 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Self-supervised Pre-trained Models for Classification of Voice Quality from Speech and Neck Surface Accelerometer Signals
Paper and Code
Aug 06, 2023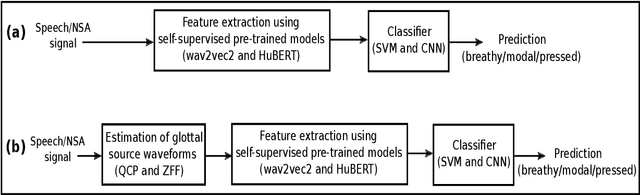

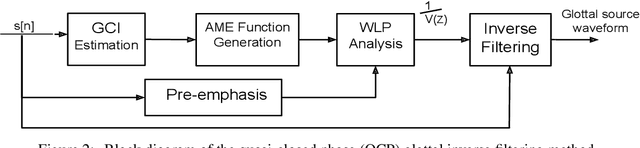
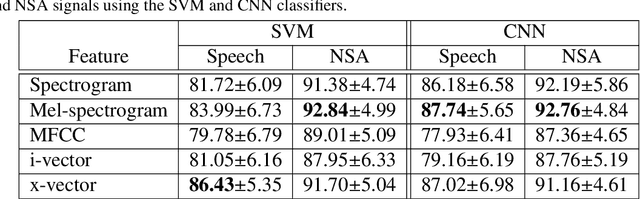
Prior studies in the automatic classification of voice quality have mainly studied the use of the acoustic speech signal as input. Recently, a few studies have been carried out by jointly using both speech and neck surface accelerometer (NSA) signals as inputs, and by extracting MFCCs and glottal source features. This study examines simultaneously-recorded speech and NSA signals in the classification of voice quality (breathy, modal, and pressed) using features derived from three self-supervised pre-trained models (wav2vec2-BASE, wav2vec2-LARGE, and HuBERT) and using a SVM as well as CNNs as classifiers. Furthermore, the effectiveness of the pre-trained models is compared in feature extraction between glottal source waveforms and raw signal waveforms for both speech and NSA inputs. Using two signal processing methods (quasi-closed phase (QCP) glottal inverse filtering and zero frequency filtering (ZFF)), glottal source waveforms are estimated from both speech and NSA signals. The study has three main goals: (1) to study whether features derived from pre-trained models improve classification accuracy compared to conventional features (spectrogram, mel-spectrogram, MFCCs, i-vector, and x-vector), (2) to investigate which of the two modalities (speech vs. NSA) is more effective in the classification task with pre-trained model-based features, and (3) to evaluate whether the deep learning-based CNN classifier can enhance the classification accuracy in comparison to the SVM classifier. The results revealed that the use of the NSA input showed better classification performance compared to the speech signal. Between the features, the pre-trained model-based features showed better classification accuracies, both for speech and NSA inputs compared to the conventional features. It was also found that the HuBERT features performed better than the wav2vec2-BASE and wav2vec2-LARGE features.