 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Parametrization with Compositional Adapters
Sep 26, 2025



Large language models (LLMs) often seamlessly adapt to new tasks through in-context learning (ICL) or supervised fine-tuning (SFT). However, both of these approaches face key limitations: ICL is inefficient when handling many demonstrations, and SFT incurs training overhead while sacrificing flexibility. Mapping instructions or demonstrations from context directly into adapter parameters offers an appealing alternative. While prior work explored generating adapters based on a single input context, it has overlooked the need to integrate multiple chunks of information. To address this gap, we introduce CompAs, a meta-learning framework that translates context into adapter parameters with a compositional structure. Adapters generated this way can be merged algebraically, enabling instructions, demonstrations, or retrieved passages to be seamlessly combined without reprocessing long prompts. Critically, this approach yields three benefits: lower inference cost, robustness to long-context instability, and establishes a principled solution when input exceeds the model's context window. Furthermore, CompAs encodes information into adapter parameters in a reversible manner, enabling recovery of input context through a decoder, facilitating safety and security. Empirical results on diverse multiple-choice and extractive question answering tasks show that CompAs outperforms ICL and prior generator-based methods, especially when scaling to more inputs. Our work establishes composable adapter generation as a practical and efficient alternative for scaling LLM deployment.
Improving Data and Parameter Efficiency of Neural Language Models Using Representation Analysis
Jul 16, 2025This thesis addresses challenges related to data and parameter efficiency in neural language models, with a focus on representation analysis and the introduction of new optimization techniques. The first part examines the properties and dynamics of language representations within neural models, emphasizing their significance in enhancing robustness and generalization. It proposes innovative approaches based on representation smoothness, including regularization strategies that utilize Jacobian and Hessian matrices to stabilize training and mitigate sensitivity to input perturbations. The second part focuses on methods to significantly enhance data and parameter efficiency by integrating active learning strategies with parameter-efficient fine-tuning, guided by insights from representation smoothness analysis. It presents smoothness-informed early-stopping techniques designed to eliminate the need for labeled validation sets and proposes innovative combinations of active learning and parameter-efficient fine-tuning to reduce labeling efforts and computational resources. Extensive experimental evaluations across various NLP tasks demonstrate that these combined approaches substantially outperform traditional methods in terms of performance, stability, and efficiency. The third part explores weak supervision techniques enhanced by in-context learning to effectively utilize unlabeled data, further reducing dependence on extensive labeling. It shows that using in-context learning as a mechanism for weak supervision enables models to better generalize from limited labeled data by leveraging unlabeled examples more effectively during training. Comprehensive empirical evaluations confirm significant gains in model accuracy, adaptability, and robustness, especially in low-resource settings and dynamic data environments.
Characterizing Linguistic Shifts in Croatian News via Diachronic Word Embeddings
Jun 16, 2025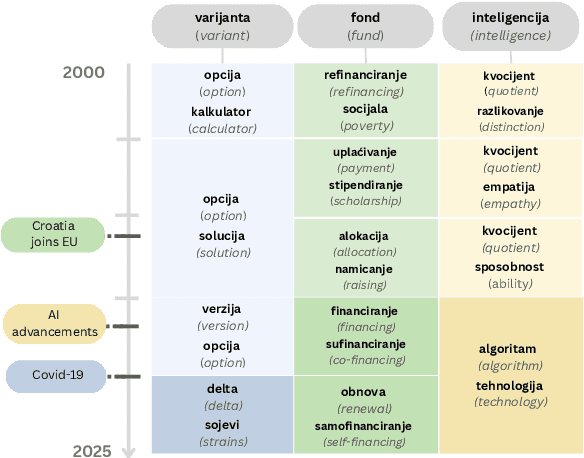
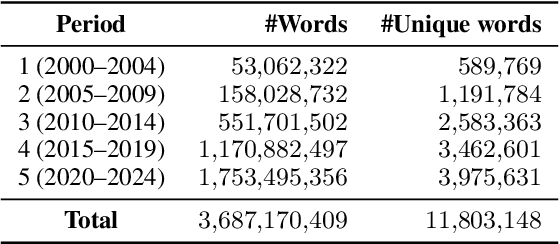
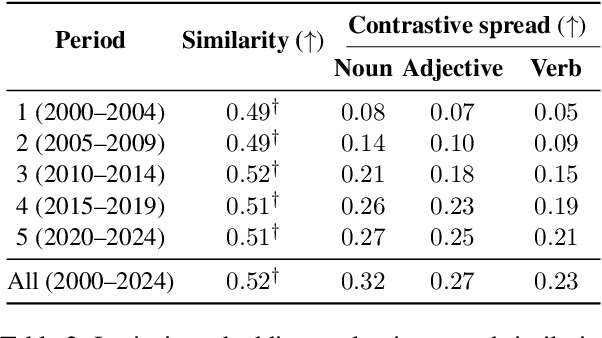
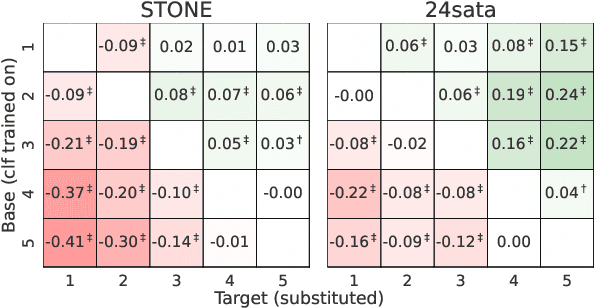
Measuring how semantics of words change over time improves our understanding of how cultures and perspectives change. Diachronic word embeddings help us quantify this shift, although previous studies leveraged substantial temporally annotated corpora. In this work, we use a corpus of 9.5 million Croatian news articles spanning the past 25 years and quantify semantic change using skip-gram word embeddings trained on five-year periods. Our analysis finds that word embeddings capture linguistic shifts of terms pertaining to major topics in this timespan (COVID-19, Croatia joining the European Union, technological advancements). We also find evidence that embeddings from post-2020 encode increased positivity in sentiment analysis tasks, contrasting studies reporting a decline in mental health over the same period.
Disentangling Latent Shifts of In-Context Learning Through Self-Training
Oct 02, 2024



In-context learning (ICL) has become essential in natural language processing, particularly with autoregressive large language models capable of learning from demonstrations provided within the prompt. However, ICL faces challenges with stability and long contexts, especially as the number of demonstrations grows, leading to poor generalization and inefficient inference. To address these issues, we introduce STICL (Self-Training ICL), an approach that disentangles the latent shifts of demonstrations from the latent shift of the query through self-training. STICL employs a teacher model to generate pseudo-labels and trains a student model using these labels, encoded in an adapter module. The student model exhibits weak-to-strong generalization, progressively refining its predictions over time. Our empirical results show that STICL improves generalization and stability, consistently outperforming traditional ICL methods and other disentangling strategies across both in-domain and out-of-domain data.
From Robustness to Improved Generalization and Calibration in Pre-trained Language Models
Mar 31, 2024



Enhancing generalization and uncertainty quantification in pre-trained language models (PLMs) is crucial for their effectiveness and reliability. Building on machine learning research that established the importance of robustness for improving generalization, we investigate the role of representation smoothness, achieved via Jacobian and Hessian regularization, in enhancing PLM performance. Although such regularization methods have proven effective in computer vision, their application in natural language processing (NLP), where PLM inputs are derived from a discrete domain, poses unique challenges. We introduce a novel two-phase regularization approach, JacHess, which minimizes the norms of the Jacobian and Hessian matrices within PLM intermediate representations relative to their inputs. Our evaluation using the GLUE benchmark demonstrates that JacHess significantly improves in-domain generalization and calibration in PLMs, outperforming unregularized fine-tuning and other similar regularization methods.
Out-of-Distribution Detection by Leveraging Between-Layer Transformation Smoothness
Oct 04, 2023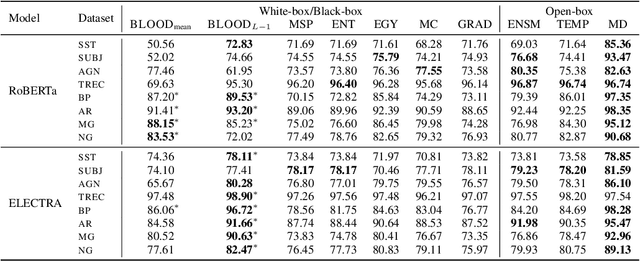
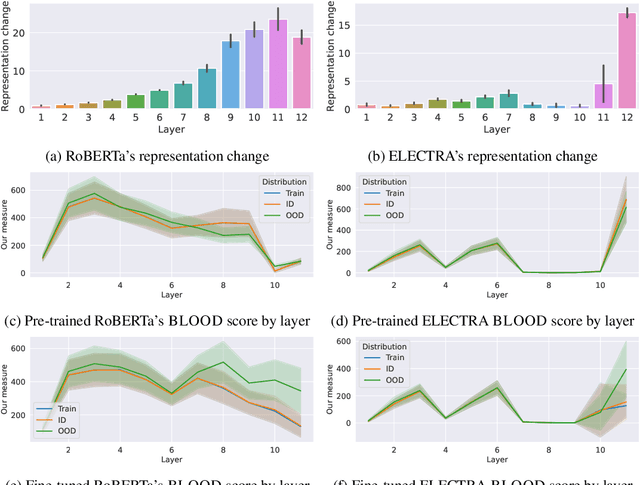
Effective OOD detection is crucial for reliable machine learning models, yet most current methods are limited in practical use due to requirements like access to training data or intervention in training. We present a novel method for detecting OOD data in deep neural networks based on transformation smoothness between intermediate layers of a network (BLOOD), which is applicable to pre-trained models without access to training data. BLOOD utilizes the tendency of between-layer representation transformations of in-distribution (ID) data to be smoother than the corresponding transformations of OOD data, a property that we also demonstrate empirically for Transformer networks. We evaluate BLOOD on several text classification tasks with Transformer networks and demonstrate that it outperforms methods with comparable resource requirements. Our analysis also suggests that when learning simpler tasks, OOD data transformations maintain their original sharpness, whereas sharpness increases with more complex tasks.
Parameter-Efficient Language Model Tuning with Active Learning in Low-Resource Settings
May 23, 2023
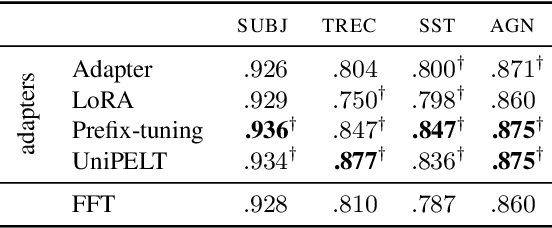
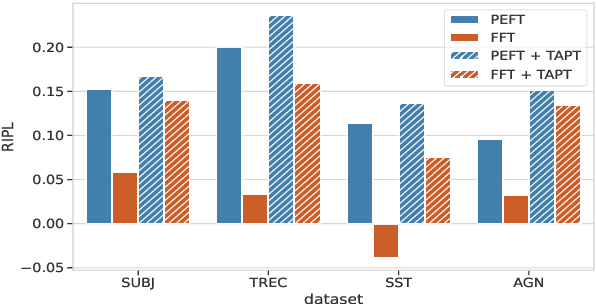
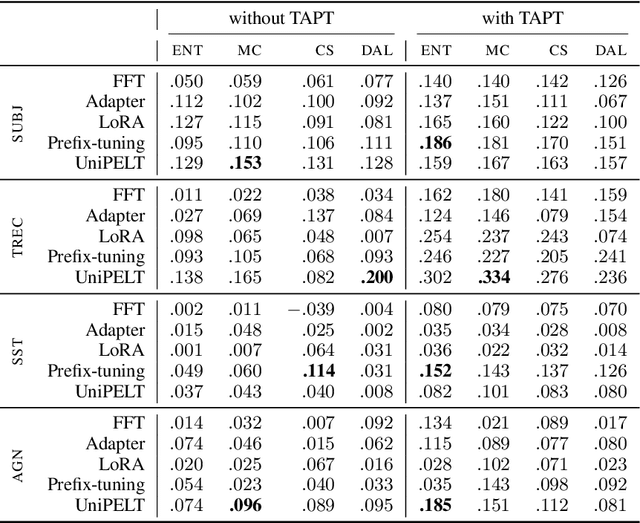
Pre-trained language models (PLMs) have ignited a surge in demand for effective fine-tuning techniques, particularly in low-resource domains and languages. Active learning (AL), a set of algorithms designed to decrease labeling costs by minimizing label complexity, has shown promise in confronting the labeling bottleneck. Concurrently, adapter modules, designed for parameter-efficient fine-tuning (PEFT), have showcased notable potential in low-resource settings. However, the interplay between AL and adapter-based PEFT remains unexplored. In our study, we empirically investigate PEFT behavior with AL in low-resource settings for text classification tasks. Our findings affirm the superiority of PEFT over full-fine tuning (FFT) in low-resource settings and demonstrate that this advantage persists in AL setups. Finally, we delve into the properties of PEFT and FFT through the lens of forgetting dynamics and instance-level representations, linking them to AL instance selection behavior and the stability of PEFT. Our research underscores the synergistic potential of AL, PEFT, and TAPT in low-resource settings, paving the way for advancements in efficient and effective fine-tuning.
On Dataset Transferability in Active Learning for Transformers
May 16, 2023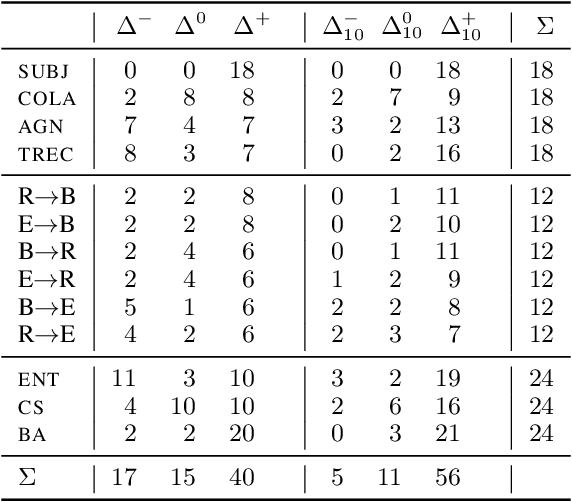
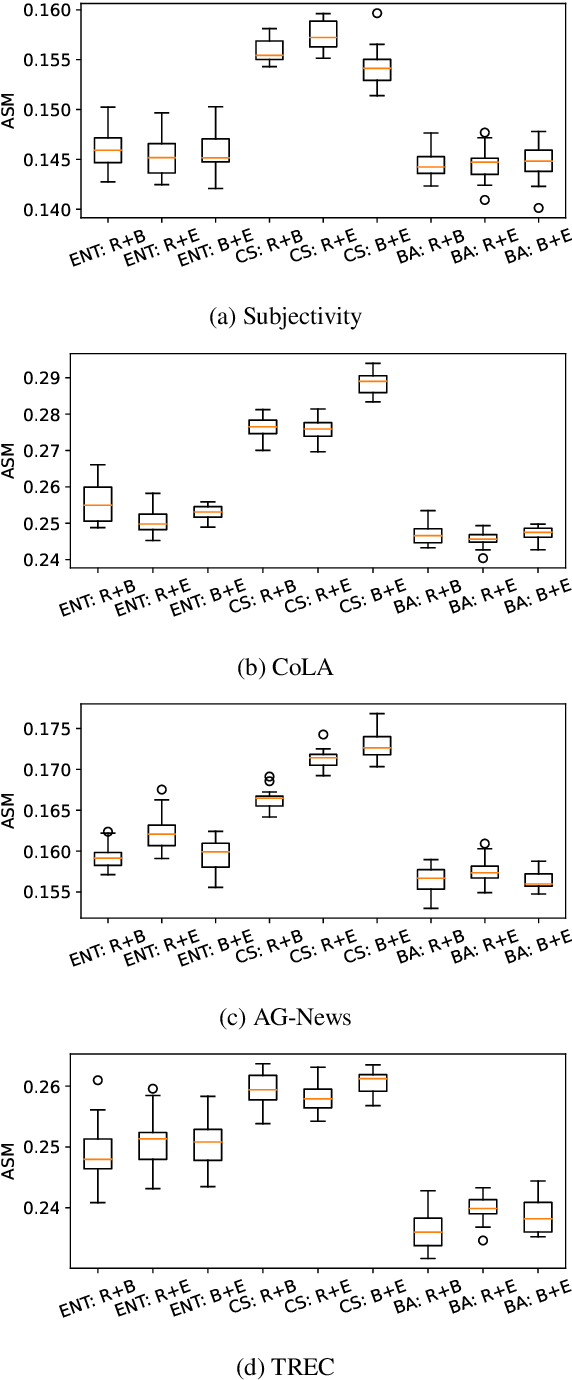
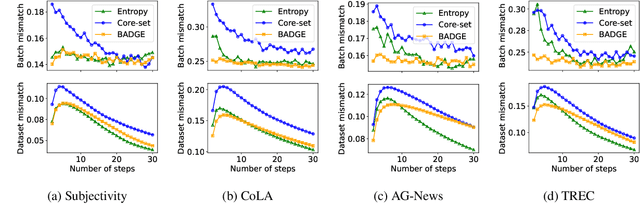
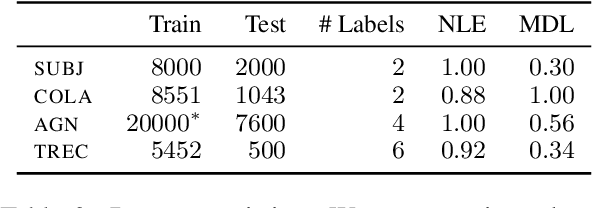
Active learning (AL) aims to reduce labeling costs by querying the examples most beneficial for model learning. While the effectiveness of AL for fine-tuning transformer-based pre-trained language models (PLMs) has been demonstrated, it is less clear to what extent the AL gains obtained with one model transfer to others. We consider the problem of transferability of actively acquired datasets in text classification and investigate whether AL gains persist when a dataset built using AL coupled with a specific PLM is used to train a different PLM. We link the AL dataset transferability to the similarity of instances queried by the different PLMs and show that AL methods with similar acquisition sequences produce highly transferable datasets regardless of the models used. Additionally, we show that the similarity of acquisition sequences is influenced more by the choice of the AL method than the choice of the model.
You Are What You Talk About: Inducing Evaluative Topics for Personality Analysis
Feb 01, 2023Expressing attitude or stance toward entities and concepts is an integral part of human behavior and personality. Recently, evaluative language data has become more accessible with social media's rapid growth, enabling large-scale opinion analysis. However, surprisingly little research examines the relationship between personality and evaluative language. To bridge this gap, we introduce the notion of evaluative topics, obtained by applying topic models to pre-filtered evaluative text from social media. We then link evaluative topics to individual text authors to build their evaluative profiles. We apply evaluative profiling to Reddit comments labeled with personality scores and conduct an exploratory study on the relationship between evaluative topics and Big Five personality facets, aiming for a more interpretable, facet-level analysis. Finally, we validate our approach by observing correlations consistent with prior research in personality psychology.
Smooth Sailing: Improving Active Learning for Pre-trained Language Models with Representation Smoothness Analysis
Dec 20, 2022
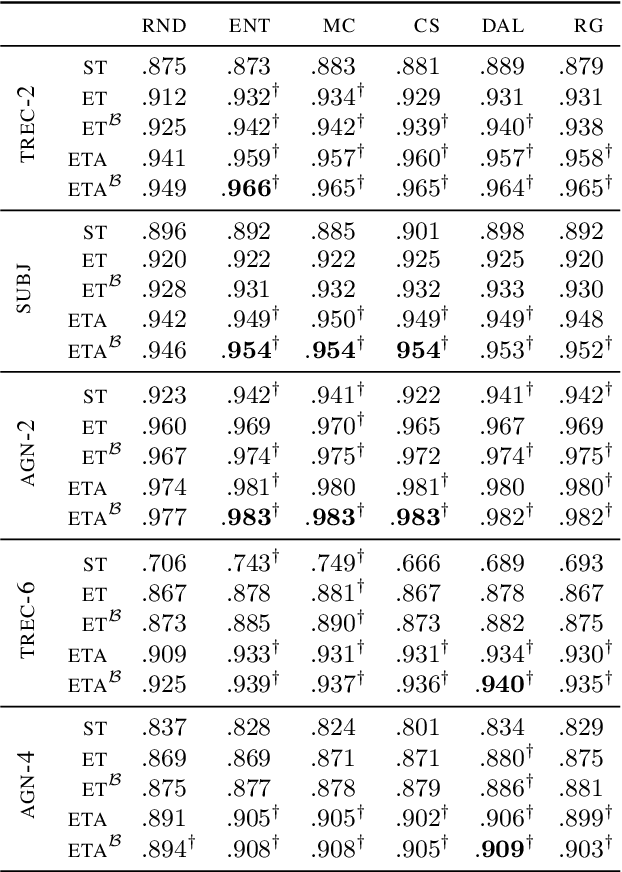
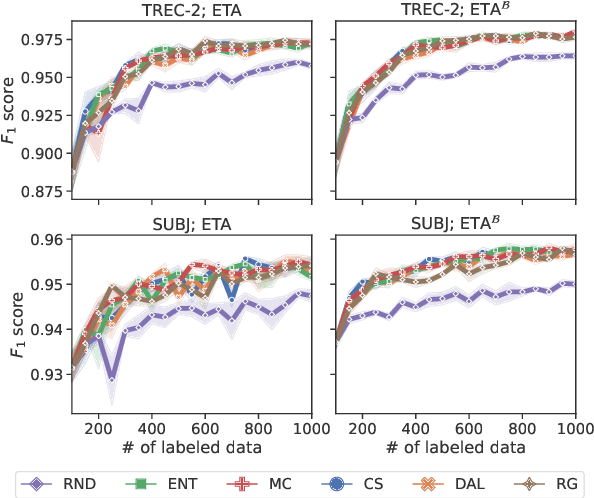
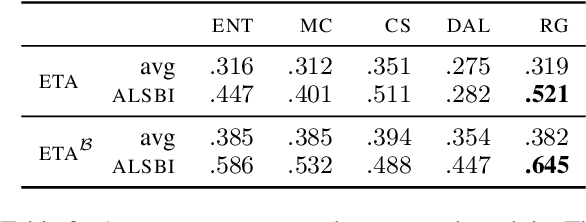
Developed as a solution to a practical need, active learning (AL) methods aim to reduce label complexity and the annotations costs in supervised learning. While recent work has demonstrated the benefit of using AL in combination with large pre-trained language models (PLMs), it has often overlooked the practical challenges that hinder the feasibility of AL in realistic settings. We address these challenges by leveraging representation smoothness analysis to improve the effectiveness of AL. We develop an early stopping technique that does not require a validation set -- often unavailable in realistic AL settings -- and observe significant improvements across multiple datasets and AL methods. Additionally, we find that task adaptation improves AL, whereas standard short fine-tuning in AL does not provide improvements over random sampling. Our work establishes the usefulness of representation smoothness analysis in AL and presents an AL stopping criterion that reduces label complexity.