 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth Sailing: Improving Active Learning for Pre-trained Language Models with Representation Smoothness Analysis
Paper and Code
Dec 20, 2022
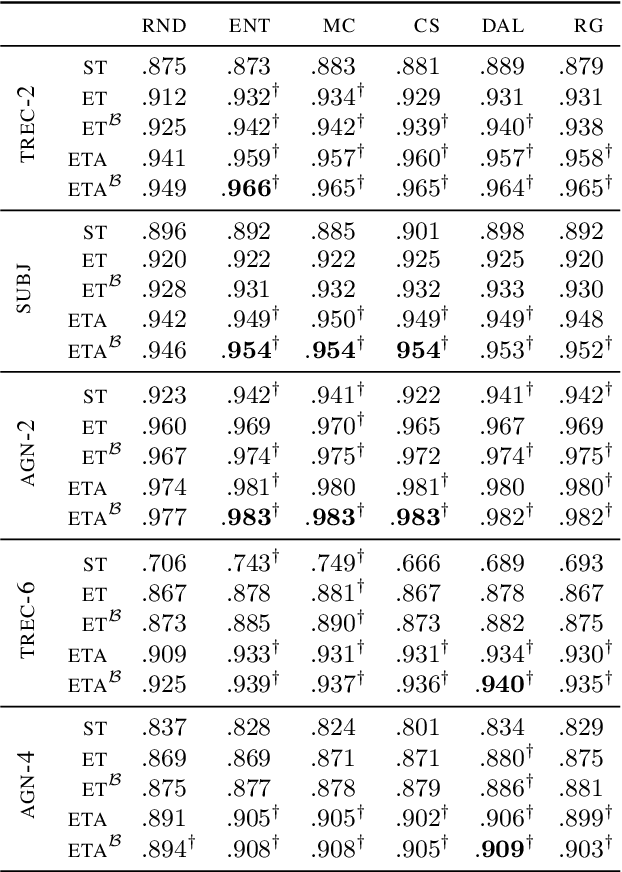
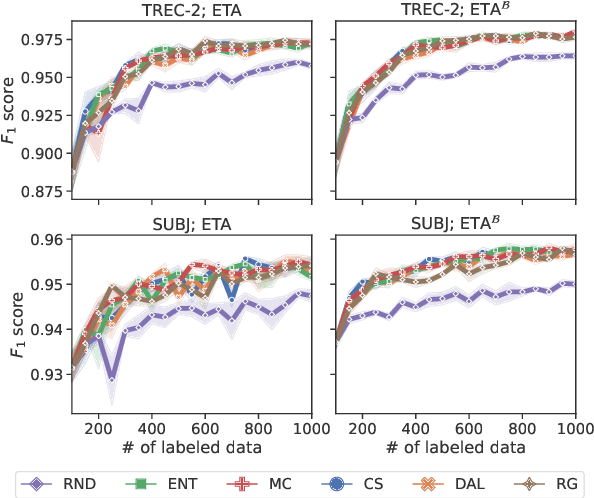
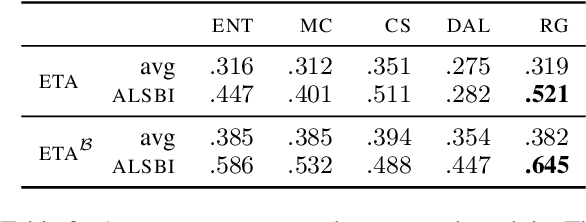
Developed as a solution to a practical need, active learning (AL) methods aim to reduce label complexity and the annotations costs in supervised learning. While recent work has demonstrated the benefit of using AL in combination with large pre-trained language models (PLMs), it has often overlooked the practical challenges that hinder the feasibility of AL in realistic settings. We address these challenges by leveraging representation smoothness analysis to improve the effectiveness of AL. We develop an early stopping technique that does not require a validation set -- often unavailable in realistic AL settings -- and observe significant improvements across multiple datasets and AL methods. Additionally, we find that task adaptation improves AL, whereas standard short fine-tuning in AL does not provide improvements over random sampling. Our work establishes the usefulness of representation smoothness analysis in AL and presents an AL stopping criterion that reduces label complexity.