 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Joint ASR and Speaker Role Diarization with Child-Adult Interactions
Jan 25, 2026Accurate transcription and speaker diarization of child-adult spoken interactions are crucial for developmental and clinical research. However, manual annotation is time-consuming and challenging to scale. Existing automated systems typically rely on cascaded speaker diarization and speech recognition pipelines, which can lead to error propagation. This paper presents a unified end-to-end framework that extends the Whisper encoder-decoder architecture to jointly model ASR and child-adult speaker role diarization. The proposed approach integrates: (i) a serialized output training scheme that emits speaker tags and start/end timestamps, (ii) a lightweight frame-level diarization head that enhances speaker-discriminative encoder representations, (iii) diarization-guided silence suppression for improved temporal precision, and (iv) a state-machine-based forced decoding procedure that guarantees structurally valid outputs. Comprehensive evaluations on two datasets demonstrate consistent and substantial improvements over two cascaded baselines, achieving lower multi-talker word error rates and demonstrating competitive diarization accuracy across both Whisper-small and Whisper-large models. These findings highlight the effectiveness and practical utility of the proposed joint modeling framework for generating reliable, speaker-attributed transcripts of child-adult interactions at scale. The code and model weights are publicly available
Large Language Models based ASR Error Correction for Child Conversations
May 22, 2025
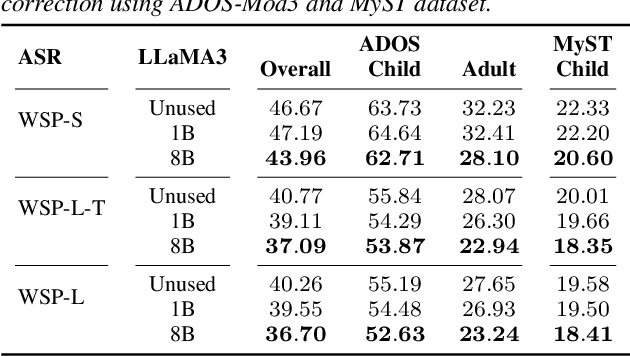


Automatic Speech Recognition (ASR) has recently shown remarkable progress, but accurately transcribing children's speech remains a significant challenge. Recent developments in Large Language Models (LLMs) have shown promise in improving ASR transcriptions. However, their applications in child speech including conversational scenarios are underexplored. In this study, we explore the use of LLMs in correcting ASR errors for conversational child speech. We demonstrate the promises and challenges of LLMs through experiments on two children's conversational speech datasets with both zero-shot and fine-tuned ASR outputs. We find that while LLMs are helpful in correcting zero-shot ASR outputs and fine-tuned CTC-based ASR outputs, it remains challenging for LLMs to improve ASR performance when incorporating contextual information or when using fine-tuned autoregressive ASR (e.g., Whisper) outputs.
Can Generic LLMs Help Analyze Child-adult Interactions Involving Children with Autism in Clinical Observation?
Nov 16, 2024



Large Language Models (LLMs) have shown significant potential in understanding human communication and interaction. However, their performance in the domain of child-inclusive interactions, including in clinical settings, remains less explored. In this work, we evaluate generic LLMs' ability to analyze child-adult dyadic interactions in a clinically relevant context involving children with ASD. Specifically, we explore LLMs in performing four tasks: classifying child-adult utterances, predicting engaged activities, recognizing language skills and understanding traits that are clinically relevant. Our evaluation shows that generic LLMs are highly capable of analyzing long and complex conversations in clinical observation sessions, often surpassing the performance of non-expert human evaluators. The results show their potential to segment interactions of interest, assist in language skills evaluation, identify engaged activities, and offer clinical-relevant context for assessments.
Evaluation of state-of-the-art ASR Models in Child-Adult Interactions
Sep 24, 2024



The ability to reliably transcribe child-adult conversations in a clinical setting is valuable for diagnosis and understanding of numerous developmental disorders such as Autism Spectrum Disorder. Recent advances in deep learning architectures and availability of large scale transcribed data has led to development of speech foundation models that have shown dramatic improvements in ASR performance. However, the ability of these models to translate well to conversational child-adult interactions is under studied. In this work, we provide a comprehensive evaluation of ASR performance on a dataset containing child-adult interactions from autism diagnostic sessions, using Whisper, Wav2Vec2, HuBERT, and WavLM. We find that speech foundation models show a noticeable performance drop (15-20% absolute WER) for child speech compared to adult speech in the conversational setting. Then, we employ LoRA on the best performing zero shot model (whisper-large) to probe the effectiveness of fine-tuning in a low resource setting, resulting in ~8% absolute WER improvement for child speech and ~13% absolute WER improvement for adult speech.
Egocentric Speaker Classification in Child-Adult Dyadic Interactions: From Sensing to Computational Modeling
Sep 14, 2024
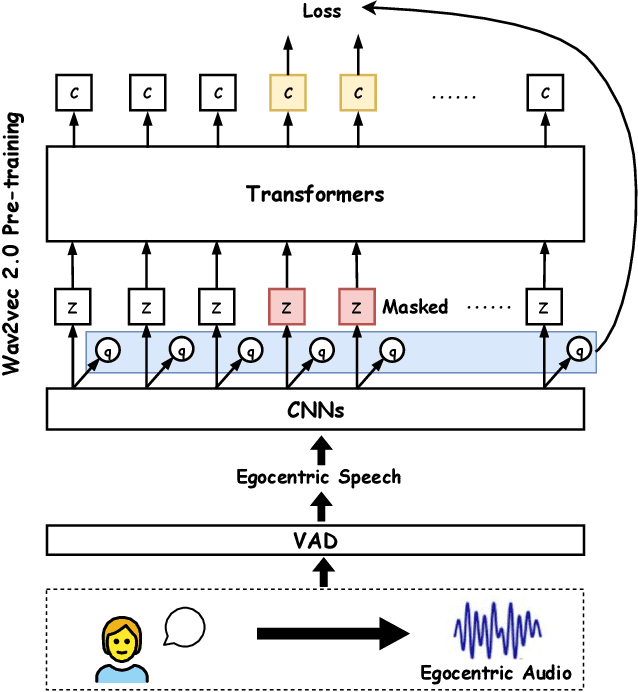
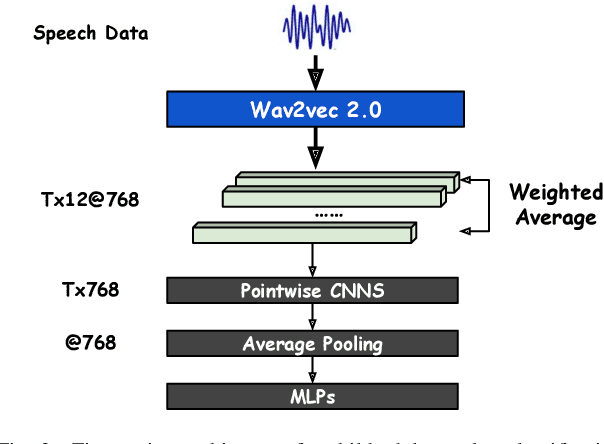
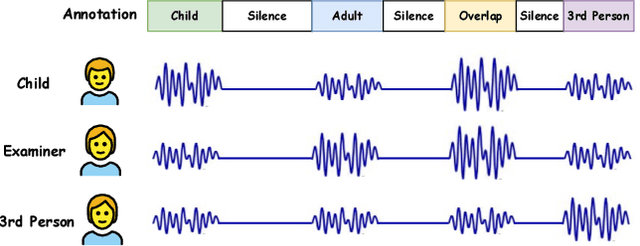
Autism spectrum disorder (ASD) is a neurodevelopmental condition characterized by challenges in social communication, repetitive behavior, and sensory processing. One important research area in ASD is evaluating children's behavioral changes over time during treatment. The standard protocol with this objective is BOSCC, which involves dyadic interactions between a child and clinicians performing a pre-defined set of activities. A fundamental aspect of understanding children's behavior in these interactions is automatic speech understanding, particularly identifying who speaks and when. Conventional approaches in this area heavily rely on speech samples recorded from a spectator perspective, and there is limited research on egocentric speech modeling. In this study, we design an experiment to perform speech sampling in BOSCC interviews from an egocentric perspective using wearable sensors and explore pre-training Ego4D speech samples to enhance child-adult speaker classification in dyadic interactions. Our findings highlight the potential of egocentric speech collection and pre-training to improve speaker classification accuracy.
Phone Duration Modeling for Speaker Age Estimation in Children
Sep 03, 2021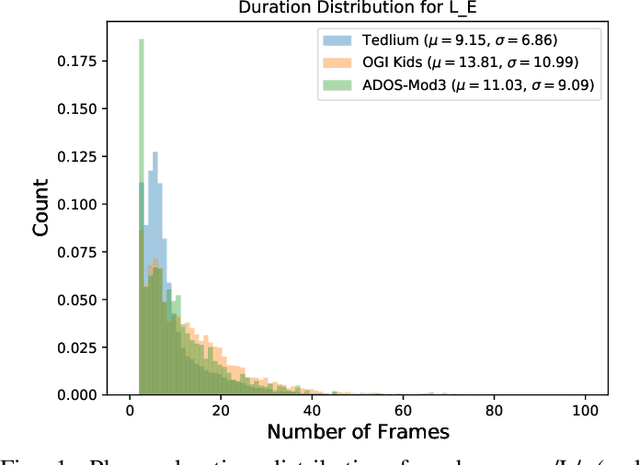
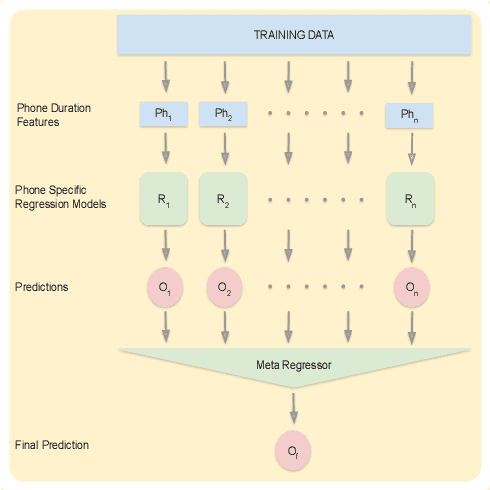
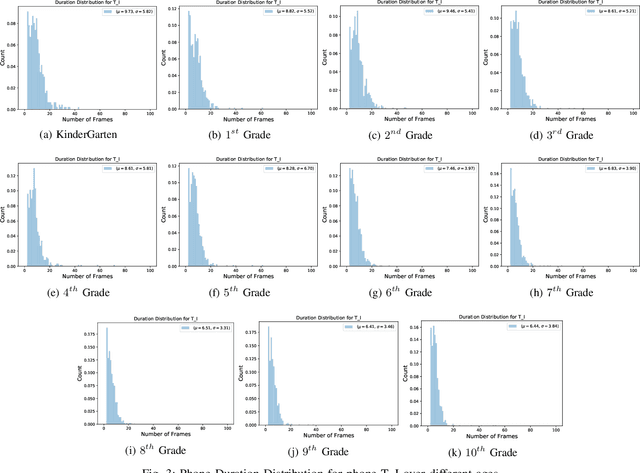
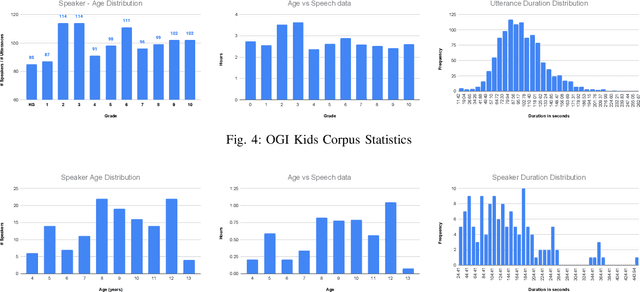
Automatic inference of important paralinguistic information such as age from speech is an important area of research with numerous spoken language technology based applications. Speaker age estimation has applications in enabling personalization and age-appropriate curation of information and content. However, research in speaker age estimation in children is especially challenging due to paucity of relevant speech data representing the developmental spectrum, and the high signal variability especially intra age variability that complicates modeling. Most approaches in children speaker age estimation adopt methods directly from research on adult speech processing. In this paper, we propose features specific to children and focus on speaker's phone duration as an important biomarker of children's age. We propose phone duration modeling for predicting age from child's speech. To enable that, children speech is first forced aligned with the corresponding transcription to derive phone duration distributions. Statistical functionals are computed from phone duration distributions for each phoneme which are in turn used to train regression models to predict speaker age. Two children speech datasets are employed to demonstrate the robustness of phone duration features. We perform age regression experiments on age categories ranging from children studying in kindergarten to grade 10. Experimental results suggest phone durations contain important development-related information of children. Phonemes contributing most to estimation of children speaker age are analyzed and presented.
Learning Domain Invariant Representations for Child-Adult Classification from Speech
Oct 25, 2019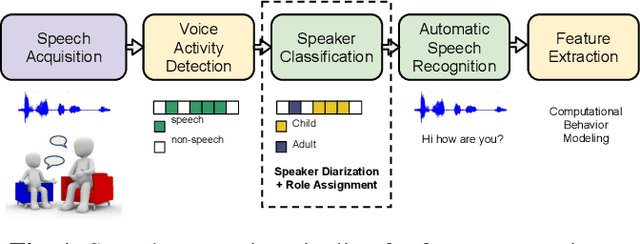
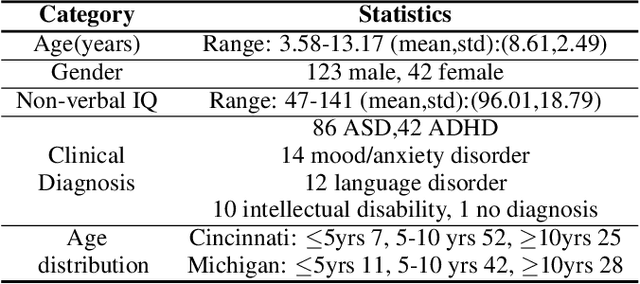

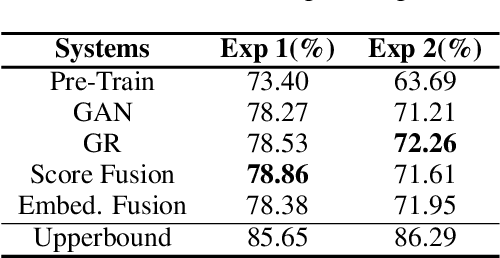
Diagnostic procedures for ASD (autism spectrum disorder) involve semi-naturalistic interactions between the child and a clinician. Computational methods to analyze these sessions require an end-to-end speech and language processing pipeline that go from raw audio to clinically-meaningful behavioral features. An important component of this pipeline is the ability to automatically detect who is speaking when i.e., perform child-adult speaker classification. This binary classification task is often confounded due to variability associated with the participants' speech and background conditions. Further, scarcity of training data often restricts direct application of conventional deep learning methods. In this work, we address two major sources of variability - age of the child and data source collection location - using domain adversarial learning which does not require labeled target domain data. We use two methods, generative adversarial training with inverted label loss and gradient reversal layer to learn speaker embeddings invariant to the above sources of variability, and analyze different conditions under which the proposed techniques improve over conventional learning methods. Using a large corpus of ADOS-2 (autism diagnostic observation schedule, 2nd edition) sessions, we demonstrate upto 13.45% and 6.44% relative improvements over conventional learning methods.