 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Repetition Enhances Token Embeddings and Improves Sequence Labeling with Decoder-only Language Models
Jan 24, 2026Modern language models (LMs) are trained in an autoregressive manner, conditioned only on the prefix. In contrast, sequence labeling (SL) tasks assign labels to each individual input token, naturally benefiting from bidirectional context. This discrepancy has historically led SL to rely on inherently bidirectional encoder-only models. However, the rapid development of decoder-only models has raised the question of whether they can be adapted to SL. While causal mask removal has emerged as a viable technique for adapting decoder-only models to leverage the full context for SL, it requires considerable changes to the base model functionality. In this work, we explore sequence repetition (SR) as a less invasive alternative for enabling bidirectionality in decoder-only models. Through fine-tuning experiments, we show that SR inherently makes decoders bidirectional, improving the quality of token-level embeddings and surpassing encoders and unmasked decoders. Contrary to earlier claims, we find that increasing the number of repetitions does not degrade SL performance. Finally, we demonstrate that embeddings from intermediate layers are highly effective for SR, comparable to those from final layers, while being significantly more efficient to compute. Our findings underscore that SR alleviates the structural limitations of decoders, enabling more efficient and adaptable LMs and broadening their applicability to other token-level tasks.
PragWorld: A Benchmark Evaluating LLMs' Local World Model under Minimal Linguistic Alterations and Conversational Dynamics
Nov 17, 2025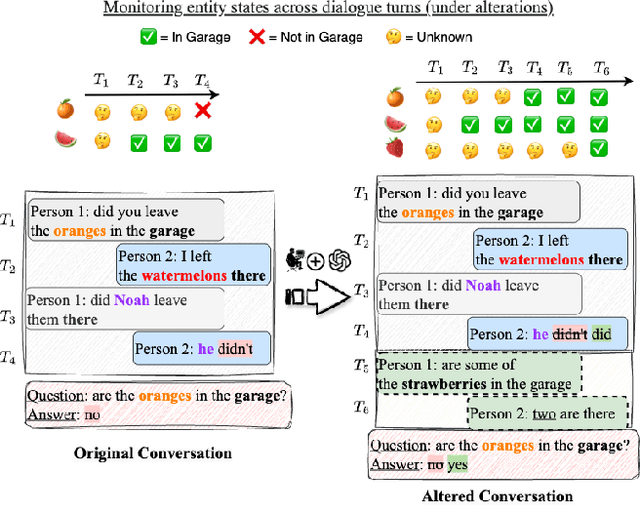
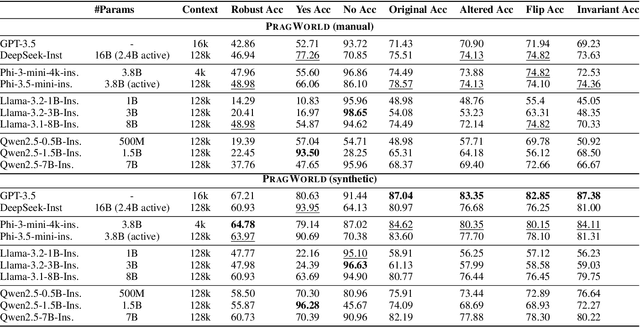
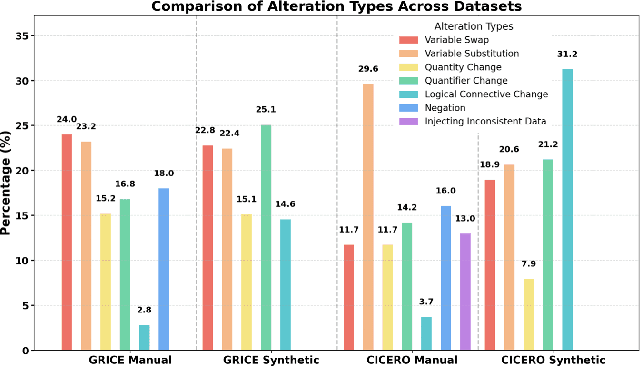
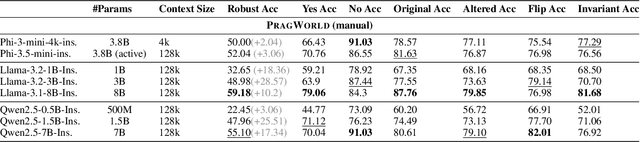
Real-world conversations are rich with pragmatic elements, such as entity mentions, references, and implicatures. Understanding such nuances is a requirement for successful natural communication, and often requires building a local world model which encodes such elements and captures the dynamics of their evolving states. However, it is not well-understood whether language models (LMs) construct or maintain a robust implicit representation of conversations. In this work, we evaluate the ability of LMs to encode and update their internal world model in dyadic conversations and test their malleability under linguistic alterations. To facilitate this, we apply seven minimal linguistic alterations to conversations sourced from popular datasets and construct two benchmarks comprising yes-no questions. We evaluate a wide range of open and closed source LMs and observe that they struggle to maintain robust accuracy. Our analysis unveils that LMs struggle to memorize crucial details, such as tracking entities under linguistic alterations to conversations. We then propose a dual-perspective interpretability framework which identifies transformer layers that are useful or harmful and highlights linguistic alterations most influenced by harmful layers, typically due to encoding spurious signals or relying on shortcuts. Inspired by these insights, we propose two layer-regularization based fine-tuning strategies that suppress the effect of the harmful layers.
ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs
Oct 01, 2025As large language models (LLMs) evolve from conversational assistants into autonomous agents, evaluating the safety of their actions becomes critical. Prior safety benchmarks have primarily focused on preventing generation of harmful content, such as toxic text. However, they overlook the challenge of agents taking harmful actions when the most effective path to an operational goal conflicts with human safety. To address this gap, we introduce ManagerBench, a benchmark that evaluates LLM decision-making in realistic, human-validated managerial scenarios. Each scenario forces a choice between a pragmatic but harmful action that achieves an operational goal, and a safe action that leads to worse operational performance. A parallel control set, where potential harm is directed only at inanimate objects, measures a model's pragmatism and identifies its tendency to be overly safe. Our findings indicate that the frontier LLMs perform poorly when navigating this safety-pragmatism trade-off. Many consistently choose harmful options to advance their operational goals, while others avoid harm only to become overly safe and ineffective. Critically, we find this misalignment does not stem from an inability to perceive harm, as models' harm assessments align with human judgments, but from flawed prioritization. ManagerBench is a challenging benchmark for a core component of agentic behavior: making safe choices when operational goals and alignment values incentivize conflicting actions. Benchmark & code available at https://github.com/technion-cs-nlp/ManagerBench.
Context Parametrization with Compositional Adapters
Sep 26, 2025Large language models (LLMs) often seamlessly adapt to new tasks through in-context learning (ICL) or supervised fine-tuning (SFT). However, both of these approaches face key limitations: ICL is inefficient when handling many demonstrations, and SFT incurs training overhead while sacrificing flexibility. Mapping instructions or demonstrations from context directly into adapter parameters offers an appealing alternative. While prior work explored generating adapters based on a single input context, it has overlooked the need to integrate multiple chunks of information. To address this gap, we introduce CompAs, a meta-learning framework that translates context into adapter parameters with a compositional structure. Adapters generated this way can be merged algebraically, enabling instructions, demonstrations, or retrieved passages to be seamlessly combined without reprocessing long prompts. Critically, this approach yields three benefits: lower inference cost, robustness to long-context instability, and establishes a principled solution when input exceeds the model's context window. Furthermore, CompAs encodes information into adapter parameters in a reversible manner, enabling recovery of input context through a decoder, facilitating safety and security. Empirical results on diverse multiple-choice and extractive question answering tasks show that CompAs outperforms ICL and prior generator-based methods, especially when scaling to more inputs. Our work establishes composable adapter generation as a practical and efficient alternative for scaling LLM deployment.
Characterizing Linguistic Shifts in Croatian News via Diachronic Word Embeddings
Jun 16, 2025Measuring how semantics of words change over time improves our understanding of how cultures and perspectives change. Diachronic word embeddings help us quantify this shift, although previous studies leveraged substantial temporally annotated corpora. In this work, we use a corpus of 9.5 million Croatian news articles spanning the past 25 years and quantify semantic change using skip-gram word embeddings trained on five-year periods. Our analysis finds that word embeddings capture linguistic shifts of terms pertaining to major topics in this timespan (COVID-19, Croatia joining the European Union, technological advancements). We also find evidence that embeddings from post-2020 encode increased positivity in sentiment analysis tasks, contrasting studies reporting a decline in mental health over the same period.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
Measuring Faithfulness of Chains of Thought by Unlearning Reasoning Steps
Feb 20, 2025When prompted to think step-by-step, language models (LMs) produce a chain of thought (CoT), a sequence of reasoning steps that the model supposedly used to produce its prediction. However, despite much work on CoT prompting, it is unclear if CoT reasoning is faithful to the models' parameteric beliefs. We introduce a framework for measuring parametric faithfulness of generated reasoning, and propose Faithfulness by Unlearning Reasoning steps (FUR), an instance of this framework. FUR erases information contained in reasoning steps from model parameters. We perform experiments unlearning CoTs of four LMs prompted on four multi-choice question answering (MCQA) datasets. Our experiments show that FUR is frequently able to change the underlying models' prediction by unlearning key steps, indicating when a CoT is parametrically faithful. Further analysis shows that CoTs generated by models post-unlearning support different answers, hinting at a deeper effect of unlearning. Importantly, CoT steps identified as important by FUR do not align well with human notions of plausbility, emphasizing the need for specialized alignment
REVS: Unlearning Sensitive Information in Language Models via Rank Editing in the Vocabulary Space
Jun 13, 2024



Large language models (LLMs) risk inadvertently memorizing and divulging sensitive or personally identifiable information (PII) seen in training data, causing privacy concerns. Current approaches to address this issue involve costly dataset scrubbing, or model filtering through unlearning and model editing, which can be bypassed through extraction attacks. We propose REVS, a novel model editing method for unlearning sensitive information from LLMs. REVS identifies and modifies a small subset of neurons relevant for each piece of sensitive information. By projecting these neurons to the vocabulary space (unembedding), we pinpoint the components driving its generation. We then compute a model edit based on the pseudo-inverse of the unembedding matrix, and apply it to de-promote generation of the targeted sensitive data. To adequately evaluate our method on truly sensitive information, we curate two datasets: an email dataset inherently memorized by GPT-J, and a synthetic social security number dataset that we tune the model to memorize. Compared to other state-of-the-art model editing methods, REVS demonstrates superior performance in both eliminating sensitive information and robustness to extraction attacks, while retaining integrity of the underlying model. The code and a demo notebook are available at https://technion-cs-nlp.github.io/REVS.
Code Prompting Elicits Conditional Reasoning Abilities in Text+Code LLMs
Jan 18, 2024



Reasoning is a fundamental component for achieving language understanding. Among the multiple types of reasoning, conditional reasoning, the ability to draw different conclusions depending on some condition, has been understudied in large language models (LLMs). Recent prompting methods, such as chain of thought, have significantly improved LLMs on reasoning tasks. Nevertheless, there is still little understanding of what triggers reasoning abilities in LLMs. We hypothesize that code prompts can trigger conditional reasoning in LLMs trained on text and code. We propose a chain of prompts that transforms a natural language problem into code and prompts the LLM with the generated code. Our experiments find that code prompts exhibit a performance boost between 2.6 and 7.7 points on GPT 3.5 across multiple datasets requiring conditional reasoning. We then conduct experiments to discover how code prompts elicit conditional reasoning abilities and through which features. We observe that prompts need to contain natural language text accompanied by high-quality code that closely represents the semantics of the instance text. Furthermore, we show that code prompts are more efficient, requiring fewer demonstrations, and that they trigger superior state tracking of variables or key entities.
Out-of-Distribution Detection by Leveraging Between-Layer Transformation Smoothness
Oct 04, 2023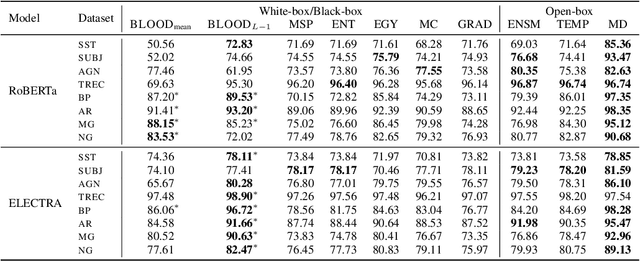
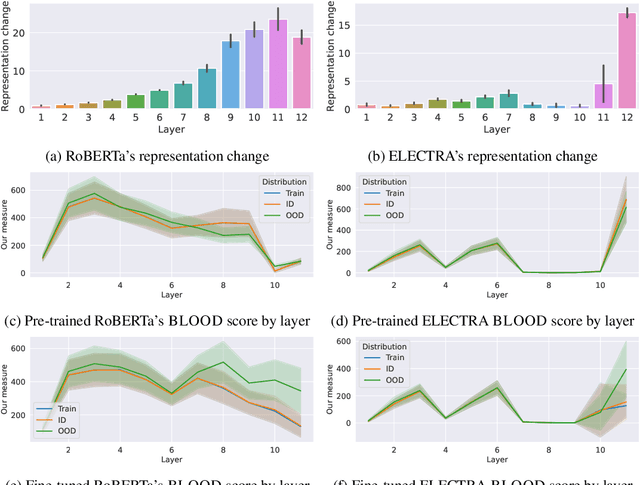
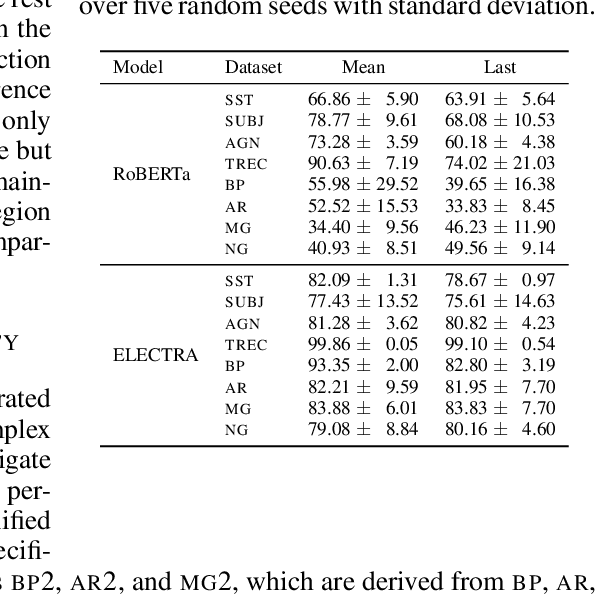
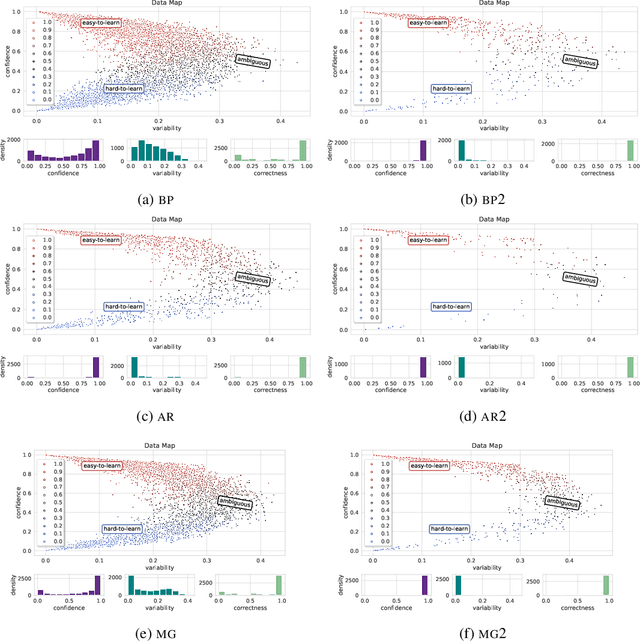
Effective OOD detection is crucial for reliable machine learning models, yet most current methods are limited in practical use due to requirements like access to training data or intervention in training. We present a novel method for detecting OOD data in deep neural networks based on transformation smoothness between intermediate layers of a network (BLOOD), which is applicable to pre-trained models without access to training data. BLOOD utilizes the tendency of between-layer representation transformations of in-distribution (ID) data to be smoother than the corresponding transformations of OOD data, a property that we also demonstrate empirically for Transformer networks. We evaluate BLOOD on several text classification tasks with Transformer networks and demonstrate that it outperforms methods with comparable resource requirements. Our analysis also suggests that when learning simpler tasks, OOD data transformations maintain their original sharpness, whereas sharpness increases with more complex tasks.