 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Self-Supervised Learning and Dimensionality Reduction Methods in Clustering-Based Active Learning for Speech Emotion Recognition
Paper and Code
Jun 21, 2022

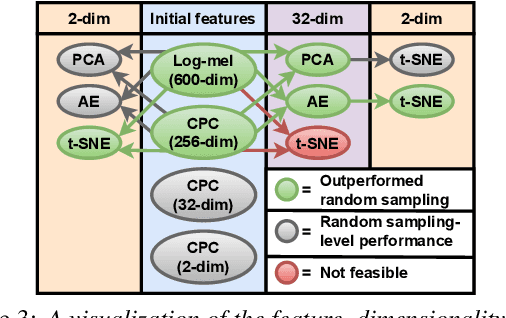
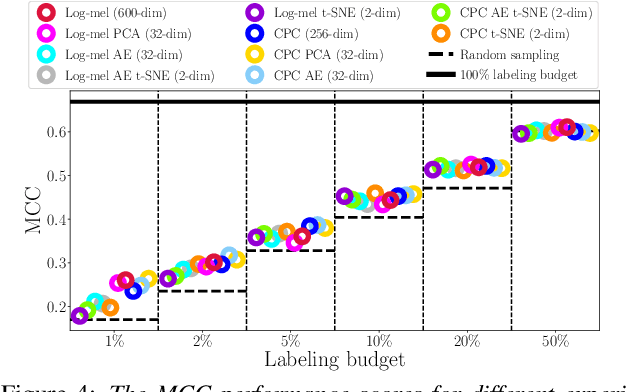
When domain experts are needed to perform data annotation for complex machine-learning tasks, reducing annotation effort is crucial in order to cut down time and expenses. For cases when there are no annotations available, one approach is to utilize the structure of the feature space for clustering-based active learning (AL) methods. However, these methods are heavily dependent on how the samples are organized in the feature space and what distance metric is used. Unsupervised methods such as contrastive predictive coding (CPC) can potentially be used to learn organized feature spaces, but these methods typically create high-dimensional features which might be challenging for estimating data density. In this paper, we combine CPC and multiple dimensionality reduction methods in search of functioning practices for clustering-based AL. Our experiments for simulating speech emotion recognition system deployment show that both the local and global topology of the feature space can be successfully used for AL, and that CPC can be used to improve clustering-based AL performance over traditional signal features. Additionally, we observe that compressing data dimensionality does not harm AL performance substantially, and that 2-D feature representations achieved similar AL performance as higher-dimensional representations when the number of annotations is not very low.