 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Yet Efficient: Towards Self-Supervised FG-SBIR with Unified Sample Feature Alignment
Jun 17, 2024Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) aims to minimize the distance between sketches and corresponding images in the embedding space. However, scalability is hindered by the growing complexity of solutions, mainly due to the abstract nature of fine-grained sketches. In this paper, we propose a simple yet efficient approach to narrow the gap between the two modes. It mainly facilitates unified mutual information sharing both intra- and inter-samples, rather than treating them as a single feature alignment problem between modalities. Specifically, our approach includes: (i) Employing dual weight-sharing networks to optimize alignment within sketch and image domain, which also effectively mitigates model learning saturation issues. (ii) Introducing an objective optimization function based on contrastive loss to enhance the model's ability to align features intra- and inter-samples. (iii) Presenting a learnable TRSM combined of self-attention and cross-attention to promote feature representations among tokens, further enhancing sample alignment in the embedding space. Our framework achieves excellent results on CNN- and ViT-based backbones. Extensive experiments demonstrate its superiority over existing methods. We also introduce Cloths-V1, the first professional fashion sketches and images dataset, utilized to validate our method and will be beneficial for other applications.
CityGPT: Towards Urban IoT Learning, Analysis and Interaction with Multi-Agent System
May 23, 2024



The spatiotemporal data generated by massive sensors in the Internet of Things (IoT) is extremely dynamic, heterogeneous, large scale and time-dependent. It poses great challenges (e.g. accuracy, reliability, and stability) in real-time analysis and decision making for different IoT applications. The complexity of IoT data prevents the common people from gaining a deeper understanding of it. Agentized systems help address the lack of data insight for the common people. We propose a generic framework, namely CityGPT, to facilitate the learning and analysis of IoT time series with an end-to-end paradigm. CityGPT employs three agents to accomplish the spatiotemporal analysis of IoT data. The requirement agent facilitates user inputs based on natural language. Then, the analysis tasks are decomposed into temporal and spatial analysis processes, completed by corresponding data analysis agents (temporal and spatial agents). Finally, the spatiotemporal fusion agent visualizes the system's analysis results by receiving analysis results from data analysis agents and invoking sub-visualization agents, and can provide corresponding textual descriptions based on user demands. To increase the insight for common people using our framework, we have agnentized the framework, facilitated by a large language model (LLM), to increase the data comprehensibility. Our evaluation results on real-world data with different time dependencies show that the CityGPT framework can guarantee robust performance in IoT computing.
HAIFIT: Human-Centered AI for Fashion Image Translation
Mar 25, 2024In the realm of fashion design, sketches serve as the canvas for expressing an artist's distinctive drawing style and creative vision, capturing intricate details like stroke variations and texture nuances. The advent of sketch-to-image cross-modal translation technology has notably aided designers. However, existing methods often compromise these sketch details during image generation, resulting in images that deviate from the designer's intended concept. This limitation hampers the ability to offer designers a precise preview of the final output. To overcome this challenge, we introduce HAIFIT, a novel approach that transforms sketches into high-fidelity, lifelike clothing images by integrating multi-scale features and capturing extensive feature map dependencies from diverse perspectives. Through extensive qualitative and quantitative evaluations conducted on our self-collected dataset, our method demonstrates superior performance compared to existing methods in generating photorealistic clothing images. Our method excels in preserving the distinctive style and intricate details essential for fashion design applications.
DeepBrain: Towards Personalized EEG Interaction through Attentional and Embedded LSTM Learning
Feb 06, 2020

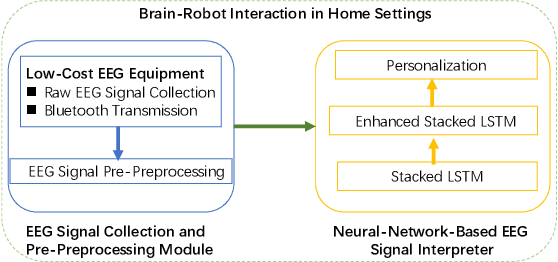
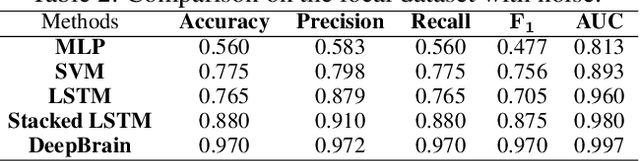
The "mind-controlling" capability has always been in mankind's fantasy. With the recent advancements of electroencephalograph (EEG) techniques, brain-computer interface (BCI) researchers have explored various solutions to allow individuals to perform various tasks using their minds. However, the commercial off-the-shelf devices to run accurate EGG signal collection are usually expensive and the comparably cheaper devices can only present coarse results, which prevents the practical application of these devices in domestic services. To tackle this challenge, we propose and develop an end-to-end solution that enables fine brain-robot interaction (BRI) through embedded learning of coarse EEG signals from the low-cost devices, namely DeepBrain, so that people having difficulty to move, such as the elderly, can mildly command and control a robot to perform some basic household tasks. Our contributions are two folds: 1) We present a stacked long short term memory (Stacked LSTM) structure with specific pre-processing techniques to handle the time-dependency of EEG signals and their classification. 2) We propose personalized design to capture multiple features and achieve accurate recognition of individual EEG signals by enhancing the signal interpretation of Stacked LSTM with attention mechanism. Our real-world experiments demonstrate that the proposed end-to-end solution with low cost can achieve satisfactory run-time speed, accuracy and energy-efficiency.