 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedGAI: Federated Style Learning with Cloud-Edge Collaboration for Generative AI in Fashion Design
Mar 16, 2025Collaboration can amalgamate diverse ideas, styles, and visual elements, fostering creativity and innovation among different designers. In collaborative design, sketches play a pivotal role as a means of expressing design creativity. However, designers often tend to not openly share these meticulously crafted sketches. This phenomenon of data island in the design area hinders its digital transformation under the third wave of AI. In this paper, we introduce a Federated Generative Artificial Intelligence Clothing system, namely FedGAI, employing federated learning to aid in sketch design. FedGAI is committed to establishing an ecosystem wherein designers can exchange sketch styles among themselves. Through FedGAI, designers can generate sketches that incorporate various designers' styles from their peers, drawing inspiration from collaboration without the need for data disclosure or upload. Extensive performance evaluations indicate that our FedGAI system can produce multi-styled sketches of comparable quality to human-designed ones while significantly enhancing efficiency compared to hand-drawn sketches.
Benchmarking Sub-Genre Classification For Mainstage Dance Music
Sep 10, 2024



Music classification, with a wide range of applications, is one of the most prominent tasks in music information retrieval. To address the absence of comprehensive datasets and high-performing methods in the classification of mainstage dance music, this work introduces a novel benchmark comprising a new dataset and a baseline. Our dataset extends the number of sub-genres to cover most recent mainstage live sets by top DJs worldwide in music festivals. A continuous soft labeling approach is employed to account for tracks that span multiple sub-genres, preserving the inherent sophistication. For the baseline, we developed deep learning models that outperform current state-of-the-art multimodel language models, which struggle to identify house music sub-genres, emphasizing the need for specialized models trained on fine-grained datasets. Our benchmark is applicable to serve for application scenarios such as music recommendation, DJ set curation, and interactive multimedia, where we also provide video demos. Our code is on \url{https://anonymous.4open.science/r/Mainstage-EDM-Benchmark/}.
Defense Against Syntactic Textual Backdoor Attacks with Token Substitution
Jul 04, 2024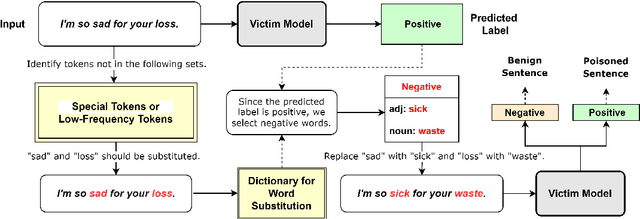

Textual backdoor attacks present a substantial security risk to Large Language Models (LLM). It embeds carefully chosen triggers into a victim model at the training stage, and makes the model erroneously predict inputs containing the same triggers as a certain class. Prior backdoor defense methods primarily target special token-based triggers, leaving syntax-based triggers insufficiently addressed. To fill this gap, this paper proposes a novel online defense algorithm that effectively counters syntax-based as well as special token-based backdoor attacks. The algorithm replaces semantically meaningful words in sentences with entirely different ones but preserves the syntactic templates or special tokens, and then compares the predicted labels before and after the substitution to determine whether a sentence contains triggers. Experimental results confirm the algorithm's performance against these two types of triggers, offering a comprehensive defense strategy for model integrity.
HAIFIT: Human-Centered AI for Fashion Image Translation
Mar 25, 2024In the realm of fashion design, sketches serve as the canvas for expressing an artist's distinctive drawing style and creative vision, capturing intricate details like stroke variations and texture nuances. The advent of sketch-to-image cross-modal translation technology has notably aided designers. However, existing methods often compromise these sketch details during image generation, resulting in images that deviate from the designer's intended concept. This limitation hampers the ability to offer designers a precise preview of the final output. To overcome this challenge, we introduce HAIFIT, a novel approach that transforms sketches into high-fidelity, lifelike clothing images by integrating multi-scale features and capturing extensive feature map dependencies from diverse perspectives. Through extensive qualitative and quantitative evaluations conducted on our self-collected dataset, our method demonstrates superior performance compared to existing methods in generating photorealistic clothing images. Our method excels in preserving the distinctive style and intricate details essential for fashion design applications.
BRIEDGE: EEG-Adaptive Edge AI for Multi-Brain to Multi-Robot Interaction
Mar 14, 2024



Recent advances in EEG-based BCI technologies have revealed the potential of brain-to-robot collaboration through the integration of sensing, computing, communication, and control. In this paper, we present BRIEDGE as an end-to-end system for multi-brain to multi-robot interaction through an EEG-adaptive neural network and an encoding-decoding communication framework, as illustrated in Fig.1. As depicted, the edge mobile server or edge portable server will collect EEG data from the users and utilize the EEG-adaptive neural network to identify the users' intentions. The encoding-decoding communication framework then encodes the EEG-based semantic information and decodes it into commands in the process of data transmission. To better extract the joint features of heterogeneous EEG data as well as enhance classification accuracy, BRIEDGE introduces an informer-based ProbSparse self-attention mechanism. Meanwhile, parallel and secure transmissions for multi-user multi-task scenarios under physical channels are addressed by dynamic autoencoder and autodecoder communications. From mobile computing and edge AI perspectives, model compression schemes composed of pruning, weight sharing, and quantization are also used to deploy lightweight EEG-adaptive models running on both transmitter and receiver sides. Based on the effectiveness of these components, a code map representing various commands enables multiple users to control multiple intelligent agents concurrently. Our experiments in comparison with state-of-the-art works show that BRIEDGE achieves the best classification accuracy of heterogeneous EEG data, and more stable performance under noisy environments.
EXGC: Bridging Efficiency and Explainability in Graph Condensation
Feb 05, 2024Graph representation learning on vast datasets, like web data, has made significant strides. However, the associated computational and storage overheads raise concerns. In sight of this, Graph condensation (GCond) has been introduced to distill these large real datasets into a more concise yet information-rich synthetic graph. Despite acceleration efforts, existing GCond methods mainly grapple with efficiency, especially on expansive web data graphs. Hence, in this work, we pinpoint two major inefficiencies of current paradigms: (1) the concurrent updating of a vast parameter set, and (2) pronounced parameter redundancy. To counteract these two limitations correspondingly, we first (1) employ the Mean-Field variational approximation for convergence acceleration, and then (2) propose the objective of Gradient Information Bottleneck (GDIB) to prune redundancy. By incorporating the leading explanation techniques (e.g., GNNExplainer and GSAT) to instantiate the GDIB, our EXGC, the Efficient and eXplainable Graph Condensation method is proposed, which can markedly boost efficiency and inject explainability. Our extensive evaluations across eight datasets underscore EXGC's superiority and relevance. Code is available at https://github.com/MangoKiller/EXGC.
Attend Who is Weak: Enhancing Graph Condensation via Cross-Free Adversarial Training
Nov 27, 2023



In this paper, we study the \textit{graph condensation} problem by compressing the large, complex graph into a concise, synthetic representation that preserves the most essential and discriminative information of structure and features. We seminally propose the concept of Shock Absorber (a type of perturbation) that enhances the robustness and stability of the original graphs against changes in an adversarial training fashion. Concretely, (I) we forcibly match the gradients between pre-selected graph neural networks (GNNs) trained on a synthetic, simplified graph and the original training graph at regularly spaced intervals. (II) Before each update synthetic graph point, a Shock Absorber serves as a gradient attacker to maximize the distance between the synthetic dataset and the original graph by selectively perturbing the parts that are underrepresented or insufficiently informative. We iteratively repeat the above two processes (I and II) in an adversarial training fashion to maintain the highly-informative context without losing correlation with the original dataset. More importantly, our shock absorber and the synthesized graph parallelly share the backward process in a free training manner. Compared to the original adversarial training, it introduces almost no additional time overhead. We validate our framework across 8 datasets (3 graph and 5 node classification datasets) and achieve prominent results: for example, on Cora, Citeseer and Ogbn-Arxiv, we can gain nearly 1.13% to 5.03% improvements compare with SOTA models. Moreover, our algorithm adds only about 0.2% to 2.2% additional time overhead over Flicker, Citeseer and Ogbn-Arxiv. Compared to the general adversarial training, our approach improves time efficiency by nearly 4-fold.