 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedGAI: Federated Style Learning with Cloud-Edge Collaboration for Generative AI in Fashion Design
Mar 16, 2025Collaboration can amalgamate diverse ideas, styles, and visual elements, fostering creativity and innovation among different designers. In collaborative design, sketches play a pivotal role as a means of expressing design creativity. However, designers often tend to not openly share these meticulously crafted sketches. This phenomenon of data island in the design area hinders its digital transformation under the third wave of AI. In this paper, we introduce a Federated Generative Artificial Intelligence Clothing system, namely FedGAI, employing federated learning to aid in sketch design. FedGAI is committed to establishing an ecosystem wherein designers can exchange sketch styles among themselves. Through FedGAI, designers can generate sketches that incorporate various designers' styles from their peers, drawing inspiration from collaboration without the need for data disclosure or upload. Extensive performance evaluations indicate that our FedGAI system can produce multi-styled sketches of comparable quality to human-designed ones while significantly enhancing efficiency compared to hand-drawn sketches.
BRIEDGE: EEG-Adaptive Edge AI for Multi-Brain to Multi-Robot Interaction
Mar 14, 2024



Recent advances in EEG-based BCI technologies have revealed the potential of brain-to-robot collaboration through the integration of sensing, computing, communication, and control. In this paper, we present BRIEDGE as an end-to-end system for multi-brain to multi-robot interaction through an EEG-adaptive neural network and an encoding-decoding communication framework, as illustrated in Fig.1. As depicted, the edge mobile server or edge portable server will collect EEG data from the users and utilize the EEG-adaptive neural network to identify the users' intentions. The encoding-decoding communication framework then encodes the EEG-based semantic information and decodes it into commands in the process of data transmission. To better extract the joint features of heterogeneous EEG data as well as enhance classification accuracy, BRIEDGE introduces an informer-based ProbSparse self-attention mechanism. Meanwhile, parallel and secure transmissions for multi-user multi-task scenarios under physical channels are addressed by dynamic autoencoder and autodecoder communications. From mobile computing and edge AI perspectives, model compression schemes composed of pruning, weight sharing, and quantization are also used to deploy lightweight EEG-adaptive models running on both transmitter and receiver sides. Based on the effectiveness of these components, a code map representing various commands enables multiple users to control multiple intelligent agents concurrently. Our experiments in comparison with state-of-the-art works show that BRIEDGE achieves the best classification accuracy of heterogeneous EEG data, and more stable performance under noisy environments.
Coreference Reasoning in Machine Reading Comprehension
Dec 31, 2020
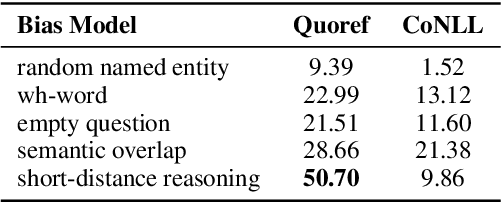


The ability to reason about multiple references to a given entity is essential for natural language understanding and has been long studied in NLP. In recent years, as the format of Question Answering (QA) became a standard for machine reading comprehension (MRC), there have been data collection efforts, e.g., Dasigi et al. (2019), that attempt to evaluate the ability of MRC models to reason about coreference. However, as we show, coreference reasoning in MRC is a greater challenge than was earlier thought; MRC datasets do not reflect the natural distribution and, consequently, the challenges of coreference reasoning. Specifically, success on these datasets does not reflect a model's proficiency in coreference reasoning. We propose a methodology for creating reading comprehension datasets that better reflect the challenges of coreference reasoning and use it to show that state-of-the-art models still struggle with these phenomena. Furthermore, we develop an effective way to use naturally occurring coreference phenomena from annotated coreference resolution datasets when training MRC models. This allows us to show an improvement in the coreference reasoning abilities of state-of-the-art models across various MRC datasets. We will release all the code and the resulting dataset at https://github.com/UKPLab/coref-reasoning-in-qa.
Improving QA Generalization by Concurrent Modeling of Multiple Biases
Oct 07, 2020
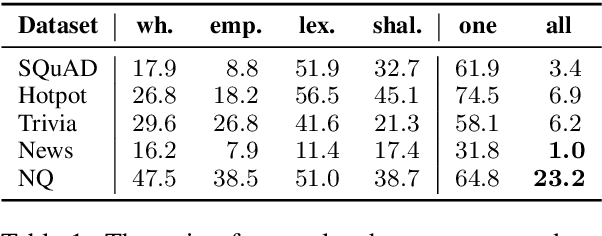
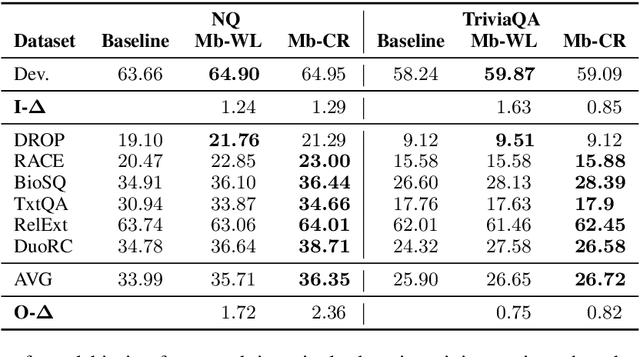
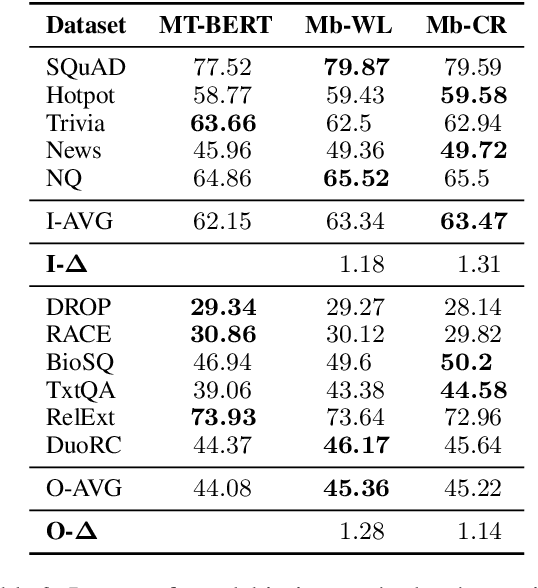
Existing NLP datasets contain various biases that models can easily exploit to achieve high performances on the corresponding evaluation sets. However, focusing on dataset-specific biases limits their ability to learn more generalizable knowledge about the task from more general data patterns. In this paper, we investigate the impact of debiasing methods for improving generalization and propose a general framework for improving the performance on both in-domain and out-of-domain datasets by concurrent modeling of multiple biases in the training data. Our framework weights each example based on the biases it contains and the strength of those biases in the training data. It then uses these weights in the training objective so that the model relies less on examples with high bias weights. We extensively evaluate our framework on extractive question answering with training data from various domains with multiple biases of different strengths. We perform the evaluations in two different settings, in which the model is trained on a single domain or multiple domains simultaneously, and show its effectiveness in both settings compared to state-of-the-art debiasing methods.