 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Detection by Leveraging Between-Layer Transformation Smoothness
Oct 04, 2023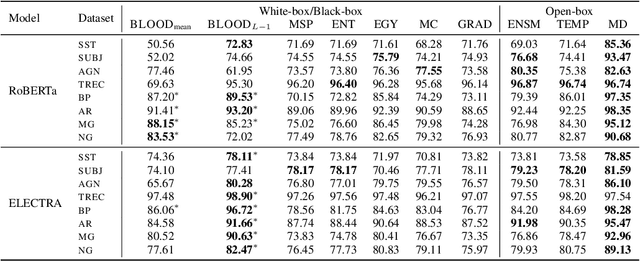
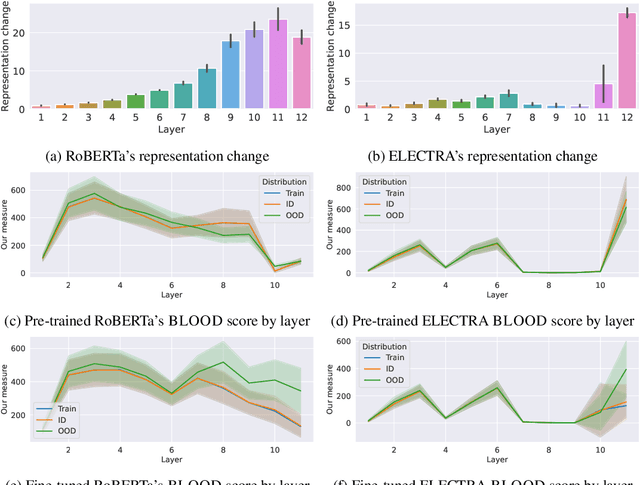
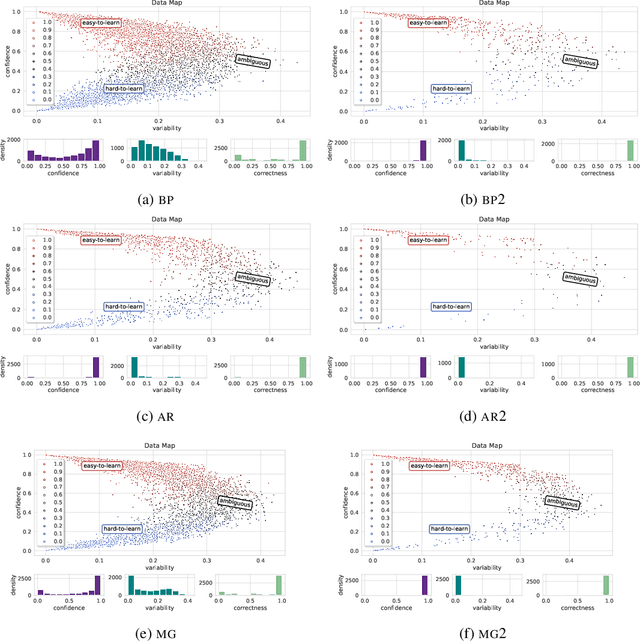
Effective OOD detection is crucial for reliable machine learning models, yet most current methods are limited in practical use due to requirements like access to training data or intervention in training. We present a novel method for detecting OOD data in deep neural networks based on transformation smoothness between intermediate layers of a network (BLOOD), which is applicable to pre-trained models without access to training data. BLOOD utilizes the tendency of between-layer representation transformations of in-distribution (ID) data to be smoother than the corresponding transformations of OOD data, a property that we also demonstrate empirically for Transformer networks. We evaluate BLOOD on several text classification tasks with Transformer networks and demonstrate that it outperforms methods with comparable resource requirements. Our analysis also suggests that when learning simpler tasks, OOD data transformations maintain their original sharpness, whereas sharpness increases with more complex tasks.
On Dataset Transferability in Active Learning for Transformers
May 16, 2023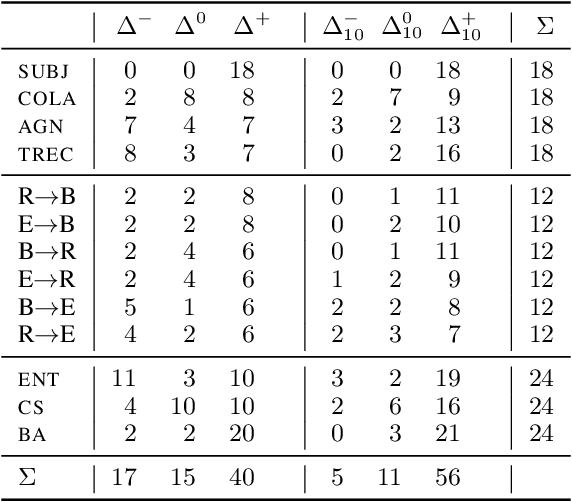
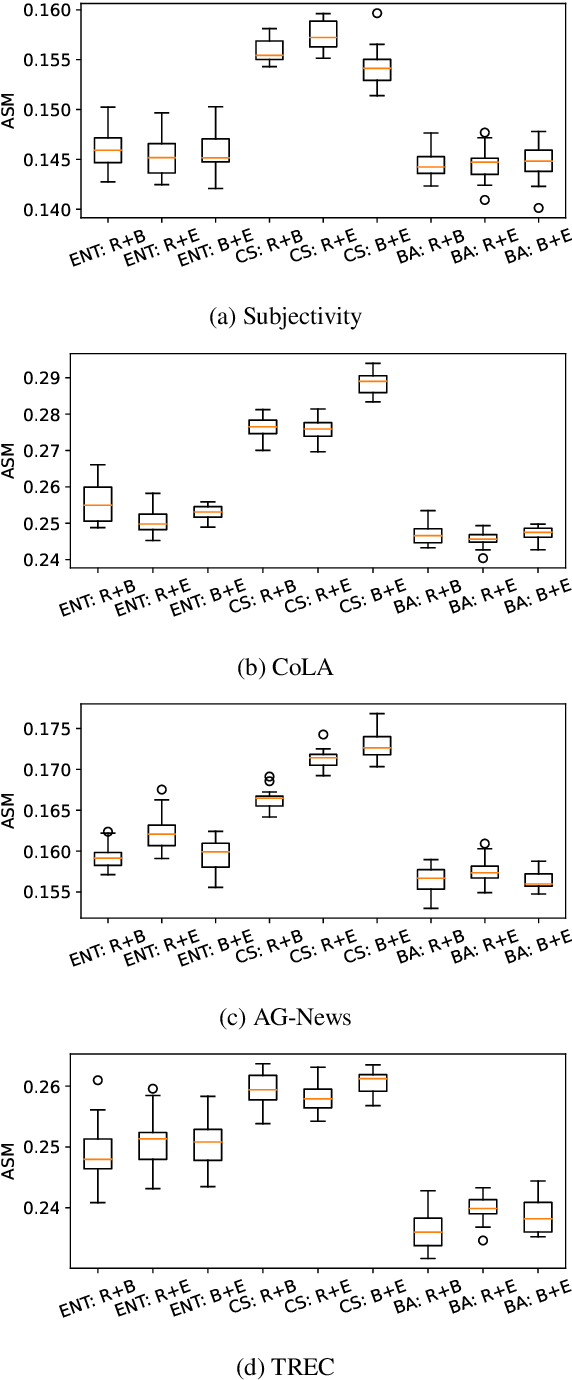
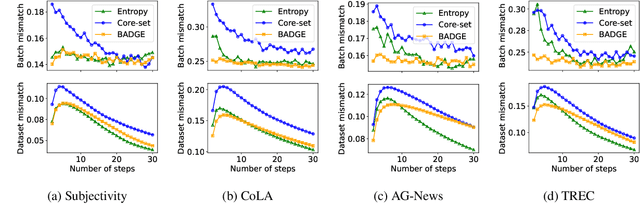
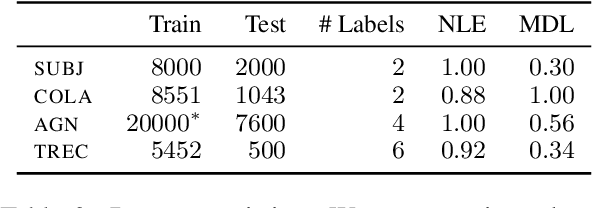
Active learning (AL) aims to reduce labeling costs by querying the examples most beneficial for model learning. While the effectiveness of AL for fine-tuning transformer-based pre-trained language models (PLMs) has been demonstrated, it is less clear to what extent the AL gains obtained with one model transfer to others. We consider the problem of transferability of actively acquired datasets in text classification and investigate whether AL gains persist when a dataset built using AL coupled with a specific PLM is used to train a different PLM. We link the AL dataset transferability to the similarity of instances queried by the different PLMs and show that AL methods with similar acquisition sequences produce highly transferable datasets regardless of the models used. Additionally, we show that the similarity of acquisition sequences is influenced more by the choice of the AL method than the choice of the model.
ALANNO: An Active Learning Annotation System for Mortals
Nov 11, 2022In today's data-driven society, supervised machine learning is rapidly evolving, and the need for labeled data is increasing. However, the process of acquiring labels is often expensive and tedious. For this reason, we developed ALANNO, an open-source annotation system for NLP tasks powered by active learning. We focus on the practical challenges in deploying active learning systems and try to find solutions to make active learning effective in real-world applications. We support the system with a wealth of active learning methods and underlying machine learning models. In addition, we leave open the possibility to add new methods, which makes the platform useful for both high-quality data annotation and research purposes.