 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre ELECTRA's Sentence Embeddings Beyond Repair? The Case of Semantic Textual Similarity
Feb 20, 2024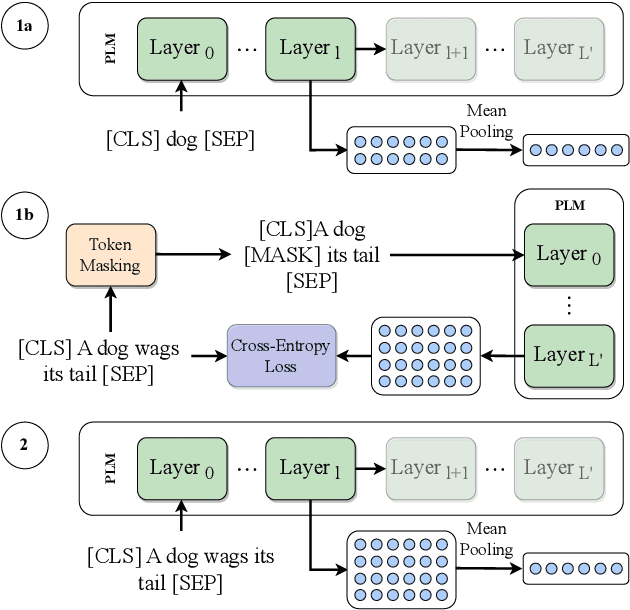

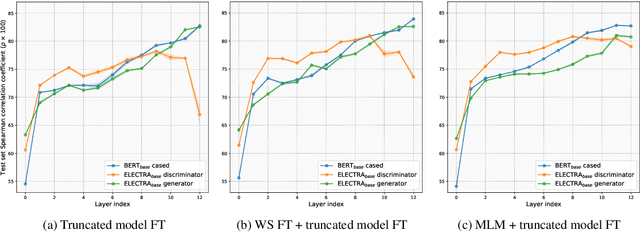

While BERT produces high-quality sentence embeddings, its pre-training computational cost is a significant drawback. In contrast, ELECTRA delivers a cost-effective pre-training objective and downstream task performance improvements, but not as performant sentence embeddings. The community tacitly stopped utilizing ELECTRA's sentence embeddings for semantic textual similarity (STS). We notice a significant drop in performance when using the ELECTRA discriminator's last layer in comparison to earlier layers. We explore this drop and devise a way to repair ELECTRA's embeddings, proposing a novel truncated model fine-tuning (TMFT) method. TMFT improves the Spearman correlation coefficient by over 8 points while increasing parameter efficiency on the STS benchmark dataset. We extend our analysis to various model sizes and languages. Further, we discover the surprising efficacy of ELECTRA's generator model, which performs on par with BERT, using significantly fewer parameters and a substantially smaller embedding size. Finally, we observe further boosts by combining TMFT with a word similarity task or domain adaptive pre-training.
Boosting the Performance of Transformer Architectures for Semantic Textual Similarity
Jun 01, 2023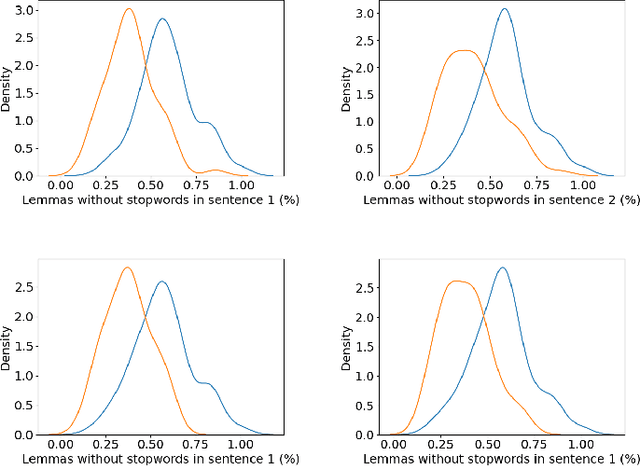
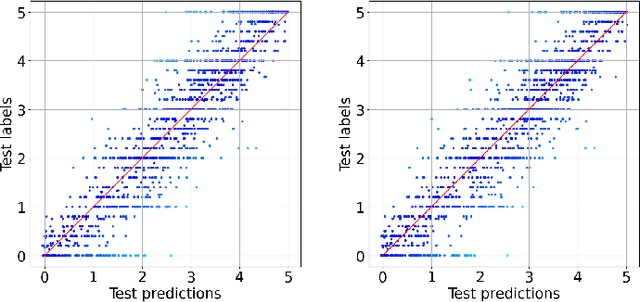
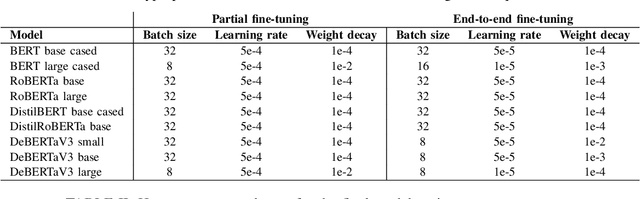
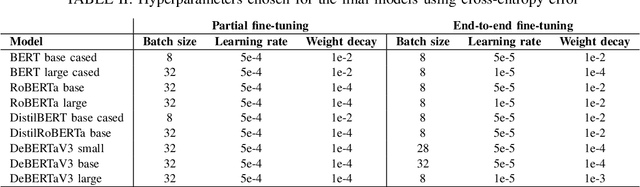
Semantic textual similarity is the task of estimating the similarity between the meaning of two texts. In this paper, we fine-tune transformer architectures for semantic textual similarity on the Semantic Textual Similarity Benchmark by tuning the model partially and then end-to-end. We experiment with BERT, RoBERTa, and DeBERTaV3 cross-encoders by approaching the problem as a binary classification task or a regression task. We combine the outputs of the transformer models and use handmade features as inputs for boosting algorithms. Due to worse test set results coupled with improvements on the validation set, we experiment with different dataset splits to further investigate this occurrence. We also provide an error analysis, focused on the edges of the prediction range.