 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Generic LLMs Help Analyze Child-adult Interactions Involving Children with Autism in Clinical Observation?
Nov 16, 2024



Large Language Models (LLMs) have shown significant potential in understanding human communication and interaction. However, their performance in the domain of child-inclusive interactions, including in clinical settings, remains less explored. In this work, we evaluate generic LLMs' ability to analyze child-adult dyadic interactions in a clinically relevant context involving children with ASD. Specifically, we explore LLMs in performing four tasks: classifying child-adult utterances, predicting engaged activities, recognizing language skills and understanding traits that are clinically relevant. Our evaluation shows that generic LLMs are highly capable of analyzing long and complex conversations in clinical observation sessions, often surpassing the performance of non-expert human evaluators. The results show their potential to segment interactions of interest, assist in language skills evaluation, identify engaged activities, and offer clinical-relevant context for assessments.
Data Efficient Child-Adult Speaker Diarization with Simulated Conversations
Sep 13, 2024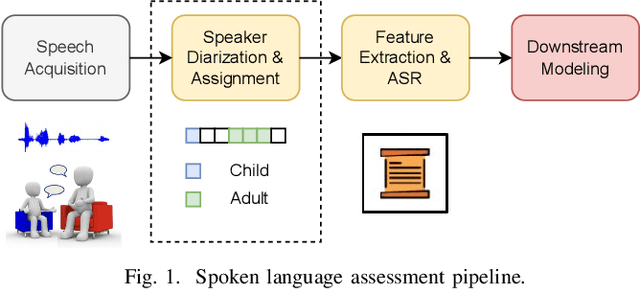
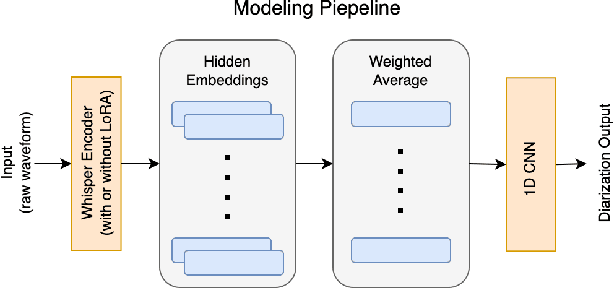

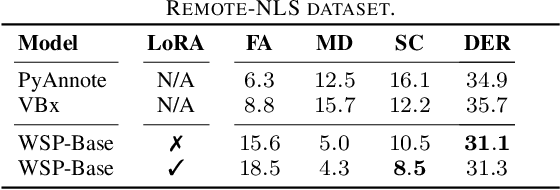
Automating child speech analysis is crucial for applications such as neurocognitive assessments. Speaker diarization, which identifies ``who spoke when'', is an essential component of the automated analysis. However, publicly available child-adult speaker diarization solutions are scarce due to privacy concerns and a lack of annotated datasets, while manually annotating data for each scenario is both time-consuming and costly. To overcome these challenges, we propose a data-efficient solution by creating simulated child-adult conversations using AudioSet. We then train a Whisper Encoder-based model, achieving strong zero-shot performance on child-adult speaker diarization using real datasets. The model performance improves substantially when fine-tuned with only 30 minutes of real train data, with LoRA further improving the transfer learning performance. The source code and the child-adult speaker diarization model trained on simulated conversations are publicly available.
Exploring Speech Foundation Models for Speaker Diarization in Child-Adult Dyadic Interactions
Jun 12, 2024Speech foundation models, trained on vast datasets, have opened unique opportunities in addressing challenging low-resource speech understanding, such as child speech. In this work, we explore the capabilities of speech foundation models on child-adult speaker diarization. We show that exemplary foundation models can achieve 39.5% and 62.3% relative reductions in Diarization Error Rate and Speaker Confusion Rate, respectively, compared to previous speaker diarization methods. In addition, we benchmark and evaluate the speaker diarization results of the speech foundation models with varying the input audio window size, speaker demographics, and training data ratio. Our results highlight promising pathways for understanding and adopting speech foundation models to facilitate child speech understanding.
Audio-visual child-adult speaker classification in dyadic interactions
Oct 09, 2023



Interactions involving children span a wide range of important domains from learning to clinical diagnostic and therapeutic contexts. Automated analyses of such interactions are motivated by the need to seek accurate insights and offer scale and robustness across diverse and wide-ranging conditions. Identifying the speech segments belonging to the child is a critical step in such modeling. Conventional child-adult speaker classification typically relies on audio modeling approaches, overlooking visual signals that convey speech articulation information, such as lip motion. Building on the foundation of an audio-only child-adult speaker classification pipeline, we propose incorporating visual cues through active speaker detection and visual processing models. Our framework involves video pre-processing, utterance-level child-adult speaker detection, and late fusion of modality-specific predictions. We demonstrate from extensive experiments that a visually aided classification pipeline enhances the accuracy and robustness of the classification. We show relative improvements of 2.38% and 3.97% in F1 macro score when one face and two faces are visible, respectively.
Understanding Spoken Language Development of Children with ASD Using Pre-trained Speech Embeddings
May 23, 2023Speech processing techniques are useful for analyzing speech and language development in children with Autism Spectrum Disorder (ASD), who are often varied and delayed in acquiring these skills. Early identification and intervention are crucial, but traditional assessment methodologies such as caregiver reports are not adequate for the requisite behavioral phenotyping. Natural Language Sample (NLS) analysis has gained attention as a promising complement. Researchers have developed benchmarks for spoken language capabilities in children with ASD, obtainable through the analysis of NLS. This paper proposes applications of speech processing technologies in support of automated assessment of children's spoken language development by classification between child and adult speech and between speech and nonverbal vocalization in NLS, with respective F1 macro scores of 82.6% and 67.8%, underscoring the potential for accurate and scalable tools for ASD research and clinical use.