 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Repetition Enhances Token Embeddings and Improves Sequence Labeling with Decoder-only Language Models
Jan 24, 2026Modern language models (LMs) are trained in an autoregressive manner, conditioned only on the prefix. In contrast, sequence labeling (SL) tasks assign labels to each individual input token, naturally benefiting from bidirectional context. This discrepancy has historically led SL to rely on inherently bidirectional encoder-only models. However, the rapid development of decoder-only models has raised the question of whether they can be adapted to SL. While causal mask removal has emerged as a viable technique for adapting decoder-only models to leverage the full context for SL, it requires considerable changes to the base model functionality. In this work, we explore sequence repetition (SR) as a less invasive alternative for enabling bidirectionality in decoder-only models. Through fine-tuning experiments, we show that SR inherently makes decoders bidirectional, improving the quality of token-level embeddings and surpassing encoders and unmasked decoders. Contrary to earlier claims, we find that increasing the number of repetitions does not degrade SL performance. Finally, we demonstrate that embeddings from intermediate layers are highly effective for SR, comparable to those from final layers, while being significantly more efficient to compute. Our findings underscore that SR alleviates the structural limitations of decoders, enabling more efficient and adaptable LMs and broadening their applicability to other token-level tasks.
Characterizing Linguistic Shifts in Croatian News via Diachronic Word Embeddings
Jun 16, 2025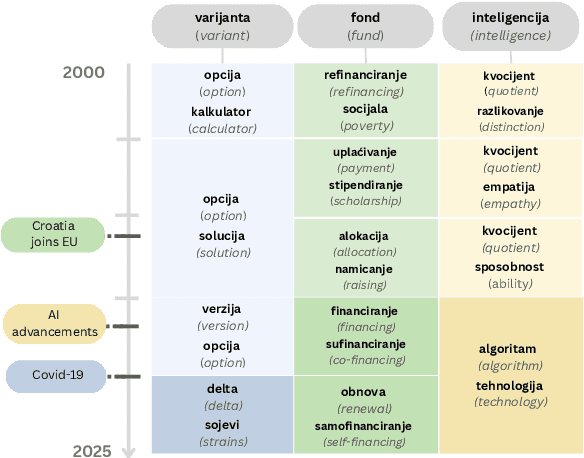
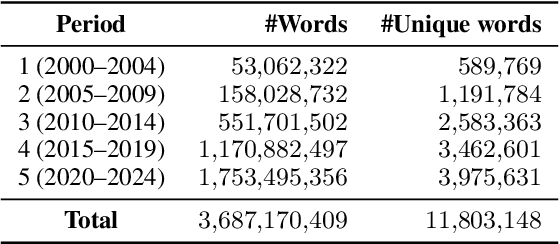
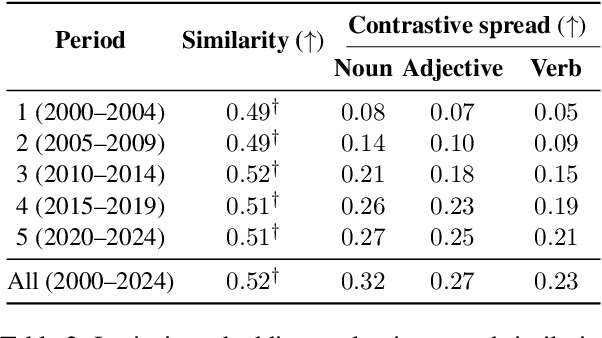
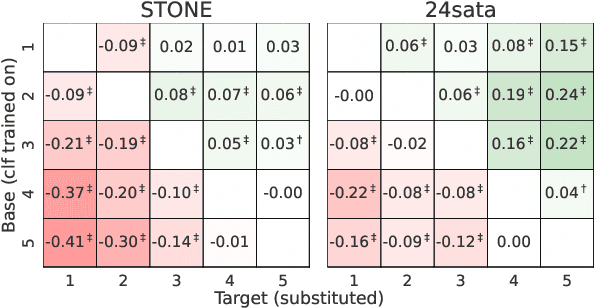
Measuring how semantics of words change over time improves our understanding of how cultures and perspectives change. Diachronic word embeddings help us quantify this shift, although previous studies leveraged substantial temporally annotated corpora. In this work, we use a corpus of 9.5 million Croatian news articles spanning the past 25 years and quantify semantic change using skip-gram word embeddings trained on five-year periods. Our analysis finds that word embeddings capture linguistic shifts of terms pertaining to major topics in this timespan (COVID-19, Croatia joining the European Union, technological advancements). We also find evidence that embeddings from post-2020 encode increased positivity in sentiment analysis tasks, contrasting studies reporting a decline in mental health over the same period.
TakeLab Retriever: AI-Driven Search Engine for Articles from Croatian News Outlets
Nov 29, 2024



TakeLab Retriever is an AI-driven search engine designed to discover, collect, and semantically analyze news articles from Croatian news outlets. It offers a unique perspective on the history and current landscape of Croatian online news media, making it an essential tool for researchers seeking to uncover trends, patterns, and correlations that general-purpose search engines cannot provide. TakeLab retriever utilizes cutting-edge natural language processing (NLP) methods, enabling users to sift through articles using named entities, phrases, and topics through the web application. This technical report is divided into two parts: the first explains how TakeLab Retriever is utilized, while the second provides a detailed account of its design. In the second part, we also address the software engineering challenges involved and propose solutions for developing a microservice-based semantic search engine capable of handling over ten million news articles published over the past two decades.
Are ELECTRA's Sentence Embeddings Beyond Repair? The Case of Semantic Textual Similarity
Feb 20, 2024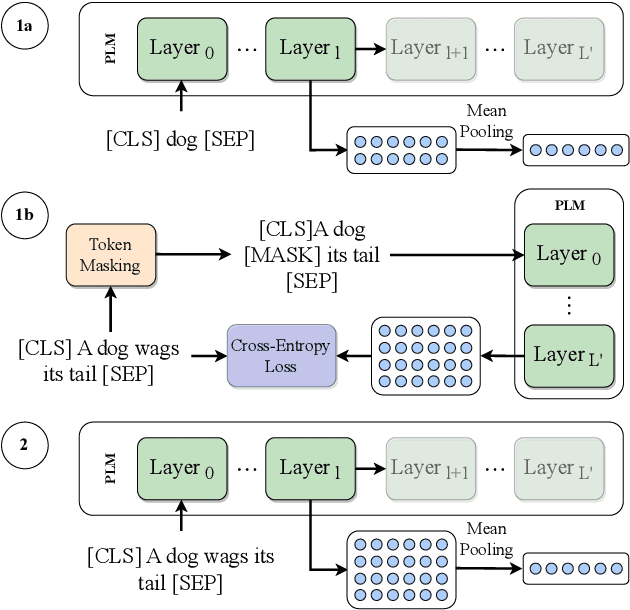

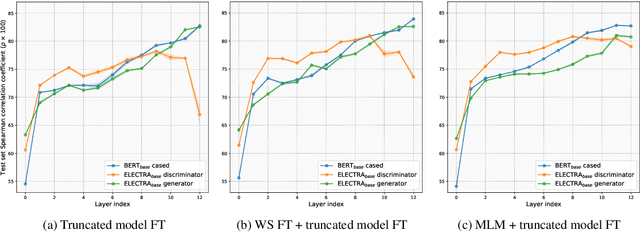

While BERT produces high-quality sentence embeddings, its pre-training computational cost is a significant drawback. In contrast, ELECTRA delivers a cost-effective pre-training objective and downstream task performance improvements, but not as performant sentence embeddings. The community tacitly stopped utilizing ELECTRA's sentence embeddings for semantic textual similarity (STS). We notice a significant drop in performance when using the ELECTRA discriminator's last layer in comparison to earlier layers. We explore this drop and devise a way to repair ELECTRA's embeddings, proposing a novel truncated model fine-tuning (TMFT) method. TMFT improves the Spearman correlation coefficient by over 8 points while increasing parameter efficiency on the STS benchmark dataset. We extend our analysis to various model sizes and languages. Further, we discover the surprising efficacy of ELECTRA's generator model, which performs on par with BERT, using significantly fewer parameters and a substantially smaller embedding size. Finally, we observe further boosts by combining TMFT with a word similarity task or domain adaptive pre-training.
Do Not (Always) Look Right: Investigating the Capabilities of Decoder-Based Large Language Models for Sequence Labeling
Jan 25, 2024
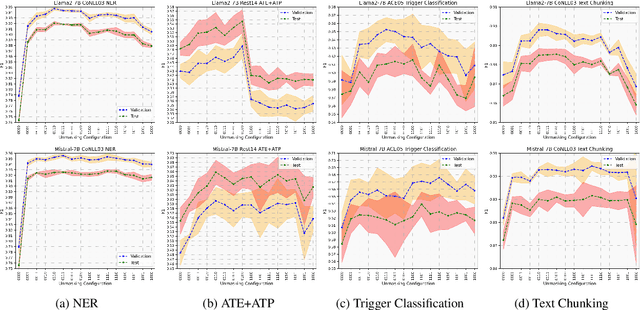
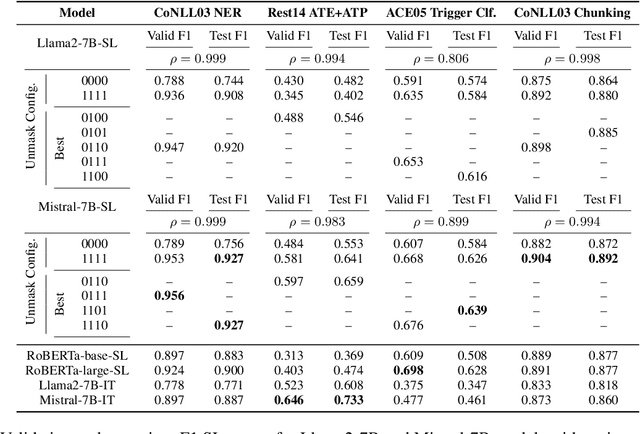
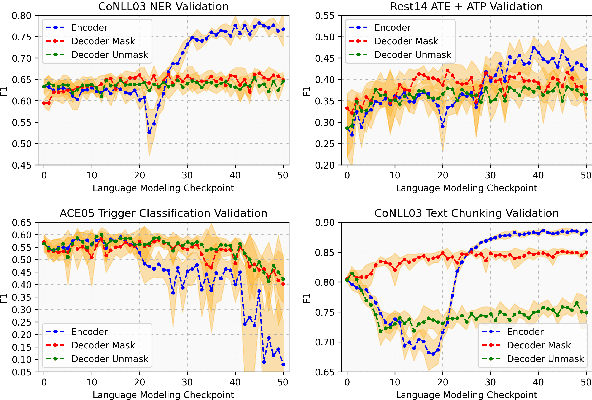
Pre-trained language models based on masked language modeling (MLM) objective excel in natural language understanding (NLU) tasks. While fine-tuned MLM-based encoders consistently outperform causal language modeling decoders of comparable size, a recent trend of scaling decoder models to multiple billion parameters resulted in large language models (LLMs), making them competitive with MLM-based encoders. Although scale amplifies their prowess in NLU tasks, LLMs fall short of SOTA results in information extraction (IE) tasks, many framed as sequence labeling (SL). However, whether this is an intrinsic limitation of LLMs or whether their SL performance can be improved remains unclear. To address this, we explore strategies to enhance the SL performance of "open" LLMs (Llama2 and Mistral) on IE tasks. We investigate bidirectional information flow within groups of decoder blocks, applying layer-wise removal or enforcement of the causal mask (CM) during LLM fine-tuning. This approach yields performance gains competitive with SOTA SL models, matching or outperforming the results of CM removal from all blocks. Our findings hold for diverse SL tasks, proving that "open" LLMs with layer-dependent CM removal outperform strong MLM-based encoders and instruction-tuned LLMs. However, we observe no effect from CM removal on a small scale when maintaining an equivalent model size, pre-training steps, and pre-training and fine-tuning data.
Leveraging Open Information Extraction for Improving Few-Shot Trigger Detection Domain Transfer
May 23, 2023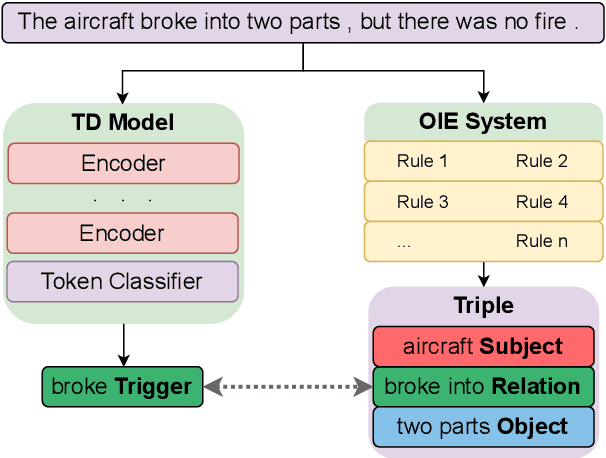
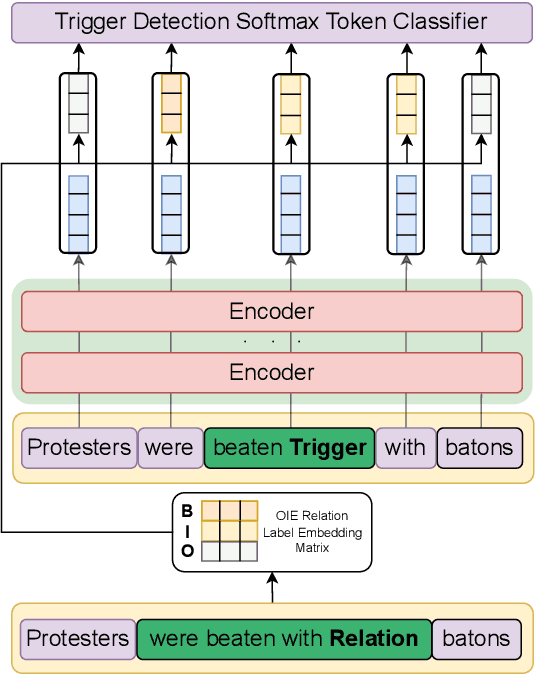
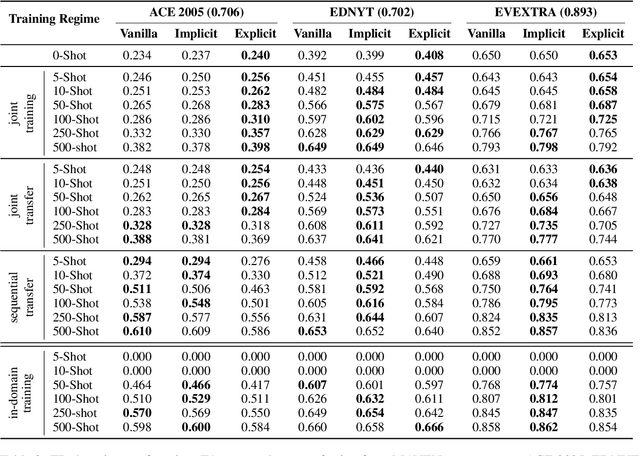
Event detection is a crucial information extraction task in many domains, such as Wikipedia or news. The task typically relies on trigger detection (TD) -- identifying token spans in the text that evoke specific events. While the notion of triggers should ideally be universal across domains, domain transfer for TD from high- to low-resource domains results in significant performance drops. We address the problem of negative transfer for TD by coupling triggers between domains using subject-object relations obtained from a rule-based open information extraction (OIE) system. We demonstrate that relations injected through multi-task training can act as mediators between triggers in different domains, enhancing zero- and few-shot TD domain transfer and reducing negative transfer, in particular when transferring from a high-resource source Wikipedia domain to a low-resource target news domain. Additionally, we combine the extracted relations with masked language modeling on the target domain and obtain further TD performance gains. Finally, we demonstrate that the results are robust to the choice of the OIE system.