 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Efficient Child-Adult Speaker Diarization with Simulated Conversations
Paper and Code
Sep 13, 2024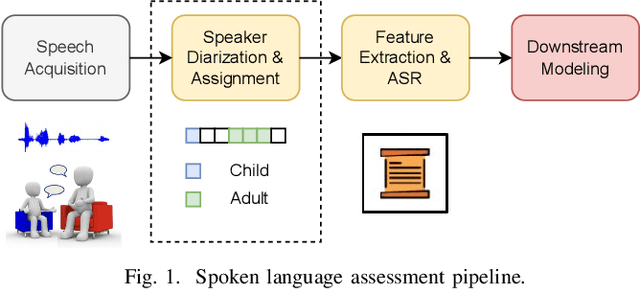
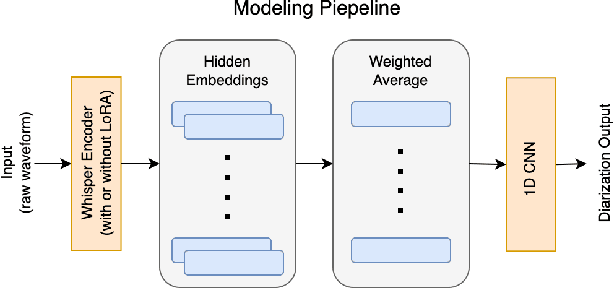

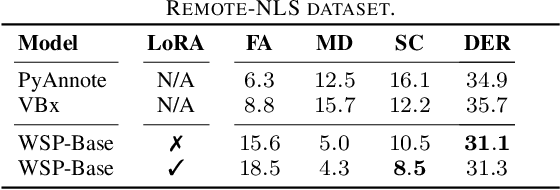
Automating child speech analysis is crucial for applications such as neurocognitive assessments. Speaker diarization, which identifies ``who spoke when'', is an essential component of the automated analysis. However, publicly available child-adult speaker diarization solutions are scarce due to privacy concerns and a lack of annotated datasets, while manually annotating data for each scenario is both time-consuming and costly. To overcome these challenges, we propose a data-efficient solution by creating simulated child-adult conversations using AudioSet. We then train a Whisper Encoder-based model, achieving strong zero-shot performance on child-adult speaker diarization using real datasets. The model performance improves substantially when fine-tuned with only 30 minutes of real train data, with LoRA further improving the transfer learning performance. The source code and the child-adult speaker diarization model trained on simulated conversations are publicly available.