 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedGAI: Federated Style Learning with Cloud-Edge Collaboration for Generative AI in Fashion Design
Mar 16, 2025Collaboration can amalgamate diverse ideas, styles, and visual elements, fostering creativity and innovation among different designers. In collaborative design, sketches play a pivotal role as a means of expressing design creativity. However, designers often tend to not openly share these meticulously crafted sketches. This phenomenon of data island in the design area hinders its digital transformation under the third wave of AI. In this paper, we introduce a Federated Generative Artificial Intelligence Clothing system, namely FedGAI, employing federated learning to aid in sketch design. FedGAI is committed to establishing an ecosystem wherein designers can exchange sketch styles among themselves. Through FedGAI, designers can generate sketches that incorporate various designers' styles from their peers, drawing inspiration from collaboration without the need for data disclosure or upload. Extensive performance evaluations indicate that our FedGAI system can produce multi-styled sketches of comparable quality to human-designed ones while significantly enhancing efficiency compared to hand-drawn sketches.
Infra-YOLO: Efficient Neural Network Structure with Model Compression for Real-Time Infrared Small Object Detection
Aug 14, 2024
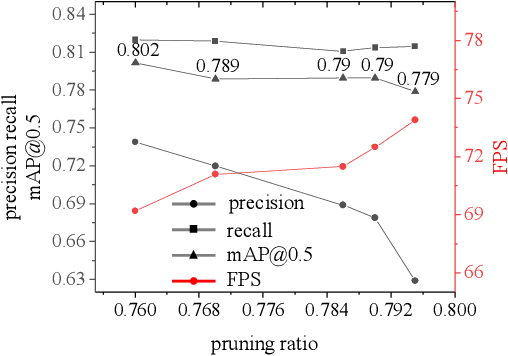
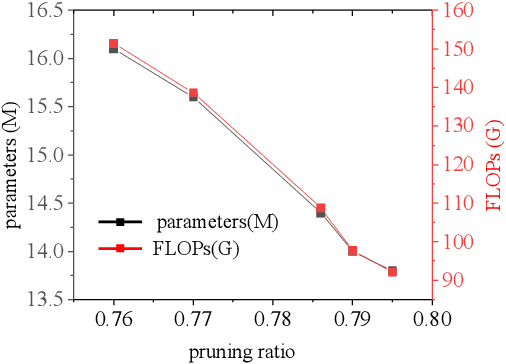
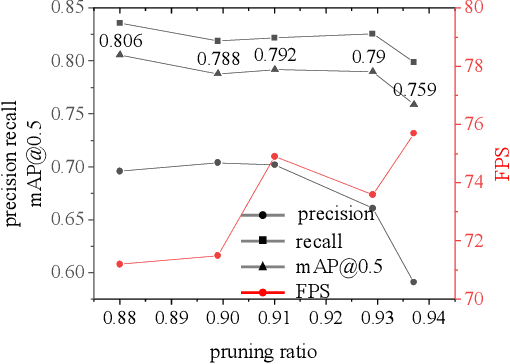
Although convolutional neural networks have made outstanding achievements in visible light target detection, there are still many challenges in infrared small object detection because of the low signal-to-noise ratio, incomplete object structure, and a lack of reliable infrared small object dataset. To resolve limitations of the infrared small object dataset, a new dataset named InfraTiny was constructed, and more than 85% bounding box is less than 32x32 pixels (3218 images and a total of 20,893 bounding boxes). A multi-scale attention mechanism module (MSAM) and a Feature Fusion Augmentation Pyramid Module (FFAFPM) were proposed and deployed onto embedded devices. The MSAM enables the network to obtain scale perception information by acquiring different receptive fields, while the background noise information is suppressed to enhance feature extraction ability. The proposed FFAFPM can enrich semantic information, and enhance the fusion of shallow feature and deep feature, thus false positive results have been significantly reduced. By integrating the proposed methods into the YOLO model, which is named Infra-YOLO, infrared small object detection performance has been improved. Compared to yolov3, mAP@0.5 has been improved by 2.7%; and compared to yolov4, that by 2.5% on the InfraTiny dataset. The proposed Infra-YOLO was also transferred onto the embedded device in the unmanned aerial vehicle (UAV) for real application scenarios, where the channel pruning method is adopted to reduce FLOPs and to achieve a tradeoff between speed and accuracy. Even if the parameters of Infra-YOLO are reduced by 88% with the pruning method, a gain of 0.7% is still achieved on mAP@0.5 compared to yolov3, and a gain of 0.5% compared to yolov4. Experimental results show that the proposed MSAM and FFAFPM method can improve infrared small object detection performance compared with the previous benchmark method.
Simple Yet Efficient: Towards Self-Supervised FG-SBIR with Unified Sample Feature Alignment
Jun 17, 2024Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) aims to minimize the distance between sketches and corresponding images in the embedding space. However, scalability is hindered by the growing complexity of solutions, mainly due to the abstract nature of fine-grained sketches. In this paper, we propose a simple yet efficient approach to narrow the gap between the two modes. It mainly facilitates unified mutual information sharing both intra- and inter-samples, rather than treating them as a single feature alignment problem between modalities. Specifically, our approach includes: (i) Employing dual weight-sharing networks to optimize alignment within sketch and image domain, which also effectively mitigates model learning saturation issues. (ii) Introducing an objective optimization function based on contrastive loss to enhance the model's ability to align features intra- and inter-samples. (iii) Presenting a learnable TRSM combined of self-attention and cross-attention to promote feature representations among tokens, further enhancing sample alignment in the embedding space. Our framework achieves excellent results on CNN- and ViT-based backbones. Extensive experiments demonstrate its superiority over existing methods. We also introduce Cloths-V1, the first professional fashion sketches and images dataset, utilized to validate our method and will be beneficial for other applications.
HAIFIT: Human-Centered AI for Fashion Image Translation
Mar 25, 2024In the realm of fashion design, sketches serve as the canvas for expressing an artist's distinctive drawing style and creative vision, capturing intricate details like stroke variations and texture nuances. The advent of sketch-to-image cross-modal translation technology has notably aided designers. However, existing methods often compromise these sketch details during image generation, resulting in images that deviate from the designer's intended concept. This limitation hampers the ability to offer designers a precise preview of the final output. To overcome this challenge, we introduce HAIFIT, a novel approach that transforms sketches into high-fidelity, lifelike clothing images by integrating multi-scale features and capturing extensive feature map dependencies from diverse perspectives. Through extensive qualitative and quantitative evaluations conducted on our self-collected dataset, our method demonstrates superior performance compared to existing methods in generating photorealistic clothing images. Our method excels in preserving the distinctive style and intricate details essential for fashion design applications.
Domain Adaptation with Incomplete Target Domains
Dec 03, 2020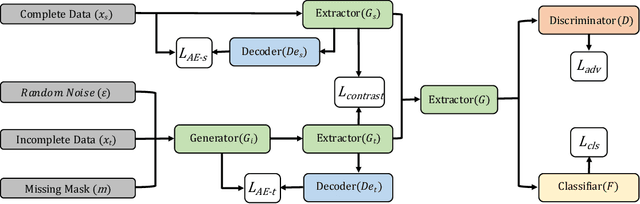
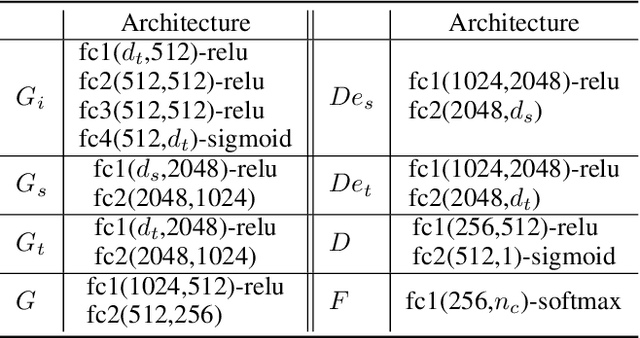
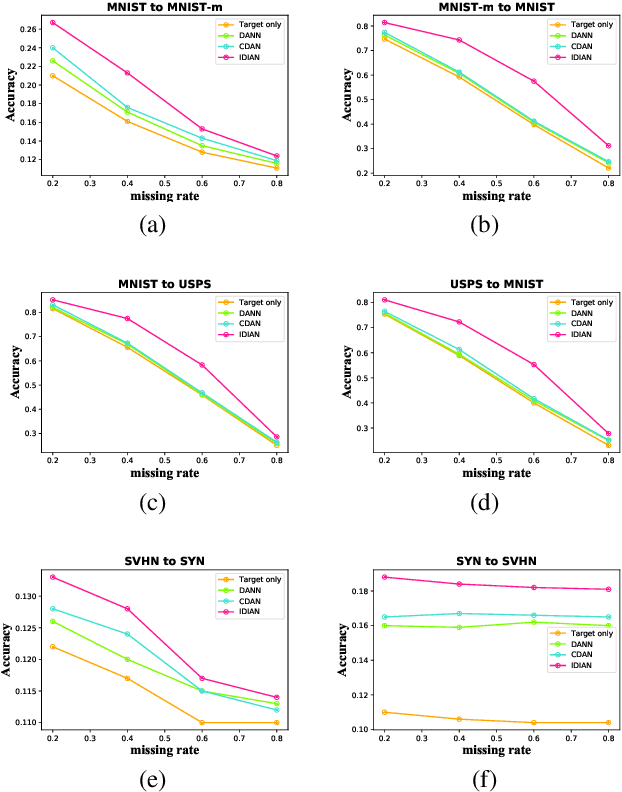

Domain adaptation, as a task of reducing the annotation cost in a target domain by exploiting the existing labeled data in an auxiliary source domain, has received a lot of attention in the research community. However, the standard domain adaptation has assumed perfectly observed data in both domains, while in real world applications the existence of missing data can be prevalent. In this paper, we tackle a more challenging domain adaptation scenario where one has an incomplete target domain with partially observed data. We propose an Incomplete Data Imputation based Adversarial Network (IDIAN) model to address this new domain adaptation challenge. In the proposed model, we design a data imputation module to fill the missing feature values based on the partial observations in the target domain, while aligning the two domains via deep adversarial adaption. We conduct experiments on both cross-domain benchmark tasks and a real world adaptation task with imperfect target domains. The experimental results demonstrate the effectiveness of the proposed method.
A Transductive Multi-Head Model for Cross-Domain Few-Shot Learning
Jun 08, 2020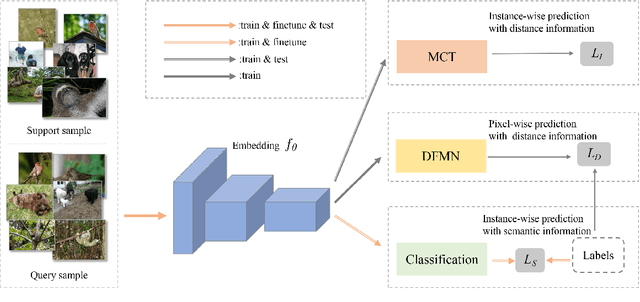
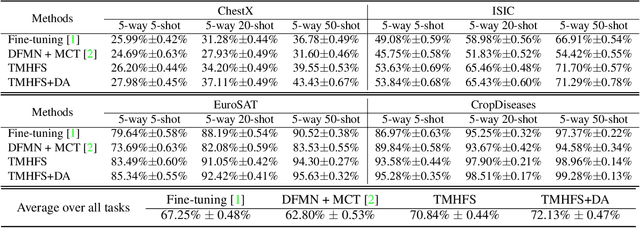
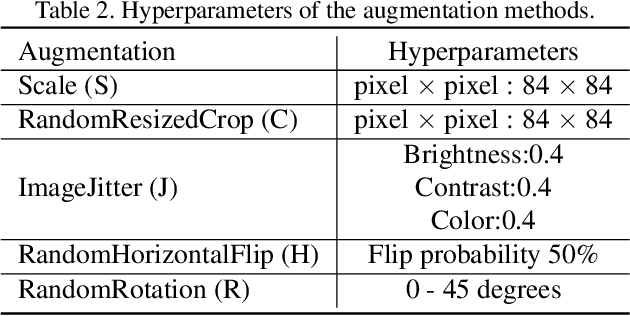
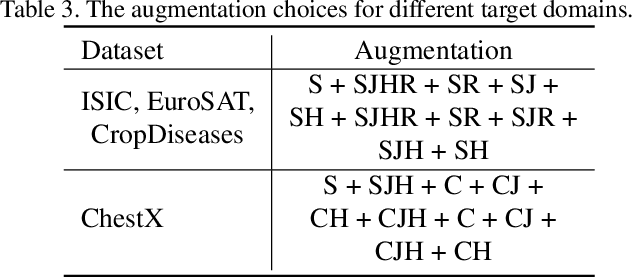
In this paper, we present a new method, Transductive Multi-Head Few-Shot learning (TMHFS), to address the Cross-Domain Few-Shot Learning (CD-FSL) challenge. The TMHFS method extends the Meta-Confidence Transduction (MCT) and Dense Feature-Matching Networks (DFMN) method [2] by introducing a new prediction head, i.e, an instance-wise global classification network based on semantic information, after the common feature embedding network. We train the embedding network with the multiple heads, i.e,, the MCT loss, the DFMN loss and the semantic classifier loss, simultaneously in the source domain. For the few-shot learning in the target domain, we first perform fine-tuning on the embedding network with only the semantic global classifier and the support instances, and then use the MCT part to predict labels of the query set with the fine-tuned embedding network. Moreover, we further exploit data augmentation techniques during the fine-tuning and test stages to improve the prediction performance. The experimental results demonstrate that the proposed methods greatly outperform the strong baseline, fine-tuning, on four different target domains.
Feature Transformation Ensemble Model with Batch Spectral Regularization for Cross-Domain Few-Shot Classification
May 21, 2020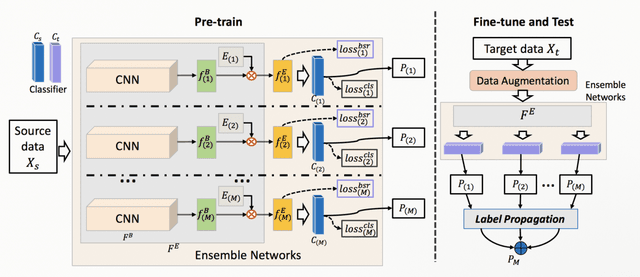
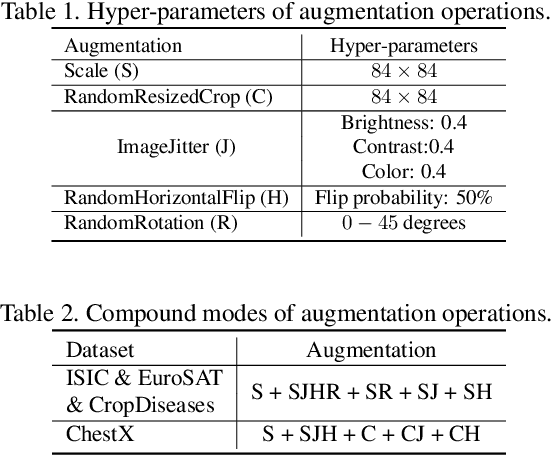
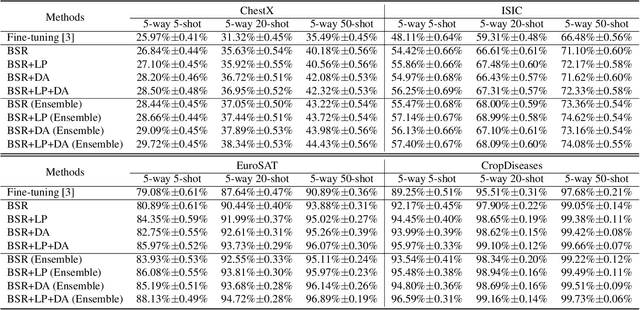
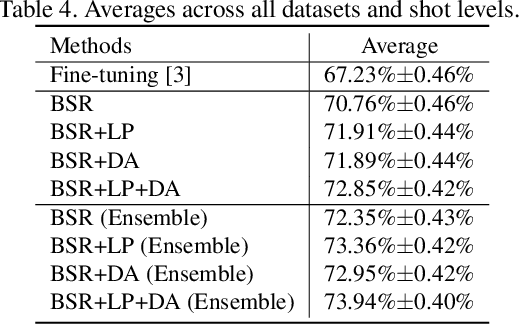
In this paper, we propose a feature transformation ensemble model with batch spectral regularization for the Cross-domain few-shot learning (CD-FSL) challenge. Specifically, we proposes to construct an ensemble prediction model by performing diverse feature transformations after a feature extraction network. On each branch prediction network of the model we use a batch spectral regularization term to suppress the singular values of the feature matrix during pre-training to improve the generalization ability of the model. The proposed model can then be fine tuned in the target domain to address few-shot classification. We also further apply label propagation, entropy minimization and data augmentation to mitigate the shortage of labeled data in target domains. Experiments are conducted on a number of CD-FSL benchmark tasks with four target domains and the results demonstrate the superiority of our proposed model.
High-speed Railway Fastener Detection and Localization Method based on convolutional neural network
Jul 31, 2019



Railway transportation is the artery of China's national economy and plays an important role in the development of today's society. Due to the late start of China's railway security inspection technology, the current railway security inspection tasks mainly rely on manual inspection, but the manual inspection efficiency is low, and a lot of manpower and material resources are needed. In this paper, we establish a steel rail fastener detection image dataset, which contains 4,000 rail fastener pictures about 4 types. We use the regional suggestion network to generate the region of interest, extracts the features using the convolutional neural network, and fuses the classifier into the detection network. With online hard sample mining to improve the accuracy of the model, we optimize the Faster RCNN detection framework by reducing the number of regions of interest. Finally, the model accuracy reaches 99% and the speed reaches 35FPS in the deployment environment of TITAN X GPU.