 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Repetition Enhances Token Embeddings and Improves Sequence Labeling with Decoder-only Language Models
Jan 24, 2026Modern language models (LMs) are trained in an autoregressive manner, conditioned only on the prefix. In contrast, sequence labeling (SL) tasks assign labels to each individual input token, naturally benefiting from bidirectional context. This discrepancy has historically led SL to rely on inherently bidirectional encoder-only models. However, the rapid development of decoder-only models has raised the question of whether they can be adapted to SL. While causal mask removal has emerged as a viable technique for adapting decoder-only models to leverage the full context for SL, it requires considerable changes to the base model functionality. In this work, we explore sequence repetition (SR) as a less invasive alternative for enabling bidirectionality in decoder-only models. Through fine-tuning experiments, we show that SR inherently makes decoders bidirectional, improving the quality of token-level embeddings and surpassing encoders and unmasked decoders. Contrary to earlier claims, we find that increasing the number of repetitions does not degrade SL performance. Finally, we demonstrate that embeddings from intermediate layers are highly effective for SR, comparable to those from final layers, while being significantly more efficient to compute. Our findings underscore that SR alleviates the structural limitations of decoders, enabling more efficient and adaptable LMs and broadening their applicability to other token-level tasks.
Context Parametrization with Compositional Adapters
Sep 26, 2025



Large language models (LLMs) often seamlessly adapt to new tasks through in-context learning (ICL) or supervised fine-tuning (SFT). However, both of these approaches face key limitations: ICL is inefficient when handling many demonstrations, and SFT incurs training overhead while sacrificing flexibility. Mapping instructions or demonstrations from context directly into adapter parameters offers an appealing alternative. While prior work explored generating adapters based on a single input context, it has overlooked the need to integrate multiple chunks of information. To address this gap, we introduce CompAs, a meta-learning framework that translates context into adapter parameters with a compositional structure. Adapters generated this way can be merged algebraically, enabling instructions, demonstrations, or retrieved passages to be seamlessly combined without reprocessing long prompts. Critically, this approach yields three benefits: lower inference cost, robustness to long-context instability, and establishes a principled solution when input exceeds the model's context window. Furthermore, CompAs encodes information into adapter parameters in a reversible manner, enabling recovery of input context through a decoder, facilitating safety and security. Empirical results on diverse multiple-choice and extractive question answering tasks show that CompAs outperforms ICL and prior generator-based methods, especially when scaling to more inputs. Our work establishes composable adapter generation as a practical and efficient alternative for scaling LLM deployment.
TakeLab Retriever: AI-Driven Search Engine for Articles from Croatian News Outlets
Nov 29, 2024



TakeLab Retriever is an AI-driven search engine designed to discover, collect, and semantically analyze news articles from Croatian news outlets. It offers a unique perspective on the history and current landscape of Croatian online news media, making it an essential tool for researchers seeking to uncover trends, patterns, and correlations that general-purpose search engines cannot provide. TakeLab retriever utilizes cutting-edge natural language processing (NLP) methods, enabling users to sift through articles using named entities, phrases, and topics through the web application. This technical report is divided into two parts: the first explains how TakeLab Retriever is utilized, while the second provides a detailed account of its design. In the second part, we also address the software engineering challenges involved and propose solutions for developing a microservice-based semantic search engine capable of handling over ten million news articles published over the past two decades.
Disentangling Latent Shifts of In-Context Learning Through Self-Training
Oct 02, 2024



In-context learning (ICL) has become essential in natural language processing, particularly with autoregressive large language models capable of learning from demonstrations provided within the prompt. However, ICL faces challenges with stability and long contexts, especially as the number of demonstrations grows, leading to poor generalization and inefficient inference. To address these issues, we introduce STICL (Self-Training ICL), an approach that disentangles the latent shifts of demonstrations from the latent shift of the query through self-training. STICL employs a teacher model to generate pseudo-labels and trains a student model using these labels, encoded in an adapter module. The student model exhibits weak-to-strong generalization, progressively refining its predictions over time. Our empirical results show that STICL improves generalization and stability, consistently outperforming traditional ICL methods and other disentangling strategies across both in-domain and out-of-domain data.
Claim Check-Worthiness Detection: How Well do LLMs Grasp Annotation Guidelines?
Apr 18, 2024
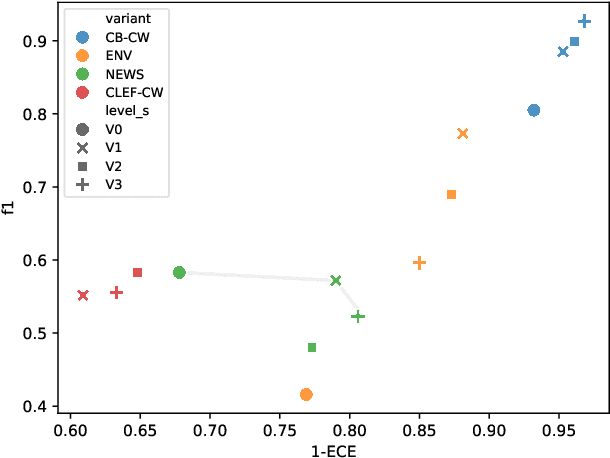

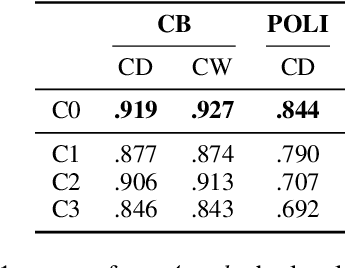
The increasing threat of disinformation calls for automating parts of the fact-checking pipeline. Identifying text segments requiring fact-checking is known as claim detection (CD) and claim check-worthiness detection (CW), the latter incorporating complex domain-specific criteria of worthiness and often framed as a ranking task. Zero- and few-shot LLM prompting is an attractive option for both tasks, as it bypasses the need for labeled datasets and allows verbalized claim and worthiness criteria to be directly used for prompting. We evaluate the LLMs' predictive and calibration accuracy on five CD/CW datasets from diverse domains, each utilizing a different worthiness criterion. We investigate two key aspects: (1) how best to distill factuality and worthiness criteria into a prompt and (2) what amount of context to provide for each claim. To this end, we experiment with varying the level of prompt verbosity and the amount of contextual information provided to the model. Our results show that optimal prompt verbosity is domain-dependent, adding context does not improve performance, and confidence scores can be directly used to produce reliable check-worthiness rankings.
From Robustness to Improved Generalization and Calibration in Pre-trained Language Models
Mar 31, 2024



Enhancing generalization and uncertainty quantification in pre-trained language models (PLMs) is crucial for their effectiveness and reliability. Building on machine learning research that established the importance of robustness for improving generalization, we investigate the role of representation smoothness, achieved via Jacobian and Hessian regularization, in enhancing PLM performance. Although such regularization methods have proven effective in computer vision, their application in natural language processing (NLP), where PLM inputs are derived from a discrete domain, poses unique challenges. We introduce a novel two-phase regularization approach, JacHess, which minimizes the norms of the Jacobian and Hessian matrices within PLM intermediate representations relative to their inputs. Our evaluation using the GLUE benchmark demonstrates that JacHess significantly improves in-domain generalization and calibration in PLMs, outperforming unregularized fine-tuning and other similar regularization methods.
LLMs for Targeted Sentiment in News Headlines: Exploring Different Levels of Prompt Prescriptiveness
Mar 01, 2024News headlines often evoke sentiment by intentionally portraying entities in particular ways, making targeted sentiment analysis (TSA) of headlines a worthwhile but difficult task. Fine-tuned encoder models show satisfactory TSA performance, but their background knowledge is limited, and they require a labeled dataset. LLMs offer a potentially universal solution for TSA due to their broad linguistic and world knowledge along with in-context learning abilities, yet their performance is heavily influenced by prompt design. Drawing parallels with annotation paradigms for subjective tasks, we explore the influence of prompt design on the performance of LLMs for TSA of news headlines. We evaluate the predictive accuracy of state-of-the-art LLMs using prompts with different levels of prescriptiveness, ranging from plain zero-shot to elaborate few-shot prompts matching annotation guidelines. Recognizing the subjective nature of TSA, we evaluate the ability of LLMs to quantify predictive uncertainty via calibration error and correlation to human inter-annotator agreement. We find that, except for few-shot prompting, calibration and F1-score improve with increased prescriptiveness, but the optimal level depends on the model.
Are ELECTRA's Sentence Embeddings Beyond Repair? The Case of Semantic Textual Similarity
Feb 20, 2024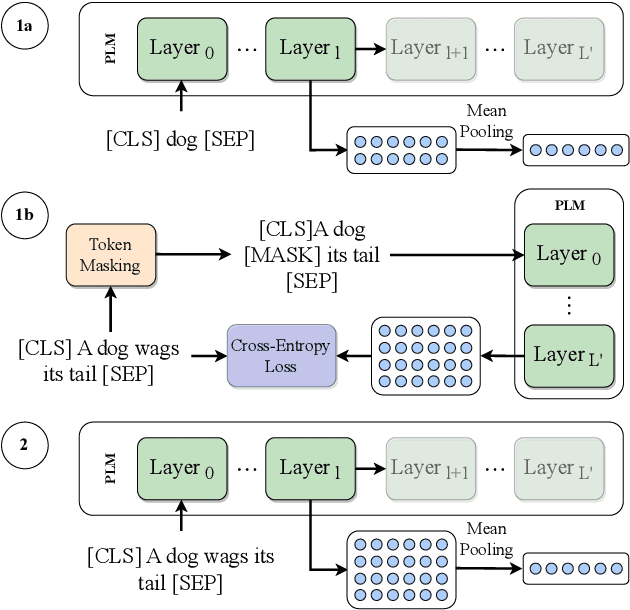

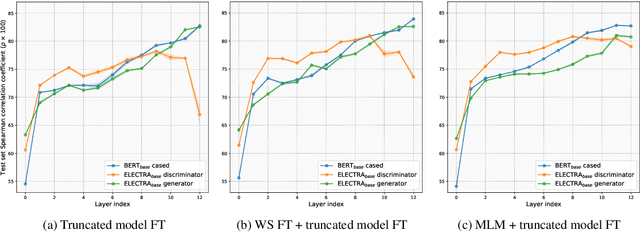

While BERT produces high-quality sentence embeddings, its pre-training computational cost is a significant drawback. In contrast, ELECTRA delivers a cost-effective pre-training objective and downstream task performance improvements, but not as performant sentence embeddings. The community tacitly stopped utilizing ELECTRA's sentence embeddings for semantic textual similarity (STS). We notice a significant drop in performance when using the ELECTRA discriminator's last layer in comparison to earlier layers. We explore this drop and devise a way to repair ELECTRA's embeddings, proposing a novel truncated model fine-tuning (TMFT) method. TMFT improves the Spearman correlation coefficient by over 8 points while increasing parameter efficiency on the STS benchmark dataset. We extend our analysis to various model sizes and languages. Further, we discover the surprising efficacy of ELECTRA's generator model, which performs on par with BERT, using significantly fewer parameters and a substantially smaller embedding size. Finally, we observe further boosts by combining TMFT with a word similarity task or domain adaptive pre-training.
Do Not (Always) Look Right: Investigating the Capabilities of Decoder-Based Large Language Models for Sequence Labeling
Jan 25, 2024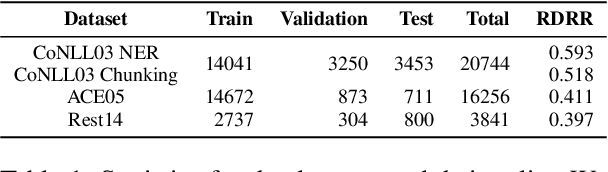
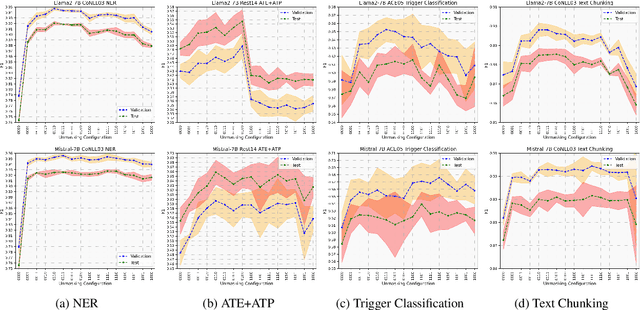
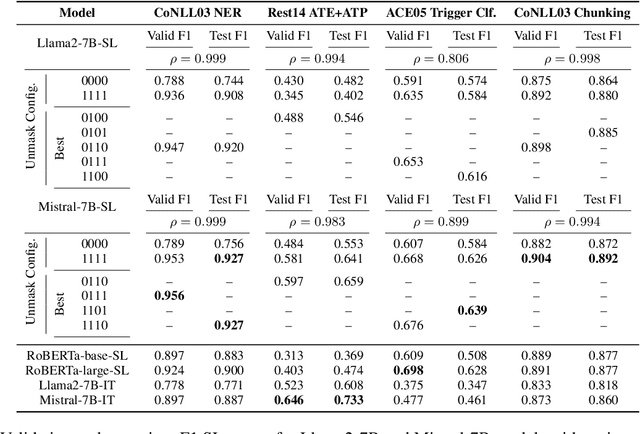
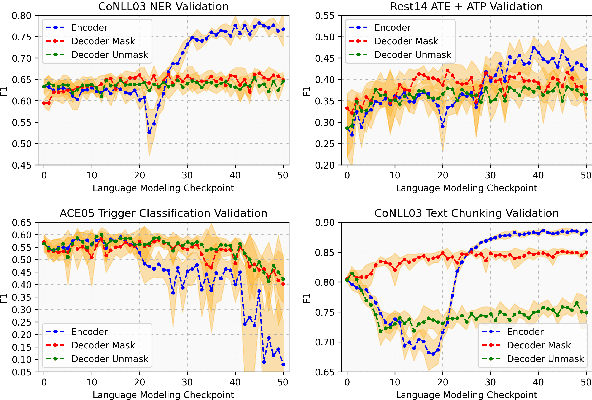
Pre-trained language models based on masked language modeling (MLM) objective excel in natural language understanding (NLU) tasks. While fine-tuned MLM-based encoders consistently outperform causal language modeling decoders of comparable size, a recent trend of scaling decoder models to multiple billion parameters resulted in large language models (LLMs), making them competitive with MLM-based encoders. Although scale amplifies their prowess in NLU tasks, LLMs fall short of SOTA results in information extraction (IE) tasks, many framed as sequence labeling (SL). However, whether this is an intrinsic limitation of LLMs or whether their SL performance can be improved remains unclear. To address this, we explore strategies to enhance the SL performance of "open" LLMs (Llama2 and Mistral) on IE tasks. We investigate bidirectional information flow within groups of decoder blocks, applying layer-wise removal or enforcement of the causal mask (CM) during LLM fine-tuning. This approach yields performance gains competitive with SOTA SL models, matching or outperforming the results of CM removal from all blocks. Our findings hold for diverse SL tasks, proving that "open" LLMs with layer-dependent CM removal outperform strong MLM-based encoders and instruction-tuned LLMs. However, we observe no effect from CM removal on a small scale when maintaining an equivalent model size, pre-training steps, and pre-training and fine-tuning data.
Out-of-Distribution Detection by Leveraging Between-Layer Transformation Smoothness
Oct 04, 2023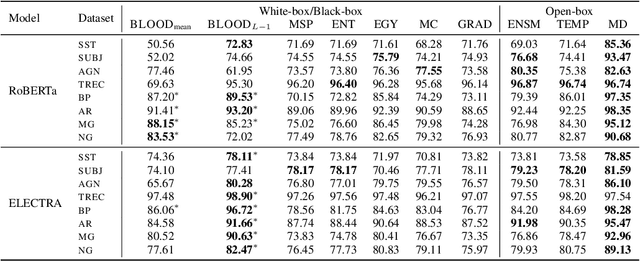
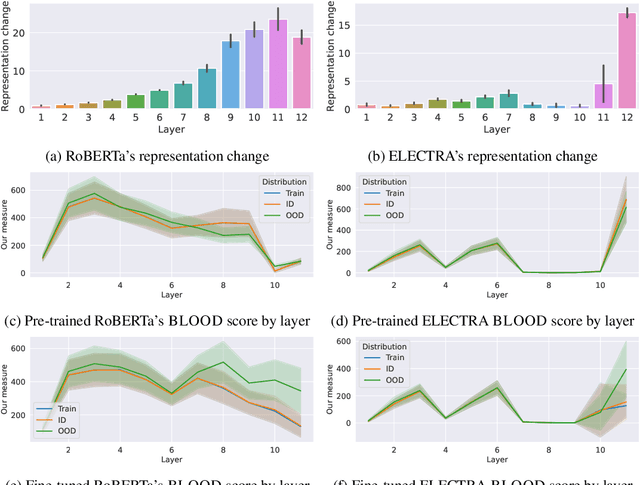
Effective OOD detection is crucial for reliable machine learning models, yet most current methods are limited in practical use due to requirements like access to training data or intervention in training. We present a novel method for detecting OOD data in deep neural networks based on transformation smoothness between intermediate layers of a network (BLOOD), which is applicable to pre-trained models without access to training data. BLOOD utilizes the tendency of between-layer representation transformations of in-distribution (ID) data to be smoother than the corresponding transformations of OOD data, a property that we also demonstrate empirically for Transformer networks. We evaluate BLOOD on several text classification tasks with Transformer networks and demonstrate that it outperforms methods with comparable resource requirements. Our analysis also suggests that when learning simpler tasks, OOD data transformations maintain their original sharpness, whereas sharpness increases with more complex tasks.