 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Language Model Tuning with Active Learning in Low-Resource Settings
Paper and Code
May 23, 2023
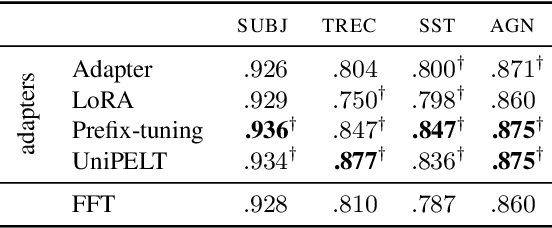
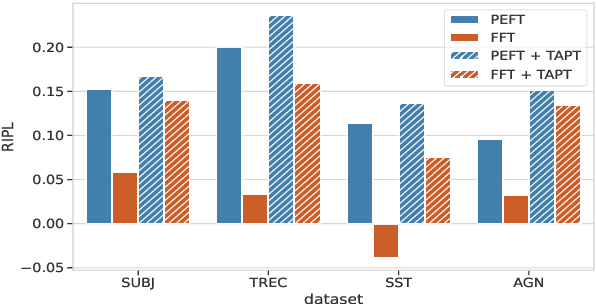
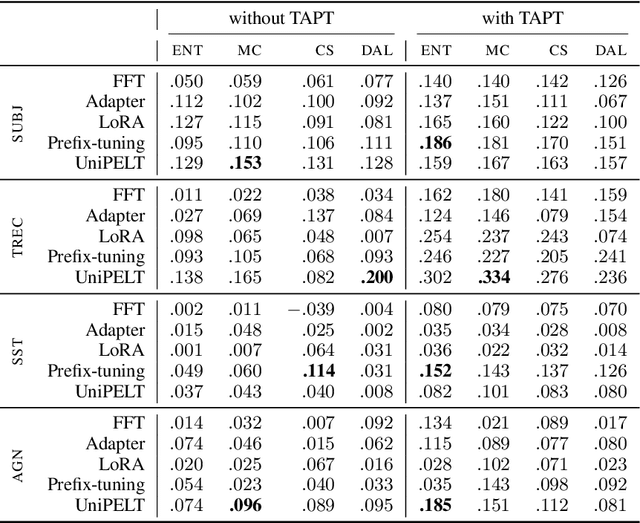
Pre-trained language models (PLMs) have ignited a surge in demand for effective fine-tuning techniques, particularly in low-resource domains and languages. Active learning (AL), a set of algorithms designed to decrease labeling costs by minimizing label complexity, has shown promise in confronting the labeling bottleneck. Concurrently, adapter modules, designed for parameter-efficient fine-tuning (PEFT), have showcased notable potential in low-resource settings. However, the interplay between AL and adapter-based PEFT remains unexplored. In our study, we empirically investigate PEFT behavior with AL in low-resource settings for text classification tasks. Our findings affirm the superiority of PEFT over full-fine tuning (FFT) in low-resource settings and demonstrate that this advantage persists in AL setups. Finally, we delve into the properties of PEFT and FFT through the lens of forgetting dynamics and instance-level representations, linking them to AL instance selection behavior and the stability of PEFT. Our research underscores the synergistic potential of AL, PEFT, and TAPT in low-resource settings, paving the way for advancements in efficient and effective fine-tuning.