 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaim Check-Worthiness Detection: How Well do LLMs Grasp Annotation Guidelines?
Paper and Code
Apr 18, 2024
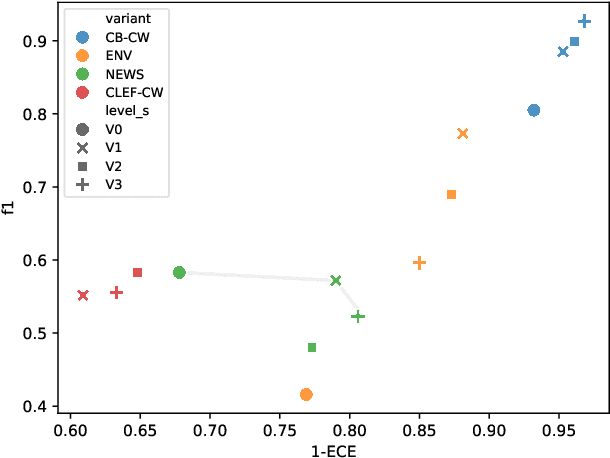

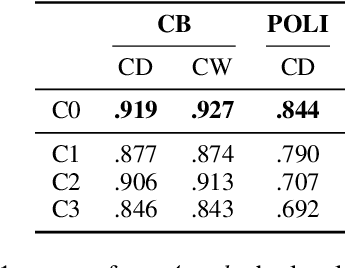
The increasing threat of disinformation calls for automating parts of the fact-checking pipeline. Identifying text segments requiring fact-checking is known as claim detection (CD) and claim check-worthiness detection (CW), the latter incorporating complex domain-specific criteria of worthiness and often framed as a ranking task. Zero- and few-shot LLM prompting is an attractive option for both tasks, as it bypasses the need for labeled datasets and allows verbalized claim and worthiness criteria to be directly used for prompting. We evaluate the LLMs' predictive and calibration accuracy on five CD/CW datasets from diverse domains, each utilizing a different worthiness criterion. We investigate two key aspects: (1) how best to distill factuality and worthiness criteria into a prompt and (2) what amount of context to provide for each claim. To this end, we experiment with varying the level of prompt verbosity and the amount of contextual information provided to the model. Our results show that optimal prompt verbosity is domain-dependent, adding context does not improve performance, and confidence scores can be directly used to produce reliable check-worthiness rankings.