 10.65%). Additionally, age group-wise analysis demonstrated consistent performance improvements with increasing age, along with significant gains observed even in younger age groups using the SSL features. Further experiments on the CMU Kids dataset confirmed similar trends, highlighting the generalizability of the proposed approach.
* Accepted
Towards disentangling the contributions of articulation and acoustics in multimodal phoneme recognition
May 29, 2025Although many previous studies have carried out multimodal learning with real-time MRI data that captures the audio-visual kinematics of the vocal tract during speech, these studies have been limited by their reliance on multi-speaker corpora. This prevents such models from learning a detailed relationship between acoustics and articulation due to considerable cross-speaker variability. In this study, we develop unimodal audio and video models as well as multimodal models for phoneme recognition using a long-form single-speaker MRI corpus, with the goal of disentangling and interpreting the contributions of each modality. Audio and multimodal models show similar performance on different phonetic manner classes but diverge on places of articulation. Interpretation of the models' latent space shows similar encoding of the phonetic space across audio and multimodal models, while the models' attention weights highlight differences in acoustic and articulatory timing for certain phonemes.
Enhancing Listened Speech Decoding from EEG via Parallel Phoneme Sequence Prediction
Jan 08, 2025



Brain-computer interfaces (BCI) offer numerous human-centered application possibilities, particularly affecting people with neurological disorders. Text or speech decoding from brain activities is a relevant domain that could augment the quality of life for people with impaired speech perception. We propose a novel approach to enhance listened speech decoding from electroencephalography (EEG) signals by utilizing an auxiliary phoneme predictor that simultaneously decodes textual phoneme sequences. The proposed model architecture consists of three main parts: EEG module, speech module, and phoneme predictor. The EEG module learns to properly represent EEG signals into EEG embeddings. The speech module generates speech waveforms from the EEG embeddings. The phoneme predictor outputs the decoded phoneme sequences in text modality. Our proposed approach allows users to obtain decoded listened speech from EEG signals in both modalities (speech waveforms and textual phoneme sequences) simultaneously, eliminating the need for a concatenated sequential pipeline for each modality. The proposed approach also outperforms previous methods in both modalities. The source code and speech samples are publicly available.
Can a Machine Distinguish High and Low Amount of Social Creak in Speech?
Oct 22, 2024Objectives: ncreased prevalence of social creak particularly among female speakers has been reported in several studies. The study of social creak has been previously conducted by combining perceptual evaluation of speech with conventional acoustical parameters such as the harmonic-to-noise ratio and cepstral peak prominence. In the current study, machine learning (ML) was used to automatically distinguish speech of low amount of social creak from speech of high amount of social creak. Methods: The amount of creak in continuous speech samples produced in Finnish by 90 female speakers was first perceptually assessed by two voice specialists. Based on their assessments, the speech samples were divided into two categories (low $vs$. high amount of creak). Using the speech signals and their creak labels, seven different ML models were trained. Three spectral representations were used as feature for each model. Results: The results show that the best performance (accuracy of 71.1\%) was obtained by the following two systems: an Adaboost classifier using the mel-spectrogram feature and a decision tree classifier using the mel-frequency cepstral coefficient feature. Conclusions: The study of social creak is becoming increasingly popular in sociolinguistic and vocological research. The conventional human perceptual assessment of the amount of creak is laborious and therefore ML technology could be used to assist researchers studying social creak. The classification systems reported in this study could be considered as baselines in future ML-based studies on social creak.
Evaluation of state-of-the-art ASR Models in Child-Adult Interactions
Sep 24, 2024



The ability to reliably transcribe child-adult conversations in a clinical setting is valuable for diagnosis and understanding of numerous developmental disorders such as Autism Spectrum Disorder. Recent advances in deep learning architectures and availability of large scale transcribed data has led to development of speech foundation models that have shown dramatic improvements in ASR performance. However, the ability of these models to translate well to conversational child-adult interactions is under studied. In this work, we provide a comprehensive evaluation of ASR performance on a dataset containing child-adult interactions from autism diagnostic sessions, using Whisper, Wav2Vec2, HuBERT, and WavLM. We find that speech foundation models show a noticeable performance drop (15-20% absolute WER) for child speech compared to adult speech in the conversational setting. Then, we employ LoRA on the best performing zero shot model (whisper-large) to probe the effectiveness of fine-tuning in a low resource setting, resulting in ~8% absolute WER improvement for child speech and ~13% absolute WER improvement for adult speech.
MMSD-Net: Towards Multi-modal Stuttering Detection
Jul 16, 2024Stuttering is a common speech impediment that is caused by irregular disruptions in speech production, affecting over 70 million people across the world. Standard automatic speech processing tools do not take speech ailments into account and are thereby not able to generate meaningful results when presented with stuttered speech as input. The automatic detection of stuttering is an integral step towards building efficient, context-aware speech processing systems. While previous approaches explore both statistical and neural approaches for stuttering detection, all of these methods are uni-modal in nature. This paper presents MMSD-Net, the first multi-modal neural framework for stuttering detection. Experiments and results demonstrate that incorporating the visual signal significantly aids stuttering detection, and our model yields an improvement of 2-17% in the F1-score over existing state-of-the-art uni-modal approaches.
Analysis and Detection of Pathological Voice using Glottal Source Features
Sep 25, 2023Automatic detection of voice pathology enables objective assessment and earlier intervention for the diagnosis. This study provides a systematic analysis of glottal source features and investigates their effectiveness in voice pathology detection. Glottal source features are extracted using glottal flows estimated with the quasi-closed phase (QCP) glottal inverse filtering method, using approximate glottal source signals computed with the zero frequency filtering (ZFF) method, and using acoustic voice signals directly. In addition, we propose to derive mel-frequency cepstral coefficients (MFCCs) from the glottal source waveforms computed by QCP and ZFF to effectively capture the variations in glottal source spectra of pathological voice. Experiments were carried out using two databases, the Hospital Universitario Principe de Asturias (HUPA) database and the Saarbrucken Voice Disorders (SVD) database. Analysis of features revealed that the glottal source contains information that discriminates normal and pathological voice. Pathology detection experiments were carried out using support vector machine (SVM). From the detection experiments it was observed that the performance achieved with the studied glottal source features is comparable or better than that of conventional MFCCs and perceptual linear prediction (PLP) features. The best detection performance was achieved when the glottal source features were combined with the conventional MFCCs and PLP features, which indicates the complementary nature of the features.
Wav2vec-based Detection and Severity Level Classification of Dysarthria from Speech
Sep 25, 2023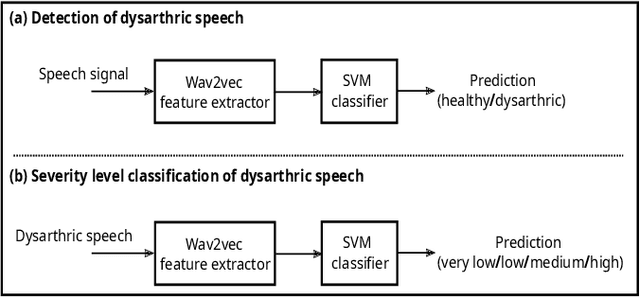
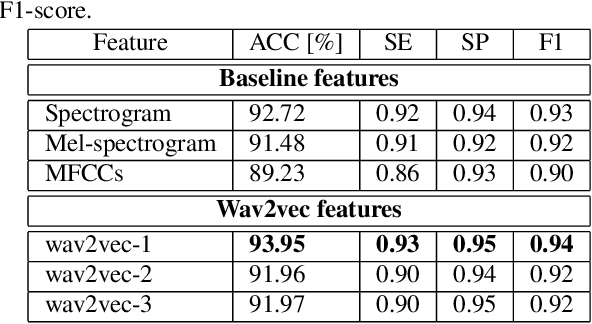
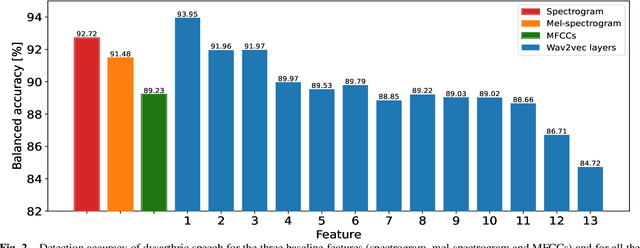
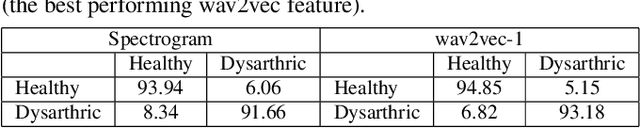
Automatic detection and severity level classification of dysarthria directly from acoustic speech signals can be used as a tool in medical diagnosis. In this work, the pre-trained wav2vec 2.0 model is studied as a feature extractor to build detection and severity level classification systems for dysarthric speech. The experiments were carried out with the popularly used UA-speech database. In the detection experiments, the results revealed that the best performance was obtained using the embeddings from the first layer of the wav2vec model that yielded an absolute improvement of 1.23% in accuracy compared to the best performing baseline feature (spectrogram). In the studied severity level classification task, the results revealed that the embeddings from the final layer gave an absolute improvement of 10.62% in accuracy compared to the best baseline features (mel-frequency cepstral coefficients).