 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining a Deep Learning-based Formant Tracker using Linear Prediction Methods
Paper and Code
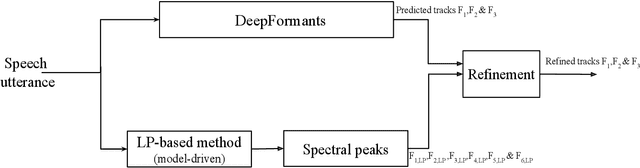
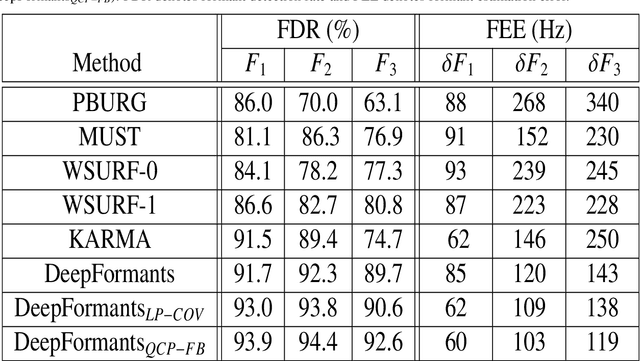
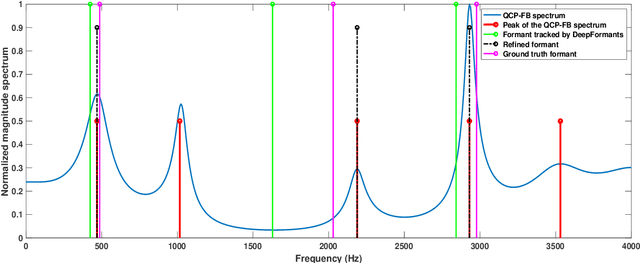
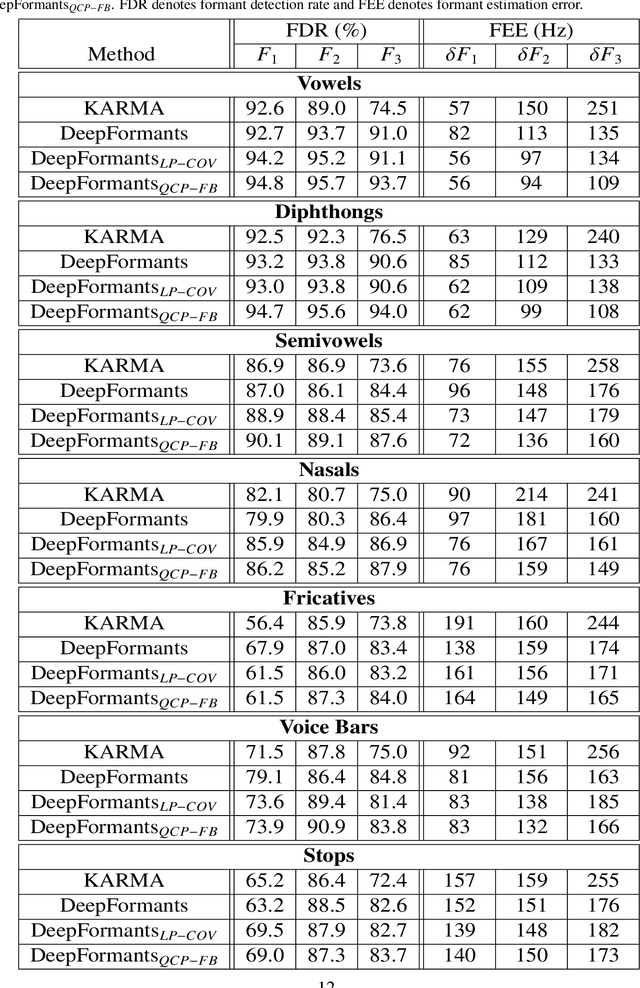
In this study, formant tracking is investigated by refining the formants tracked by an existing data-driven tracker, DeepFormants, using the formants estimated in a model-driven manner by linear prediction (LP)-based methods. As LP-based formant estimation methods, conventional covariance analysis (LP-COV) and the recently proposed quasi-closed phase forward-backward (QCP-FB) analysis are used. In the proposed refinement approach, the contours of the three lowest formants are first predicted by the data-driven DeepFormants tracker, and the predicted formants are replaced frame-wise with local spectral peaks shown by the model-driven LP-based methods. The refinement procedure can be plugged into the DeepFormants tracker with no need for any new data learning. Two refined DeepFormants trackers were compared with the original DeepFormants and with five known traditional trackers using the popular vocal tract resonance (VTR) corpus. The results indicated that the data-driven DeepFormants trackers outperformed the conventional trackers and that the best performance was obtained by refining the formants predicted by DeepFormants using QCP-FB analysis. In addition, by tracking formants using VTR speech that was corrupted by additive noise, the study showed that the refined DeepFormants trackers were more resilient to noise than the reference trackers. In general, these results suggest that LP-based model-driven approaches, which have traditionally been used in formant estimation, can be combined with a modern data-driven tracker easily with no further training to improve the tracker's performance.