 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoreference Reasoning in Machine Reading Comprehension
Paper and Code

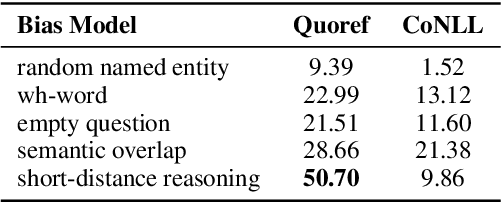


The ability to reason about multiple references to a given entity is essential for natural language understanding and has been long studied in NLP. In recent years, as the format of Question Answering (QA) became a standard for machine reading comprehension (MRC), there have been data collection efforts, e.g., Dasigi et al. (2019), that attempt to evaluate the ability of MRC models to reason about coreference. However, as we show, coreference reasoning in MRC is a greater challenge than was earlier thought; MRC datasets do not reflect the natural distribution and, consequently, the challenges of coreference reasoning. Specifically, success on these datasets does not reflect a model's proficiency in coreference reasoning. We propose a methodology for creating reading comprehension datasets that better reflect the challenges of coreference reasoning and use it to show that state-of-the-art models still struggle with these phenomena. Furthermore, we develop an effective way to use naturally occurring coreference phenomena from annotated coreference resolution datasets when training MRC models. This allows us to show an improvement in the coreference reasoning abilities of state-of-the-art models across various MRC datasets. We will release all the code and the resulting dataset at https://github.com/UKPLab/coref-reasoning-in-qa.